Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Tencent Youtu-LLM Makes a Major Debut: A 1.96B Small Model Unlocks Native Agent Capabilities, 128k Long Text, and 11T Data Revealed
In today’s large model race, people often assume that “emergent intelligence” is the exclusive domain of giant models with hundreds of billions of parameters. For models running on the edge with fewer than 2 billion parameters (sub-2B), the common industry approach is “distillation” — letting the small model imitate the outputs of a large model. But this method often only learns the surface, while making it hard to acquire real reasoning and planning abilities.
ArXiv URL:http://arxiv.org/abs/2512.24618v1
What if a small model were designed from birth to become an Agent?
Tencent Youtu Lab’s Youtu-LLM breaks this stereotype. This model, with only 1.96B parameters, does not rely on distillation. Instead, through systematic pre-training from scratch, it unlocks native Agent capabilities in a lightweight body. It not only supports a 128k ultra-long context, but also surpasses SOTA models of the same scale on multiple Agent benchmarks, and can even challenge much larger models.
This article will take you deep into the technical magic behind Youtu-LLM: how did it achieve a small-model comeback through a unique architecture design and a “curriculum-style” training regimen with as many as 11T Token?
1. Architecture Design: Even Lightweight Models Can “Take Long Exams”
For edge models, memory and compute efficiency are the top priorities, but Agent tasks also depend heavily on long context to maintain state and memory. How does Youtu-LLM balance this contradiction?
Dense Multi-Latent Attention
Youtu-LLM does not adopt the common Mixture of Experts (MoE) architecture, because in edge scenarios, MoE’s frequent I/O operations may actually slow things down. Instead, the study uses Dense Multi-Latent Attention (Dense Multi-Latent Attention, MLA).
MLA uses low-rank compression on the KV Cache and a larger intermediate projection matrix, greatly reducing memory usage while improving the expressive power of the attention mechanism. This allows Youtu-LLM to support a context window of up to 128k within a compact memory footprint.
A Tokenizer Customized for STEM
Beyond the architecture, the vocabulary is also key. Youtu-LLM redesigned a Tokenizer for STEM (science, technology, engineering, mathematics). Compared with Llama3’s tokenizer, the new design achieves a higher compression rate when processing code and mathematical formulas, which means sequences of the same length can carry more information density.
2. Training Strategy: The Path from Common Sense to Agent
Youtu-LLM’s core idea is: Agent capabilities should be injected during pre-training, not just through later fine-tuning. To this end, the research team built a massive corpus of up to 11T Tokens and designed a staged “curriculum.”
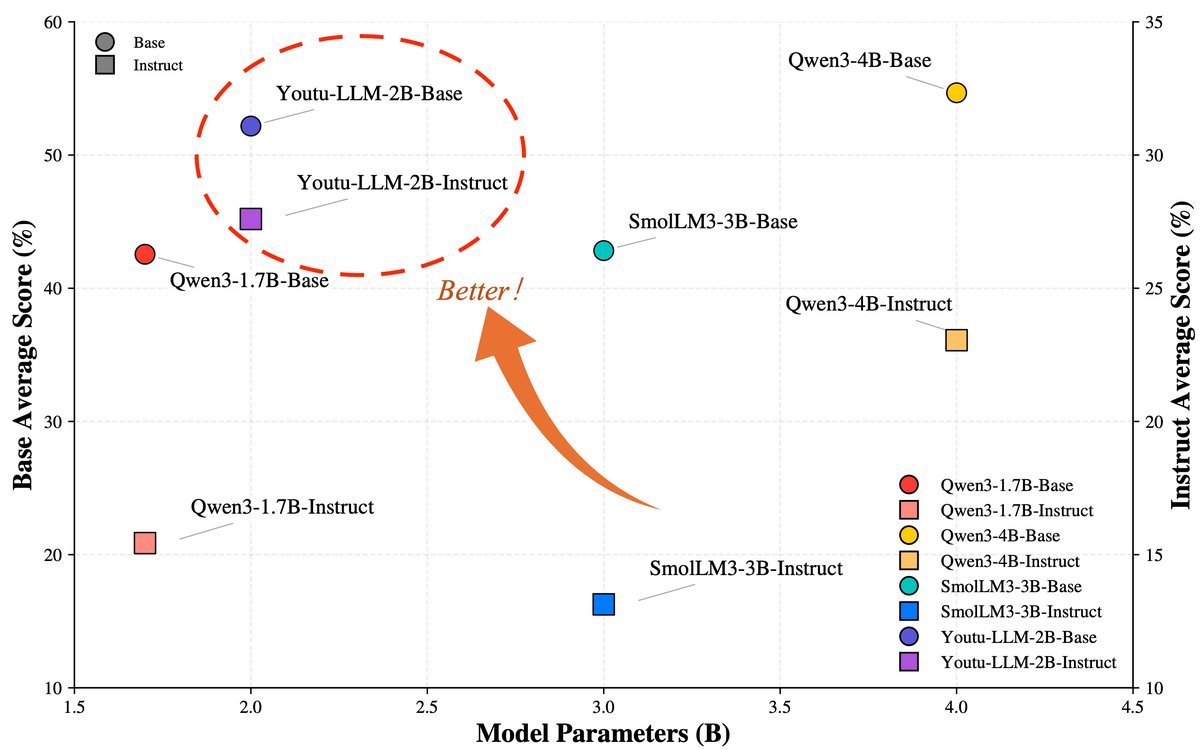
Figure 1: In Agent benchmarks, Youtu-LLM (red star) demonstrates astonishing performance at an extremely small parameter count, surpassing many peer models.
Multi-stage Pre-training
This is not just a pile-up of data, but a carefully tuned distribution:
-
General Foundation (Stage 1): Uses 8.16T data, mainly covering web pages and encyclopedic knowledge, laying the language foundation.
-
STEM Reinforcement (Stage 2): Greatly increases the proportion of STEM and code data to 60%, strengthening logical reasoning ability.
-
Long-text Extension (Stage 3): Gradually expands the context window from 8k to 128k, teaching the model to handle long-range dependencies.
-
Agent Special Training (Stage 4): This is the most critical step. In the final stage, the learning rate decays, and about 60% of the training data is replaced with high-quality Agent trajectory data.
3. The Core Secret: 200 Billion Tokens of Agent Trajectories
Why can Youtu-LLM plan and reflect like a human? The secret lies in its unique Agentic Mid-training stage. The research team synthesized about 200B Token of high-quality trajectory data, covering areas such as mathematics, code, deep research, and tool use.
This part of the data is no longer simple “question-answer” pairs, but includes the complete thinking process, tool calls, error reflection, and path correction.
Code Agent Trajectories: From Single Path to Branching
To help the model learn to write code and self-correct, the researchers designed a scalable synthetic framework (as shown in Figure 5).
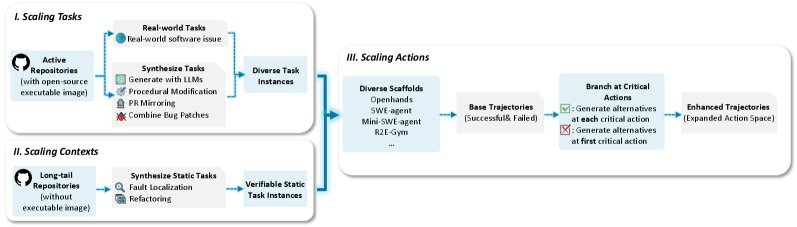
Figure 2: Code trajectory synthesis pipeline. By expanding tasks, context, and action branches, rich execution paths are constructed.
This framework not only generates successful code paths, but also preserves failed attempts and correction processes through a Branching Strategy. This means that during training, the model does not just see the “correct answer”; it also sees “how to recover from mistakes,” which is crucial for real-world Agents.
Deep Research: Dual Synthesis with Forward and Reverse Paths
In open-ended deep research tasks, the Agent needs to consulta large amount of material and generate reports. Youtu-LLM adopts a two-pronged data synthesis strategy:
-
Forward synthesis: Simulates the real research workflow — planning, searching, reading, summarizing.
-
Reverse synthesis: This is a clever innovation (as shown in Figure 8). The researchers start from high-quality academic papers or legal documents and use citation relationships to reconstruct search paths in reverse. If this paper cites reference A, then the search process should point to reference A. This method ensures the authenticity and authority of the search trajectory.
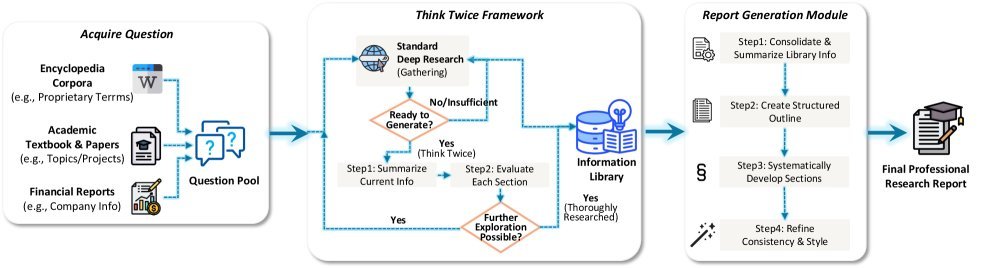
Figure 3: Trajectory synthesis pipeline for open-ended deep research report generation.
4. Experimental Results: Small Body, Big Brain
On general benchmarks, Youtu-LLM shows balanced strength. In its core Agent domain, the advantage is especially clear.
-
General capability: On leaderboards such as MMLU and GSM8K, Youtu-LLM goes head-to-head with excellent models like Qwen2.5-1.5B, holding its own in the top tier.
-
Agent capability: In tests involving tool use and complex planning, Youtu-LLM significantly outperforms existing sub-2B models, and on some metrics can even compete with models with far more parameters.
Summary
The emergence of Youtu-LLM proves an important conclusion to the community: the Agent capabilities of lightweight models do not have to rely on clumsy imitation of large models.
With the efficient long-context support brought by the Dense MLA architecture, combined with a staged curriculum of 11T Tokens, and especially the introduction of large-scale synthetic Agent trajectory data for pre-training, a small model can fully internalize powerful planning, reflection, and execution abilities. For developers who want to deploy intelligent Agents on edge devices and mobile applications, Youtu-LLM undoubtedly offers an exciting new option.