xLLM Technical Report
-
ArXiv URL: http://arxiv.org/abs/2510.14686v1
-
Author: Weizhe Huang; Liangyu Liu; Guyue Liu; Jun Zhang; Ziyue Wang; Yunlong Wang; Ke Zhang; Hailong Yang; Keyang Zheng; Yifan Wang; and 35 others
-
Publishing Organization: BUAA; JD.com; Peking University; Tsinghua University; USTC
TL;DR
This paper proposes an intelligent and efficient large language model inference framework called xLLM. It adopts an innovative service-engine decoupled architecture and, through intelligent scheduling and system-level collaborative optimization, is designed specifically for high-performance, large-scale enterprise services, addressing core challenges such as mixed workloads, low resource utilization, and poor hardware adaptability.
Key Definitions
This paper introduces or deeply applies the following core concepts:
- PD Disaggregation (Prefill-Decode Disaggregation): An inference architecture that assigns the computational tasks of processing prompts (the Prefill stage) and generating tokens (the Decode stage) to different instance groups, avoiding long-running Prefill tasks from blocking latency-sensitive Decode tasks and thereby optimizing overall performance.
- Dynamic PD Disaggregation: An adaptive scheduling strategy proposed in this paper. Instead of statically partitioning Prefill and Decode instances, it dynamically adjusts the ratio of instances handling Prefill and Decode tasks based on real-time workloads (such as request queues and TTFT/TPOT metrics), and supports rapid role switching between instances to handle traffic fluctuations.
- EPD Disaggregation (Encode-Prefill-Decode Disaggregation): An innovative disaggregation strategy designed specifically for multimodal requests. It breaks down the processing of multimodal inputs into three independent stages: encoding (Encode), prefill (Prefill), and decode (Decode), and intelligently selects the optimal combined or disaggregated execution mode based on performance analysis results (such as EP-D, ED-P, E-P-D) to achieve the best balance between throughput and latency.
- xTensor Memory Management: An innovative KV Cache management scheme whose core idea is “logically contiguous, physically disjoint.” It allocates physically disjoint memory pages on demand for each request to store the KV Cache while maintaining logical continuity, thereby resolving the conflict between dynamic memory allocation requirements and efficient memory access.
- Online-Offline Co-location: A scheduling strategy that deploys latency-sensitive online inference tasks and non-real-time offline batch tasks in a shared resource pool. By allowing online tasks to preempt resources and offline tasks to use idle resources, it maximizes overall cluster resource utilization.
Related Work
Current mainstream large language model inference frameworks face severe challenges in enterprise service scenarios.
- Service-level challenges:
- Low efficiency in handling mixed workloads: Existing scheduling systems struggle to effectively use idle resources during traffic troughs to process offline tasks while still ensuring online service SLOs (service-level objectives), resulting in low cluster resource utilization.
- Inflexible static resource allocation: Traditional PD disaggregation architectures usually configure resources statically and cannot adapt to the dynamic and drastic changes in request workloads in real applications (such as input and output lengths), leading to low hardware utilization and increased risk of SLO violations.
- Insufficient support for multimodal requests: There is a lack of efficient service strategies for multimodal inputs (such as images and text), especially for parallel processing in the Encode stage and fine-grained resource allocation.
- Poor stability in large-scale clusters: As cluster size grows, how to achieve rapid node failure detection and service recovery to ensure high availability of inference services becomes a key issue.
- Engine-level challenges:
- Insufficient hardware compute utilization: Existing inference engines struggle to fully exploit the performance of the compute units in modern AI accelerators.
- Limited scalability of MoE models: The All-to-All communication overhead and expert load imbalance in Mixture-of-Experts (MoE) models limit the system’s inference scalability.
- KV Cache management bottlenecks: As model context windows continue to grow, efficient KV Cache management becomes critical to performance.
- Imbalanced data-parallel workloads: In data-parallel (DP) deployments, the unpredictability of requests makes it difficult for static scheduling strategies to effectively balance the load across compute units.
The xLLM framework proposed in this paper aims to systematically address the above service-level and engine-level challenges, enabling efficient, intelligent, and reliable enterprise LLM inference services.
Method
The core design of the xLLM framework is a service-engine decoupled design. xLLM-Service is responsible for intelligent scheduling and resource management, while xLLM-Engine is responsible for efficiently executing inference computations.
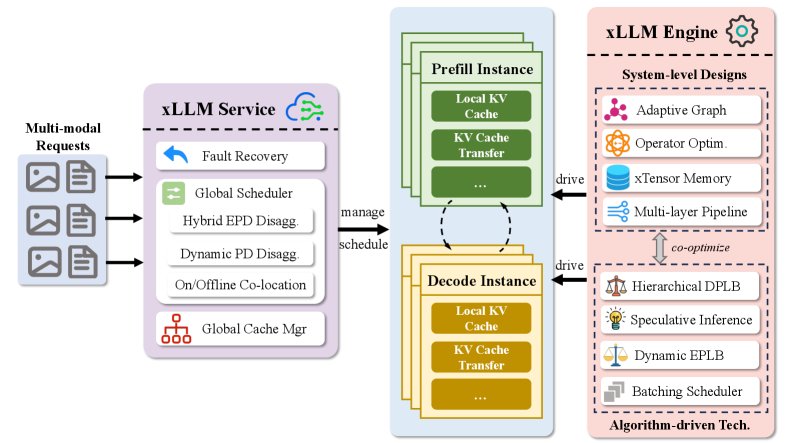
xLLM-Service
xLLM-Service is designed to achieve efficient, elastic, and highly available request scheduling and resource management. Its workflow is shown in the figure below and mainly includes request preprocessing, intelligent scheduling, and the resource layer.
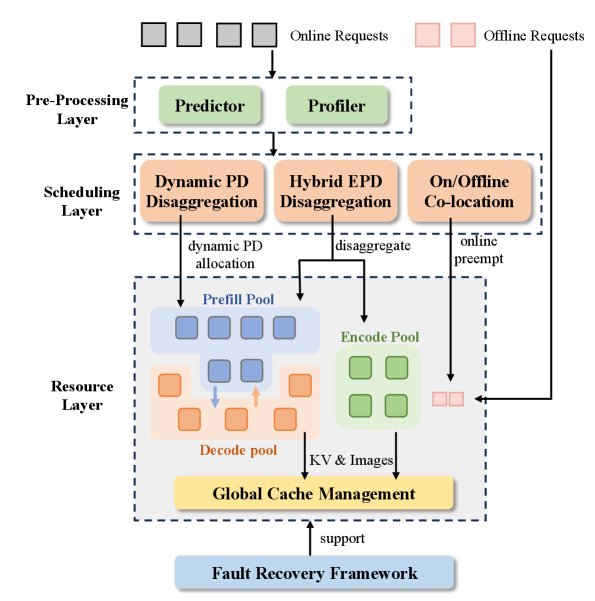
Its main innovations include:
Elastic Instance Pools
Instances in the cluster are divided into three elastic logical pools: the Prefill pool, the Decode pool, and the Encode pool designed for multimodal workloads. The instances themselves are stateless and can flexibly switch between different roles (such as handling Prefill or Decode tasks) according to the type of request being processed, without physical migration or restart, enabling dynamic resource scheduling.
Intelligent Scheduling Policies
The scheduling layer includes three core policies to address different scenarios:
-
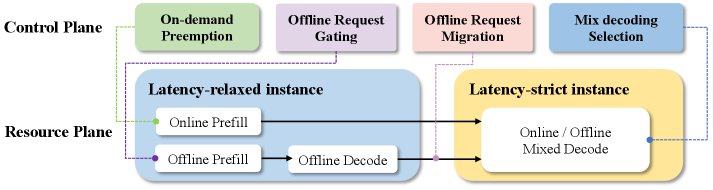
Online-Offline Co-location Policy: This policy adopts preemptive scheduling. Online requests have high priority and can preempt the resources of offline tasks during traffic peaks. During traffic troughs, offline tasks fully utilize idle resources. In particular, this paper proposes a latency-constrained decoupled architecture, which allows the Decode stage of offline tasks to run in either the Prefill pool or the Decode pool, balancing the load between the two types of pools through flexible scheduling and maximizing cluster utilization.
-
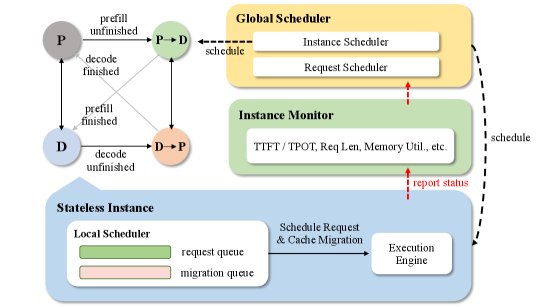
Dynamic PD Disaggregation Policy: To address the inefficiency of static PD disaggregation, this policy introduces real-time monitoring and adaptive adjustment mechanisms. It monitors performance metrics such as TTFT (time to first token) and TPOT (time per output token), and combines them with a TTFT predictor to dynamically assess the load of the Prefill and Decode stages. When a bottleneck is detected (for example, TTFT failing to meet the SLO), it triggers role switching for instances, such as temporarily converting some Decode instances into Prefill instances, and vice versa. This “zero-wait” role switching based on stateless instances avoids the high latency caused by restarting instances in traditional approaches.
-
Hybrid EPD Disaggregation Policy: For multimodal requests, this policy first uses an EPD profiler to search offline for the optimal stage-disaggregation configuration (for example, whether to merge Encode and Prefill or to fully separate all three stages). Then, the scheduler dispatches tasks to the corresponding instance pools according to this configuration. This design allows multimodal requests to also benefit from the elastic scheduling capabilities of dynamic PD disaggregation.
Other Key Designs
- KV-centric Storage Architecture: A hybrid HBM-DRAM-SSD storage architecture is used to cache KV values and image tokens. At the global level, KV Cache routing and reuse across instances are implemented, thereby expanding KV cache capacity and improving hit rates.
- Efficient Fault-tolerant: The framework supports fault detection and rapid recovery for the three types of instance pools: E, P, and D. For requests on failed instances, the system can automatically determine the optimal KV Cache recomputation or migration strategy, ensuring high service availability.
xLLM-Engine
xLLM-Engine is responsible for executing the actual inference computations, fully squeezing hardware performance through coordinated system-level and algorithm-level optimizations.
System-level Optimizations
- Multi-layer Pipeline Execution Engine:
- Framework Layer: By asynchronously scheduling CPU tasks and AI accelerator computations, a pipeline is formed to reduce compute bubbles.
- Model Graph Layer: A single batch is split into micro-batches, and a dual-stream parallel mechanism is used to overlap computation and communication.
- Operator Layer: Pipeline operations are implemented across different compute units so that computation and memory access overlap.
- Graph Optimization for Dynamic Inputs: Multiple small kernels in the decoding stage are fused into a unified computation graph, and one-time dispatch is used to greatly reduce operator launch overhead. At the same time, parameterized input dimensions and a multi-graph caching scheme are used to adapt to dynamically changing sequence lengths and batch sizes.
- xTensor Memory Management: A KV storage structure with “logically contiguous, physically discrete” design is adopted. During token generation, physical memory pages are allocated on demand, while the physical pages required for the next token are asynchronously predicted and intelligently mapped. After a request ends, physical memory is immediately reused, effectively solving memory fragmentation and allocation contention issues.
Algorithm-level Optimizations
- Speculative Decoding: The speculative decoding algorithm is integrated and optimized to improve throughput by generating multiple tokens at once. Architecturally, it is further optimized through asynchronous CPU processing and reduced data transfer.
- EP Load Balance: For MoE models, expert weights are dynamically updated based on historical expert load statistics, enabling effective dynamic load balancing during inference.
- DP Load Balance: In data-parallel deployments, fine-grained load balancing is achieved through KV Cache-aware instance allocation, request migration across DP instances, and allocation of compute units within DP.
Experimental Conclusions
- Significant Performance Advantage: Under the same TPOT (time per output token) constraint, xLLM achieves throughput up to 1.7x that of MindIE and 2.2x that of vLLM-Ascend on the Qwen series models. On the Deepseek series models, its average throughput is 1.7x that of MindIE.
- Scenario Optimization Results: For one of JD’s core businesses—generative recommendation—xLLM delivers a 23% performance improvement through specific optimizations such as host-operator overlap.
- Final Conclusion: Extensive evaluation results demonstrate that xLLM shows significant superiority in both performance and resource efficiency. The framework has been successfully deployed internally at JD, supporting a range of core business scenarios such as AI chatbots, marketing recommendations, product understanding, and customer service assistants, validating its effectiveness and stability in large-scale enterprise applications.