WizardCoder: Empowering Code Large Language Models with Evol-Instruct
-
ArXiv URL: http://arxiv.org/abs/2306.08568v2
-
Authors: Daxin Jiang; Ziyang Luo; Can Xu; Wenxiang Hu; Qingwei Lin; Jing Ma; Qingfeng Sun; Pu Zhao; Chongyang Tao; Xiubo Geng
-
Affiliation: Hong Kong Baptist University; Microsoft
TL;DR
This paper proposes a method called \(Code Evol-Instruct\), which automatically evolves and enhances the complexity of programming instructions to fine-tune code large language models, thereby creating the \(WizardCoder\) model family with outstanding performance on multiple benchmarks.
Key Definitions
The core of this paper revolves around the new method \(Code Evol-Instruct\), which gives rise to the \(WizardCoder\) models.
-
Code Evol-Instruct: An instruction-evolution method specifically designed for the code domain. It draws inspiration from the general-domain \(Evol-Instruct\), but is deeply customized for programming tasks. Using a powerful “evolution execution model” (such as GPT-3.5), it automatically rewrites a simple initial code instruction (for example, a programming problem) into a more complex, deeper, and more challenging version according to a set of carefully designed heuristic rules.
-
WizardCoder: A new model family obtained by instruction fine-tuning existing open-source code large language models (such as StarCoder and CodeLlama) on a high-complexity instruction dataset generated by \(Code Evol-Instruct\). The models released in this paper include \(WizardCoder-15B\) and \(WizardCoder-34B\).
Related Work
-
Current State: At present, large code language models (Code Large Language Models, Code LLMs), such as StarCoder and CodeLlama, have achieved remarkable success in code understanding and generation tasks. However, compared with general large language models (LLMs), instruction fine-tuning techniques in the code domain remain underexplored. As a result, the strongest existing open-source code models still lag significantly behind top closed-source models (such as GPT-4 and Claude) in performance.
-
Problem to Solve: This paper aims to address a core question: how to effectively improve the performance of open-source code large language models through instruction fine-tuning, thereby narrowing the gap with closed-source models. The authors argue that existing instruction datasets (such as Code Alpaca) lack sufficient instruction complexity and fail to fully unlock the potential of the base model. Therefore, the goal of this paper is to create a method that can automatically generate more complex and diverse code instructions, so as to train code models more effectively.
Method
The core contribution of this paper is the \(Code Evol-Instruct\) method, which improves the quality of code instructions through iterative evolution and uses the resulting data to train the \(WizardCoder\) models.
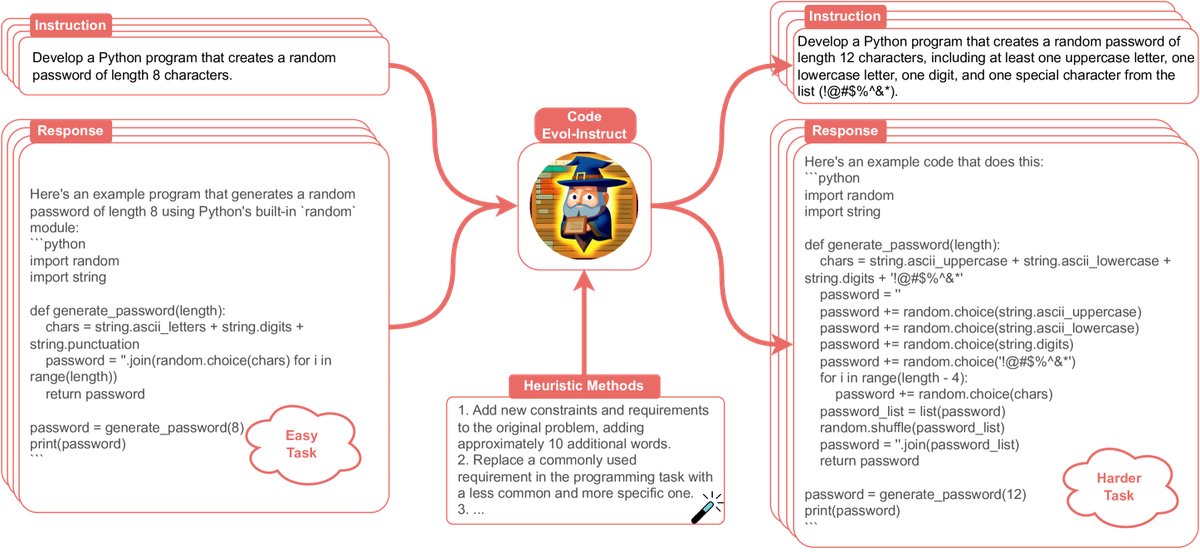 Caption: Illustration of the Code Evol-Instruct method.
Caption: Illustration of the Code Evol-Instruct method.
Method Pipeline
The entire pipeline consists of two steps:
- Instruction Evolution: First, a basic code instruction dataset (Code Alpaca in this paper) is used as the seed. Then, \(Code Evol-Instruct\) is applied to iteratively evolve these instructions.
- Model Fine-Tuning: The evolved high-complexity instruction dataset is used to fine-tune pretrained open-source code large language models (such as StarCoder and CodeLlama), ultimately producing the \(WizardCoder\) models.
Innovation: The Design of Code Evol-Instruct
The innovation of \(Code Evol-Instruct\) lies in its evolution strategy, which is specifically designed for code tasks. It uses a specific prompt template to drive a large language model (such as GPT-3.5) to increase instruction difficulty.
Evolution Prompt Template: ``\(Please increase the difficulty of the given programming test question a bit. You can increase the difficulty using, but not limited to, the following methods: {method} {question}\)`\(Here,\){question}\(is the original instruction to be evolved, and\){method}$$ is one of the following five specially designed code evolution heuristics, selected at random:
- Add constraints: Add new constraints and requirements to the original problem (about 10 more words).
- Replace requirements: Replace a commonly used requirement in a programming task with a less common and more specific one.
- Deepen reasoning: If the original problem can be solved with only a few logical steps, add more reasoning steps.
- Introduce misleading information: Provide a piece of incorrect code as reference to increase confusion (an adversarial sample idea).
- Increase complexity requirements: Propose higher time or space complexity requirements (but do not use this frequently).
Training Process
The training dataset is built starting from the Code Alpaca dataset. Through multiple rounds of iterative evolution with \(Code Evol-Instruct\), the data generated in each round is merged with all previous rounds of data and the original data for model fine-tuning. During training, an external development set is used to determine when to stop evolution (Evol Stop) to prevent performance degradation.
Fine-tuning prompt format: \(`\) Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
Instruction:
{instruction}
Response:
\(`\)
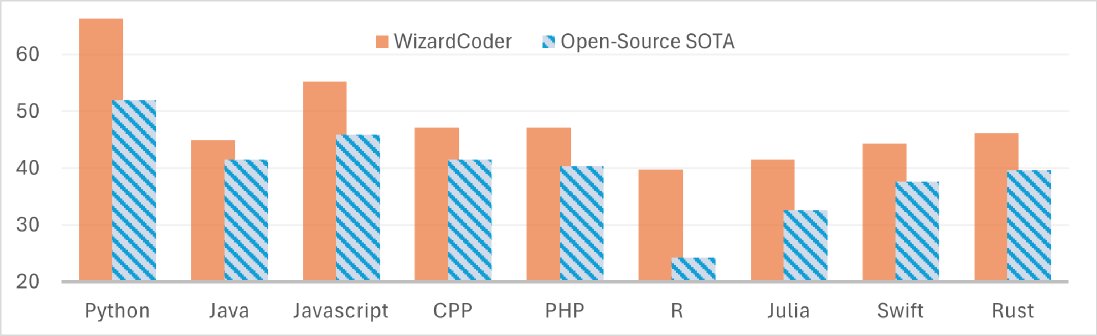 Caption: WizardCoder-34B shows a significant advantage over the then state-of-the-art open-source model (the CodeLlama-34B series) across multiple programming languages.
Caption: WizardCoder-34B shows a significant advantage over the then state-of-the-art open-source model (the CodeLlama-34B series) across multiple programming languages.
Experimental Conclusions
This paper conducts a comprehensive evaluation on five major code generation benchmarks: HumanEval, HumanEval+, MBPP, DS-1000, and MultiPL-E. The experimental results fully validate the outstanding performance of \(WizardCoder\).
Key Experimental Results
-
Surpassing open-source models: On all five benchmarks, the \(WizardCoder\) series models (15B and 34B) significantly outperform all other open-source code large language models, becoming the new open-source SOTA.
-
Comparable to or even surpassing closed-source models:
- \(WizardCoder-15B\) achieves \(pass@1\) scores on HumanEval and HumanEval+ that exceed those of the well-known closed-source models Anthropic Claude and Google Bard.
- \(WizardCoder-34B\) matches GPT-3.5 (ChatGPT) on HumanEval, and surpasses GPT-3.5 on HumanEval+, which includes more comprehensive test cases.
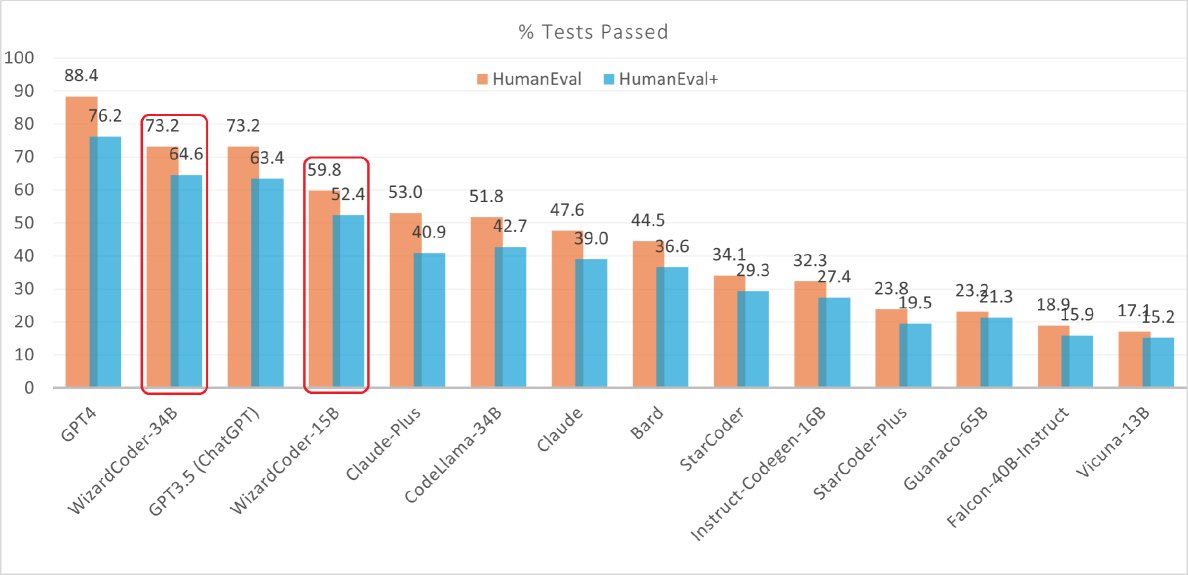 Caption: On the EvalPlus leaderboard, WizardCoder-34B performs better than GPT-3.5 on HumanEval+, second only to GPT-4.
Caption: On the EvalPlus leaderboard, WizardCoder-34B performs better than GPT-3.5 on HumanEval+, second only to GPT-4.
- Multilingual and domain-specific capabilities:
- On the MultiPL-E benchmark, \(WizardCoder\) achieved the strongest performance across 8 different programming languages, such as Java, C++, and Rust.
- On the data science benchmark DS-1000, \(WizardCoder-15B\) also significantly outperformed other models on the code insertion task.
| Model | Parameters | HumanEval | MBPP |
|---|---|---|---|
| Closed-source models | |||
| GPT-3.5 (ChatGPT) | Unknown | 48.1 | 52.2 |
| GPT-4 | Unknown | 67.0 | - |
| Open-source models | |||
| StarCoder-15B | 15B | 33.6 | 43.6* |
| CodeLlama-Python-34B | 34B | 53.7 | 56.2 |
| WizardCoder (this paper) | 15B | 57.3 | 51.8 |
| WizardCoder (this paper) | 34B | 71.5 | 61.2 |
Table note: Comparison of pass@1 (%) results on the HumanEval and MBPP benchmarks.
In-depth Analysis and Conclusions
-
Source of performance gains: Analysis experiments show that the performance improvement indeed comes from increased instruction complexity, rather than simply from more samples or more tokens. When sample or token counts are controlled to be equal, models trained on evolved data far outperform those trained on the original data.
-
Unrelated to similarity with the test set: Analysis shows that the evolution process did not increase the similarity between the training data and the test set (HumanEval). This rules out the possibility of “data leakage” or “overfitting to the test set,” proving a real improvement in the model’s generalization ability.
-
Effect of the number of evolution rounds: Experiments found that more evolution is not always better. Performance typically peaks after about 3 rounds of evolution, then levels off or declines slightly.
-
Final conclusion: \(Code Evol-Instruct\) is an extremely effective instruction fine-tuning method. By increasing instruction complexity, it successfully raised the performance of open-source code models to a new level. Although there is still a gap with GPT-4, $$WizardCoder` significantly narrows the divide between open-source models and top-tier closed-source models.