Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention
-
ArXiv URL: http://arxiv.org/abs/2510.04212v1
-
Author: Haiquan Qiu; Quanming Yao
-
Publishing Institution: Tsinghua University
TL;DR
This paper is the first to systematically reveal the underlying mechanism that causes training collapse when using Flash Attention for low-precision (BF16) Transformer model training. It shows that the root cause lies in the cumulative effect of similar low-rank representations in the attention mechanism and the inherent biased rounding error of BF16 arithmetic. Together, these form a vicious cycle that ultimately leads to loss explosion.
Key Definitions
This paper mainly follows existing concepts and provides an in-depth analysis of the following terms, which are crucial for understanding the paper:
-
bfloat16 (BF16): A 16-bit floating-point format with 1 sign bit, 8 exponent bits, and 7 significand bits. It has the same dynamic range as 32-bit single precision (FP32) but lower precision. The key point of this paper is to reveal that, under specific data distributions, BF16 rounding operations (usually “round to nearest even”) can produce biased rounding error, meaning the error accumulates persistently in one direction rather than canceling out randomly.
-
Flash Attention (FA): An I/O-aware exact attention algorithm that reduces the memory complexity of attention from $O(N^2)$ with respect to sequence length $N$ to $O(N)$ through tiled computation. The analysis in this paper focuses on a key intermediate term \(δ\) in FA backpropagation, computed as \(δ = rowsum(dO ◦ O)\), and finds that this computation is the main source of numerical instability under BF16 precision.
Related Work
At present, training larger-scale Transformer models relies on low-precision computation (such as BF16 and FP8) to improve efficiency. Flash Attention has become a cornerstone for training large models because it can handle long sequences efficiently. However, a long-standing and unresolved bottleneck is that when Flash Attention is used in low-precision settings, especially BF16, training often fails abruptly due to catastrophic loss explosion.
Although the community has proposed some empirical fixes, such as QK normalization, QK-clip, and Gated Attention, these methods are more like “band-aids” and do not fundamentally explain why the failure occurs. The current state of research lacks a clear causal chain from numerical error to training collapse.
This paper aims to address this specific problem: to provide the first mechanism-level explanation for Flash Attention training failure under BF16 precision, and based on that, propose a principled solution rather than relying on temporary empirical fixes.
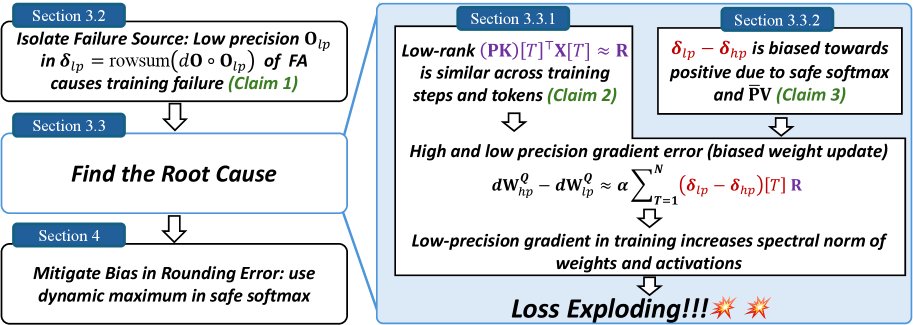
Method
The core “method” of this paper is not to propose a brand-new model, but rather a rigorous reverse-engineering process that peels back the layers step by step and ultimately identifies and validates the root cause of low-precision training failure.
Reproducing and Locating the Source of Failure
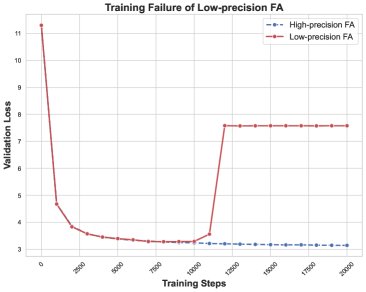
First, the paper stably reproduces the training failure reported by the community on a GPT-2 model: after thousands of steps of training with BF16 and Flash Attention, the loss suddenly explodes. To ensure determinism in the analysis, a fixed data batch order is used.
Through a series of isolation experiments, the paper gradually narrows down the problem:
- Rule out tiled computation: Even when Flash Attention’s tiling strategy is disabled, the problem still persists, indicating that the failure is unrelated to tiling.
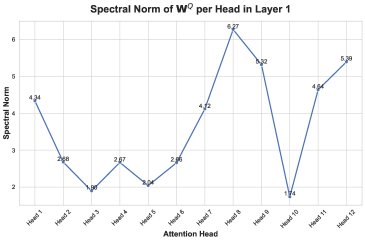
- Pinpoint the specific layer and module: By monitoring the spectral norms of the weight matrices in each layer, the anomaly is found to be concentrated mainly in the attention module of the second layer. Using Flash Attention only in this layer is enough to reproduce the failure, while replacing only this layer with standard attention allows training to remain stable.
- Lock onto the key computation step: In Flash Attention backpropagation, the computation of a key intermediate term \(δ\) is identified as the problem. The standard computation of \(δ\) is \(δ = rowsum(dO ◦ O)\). Experiments show that if one switches to a mathematically equivalent but numerically more stable computation, or temporarily recomputes the forward output \(O\) in FP32 precision when calculating \(δ\), training becomes stable again. This strongly demonstrates that numerical errors in the output matrix \(O\) computed under BF16 precision are the direct cause of failure.
- Refine to a specific attention head: Further analysis shows that the failure is mainly caused by the abnormal growth of the spectral norms of a few attention heads, especially the 8th head. Subsequent analysis therefore focuses on this most unstable head.
Revealing the Root Cause: A Vicious Cycle Between Two Major Factors
The analysis in this paper reveals that training failure is caused by a vicious cycle formed by the interaction of two interrelated factors.
Cause 1: Similar low-rank matrices and biased coefficients lead to biased weight updates
The source of the gradient error is traced to the gradient difference of the query weight matrix \(W^Q\), namely \(dW^Q_hp - dW^Q_lp\). This difference can be expressed as:
\[d{\mathbf{W}}^{Q}_{hp}-d{\mathbf{W}}^{Q}_{lp} = \alpha\sum_{T=1}^{N}({\mathbf{\delta}}_{lp}-{\mathbf{\delta}}_{hp})[T]\cdot({\mathbf{P}}{\mathbf{K}})[T]^{\top}{\mathbf{X}}[T]\]where \(δ_lp - δ_hp\) is the difference between the \(δ\) vectors computed in low precision and high precision, \(P\) is the attention probability matrix, \(K\) is the key matrix, and \(X\) is the input features. This formula shows that the total gradient error is a weighted sum of N rank-1 matrices, with the weights given by the error term in \(δ\).
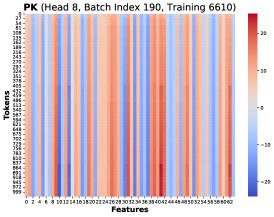
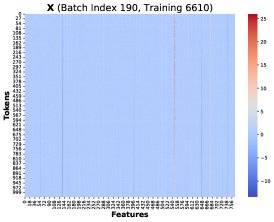
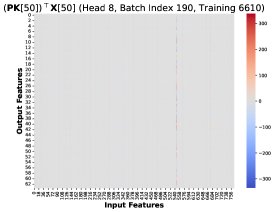
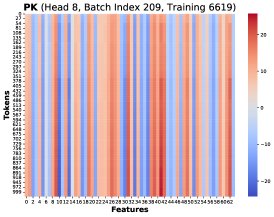
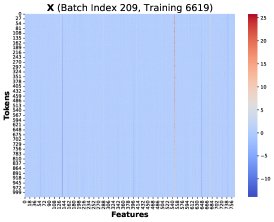
Core Finding 1: Through visualization, the paper finds that at different training steps and different Token positions \(T\), these rank-1 matrices \((PK)[T]^T X[T]\) share a highly similar structure. Therefore, the total gradient error can be approximated as a common low-rank structure \(R\) multiplied by a scalar coefficient:
\[d{\mathbf{W}}^{Q}_{hp}-d{\mathbf{W}}^{Q}_{lp} \approx \alpha\left(\sum_{T=1}^{N}({\mathbf{\delta}}_{lp}-{\mathbf{\delta}}_{hp})[T]\right) {\mathbf{R}}\]Core Finding 2: By tracking the cumulative sum of the coefficient \(Σ(δ_lp - δ_hp)[T]\), the paper finds that it remains consistently positive before training collapse, showing a clear positive bias.
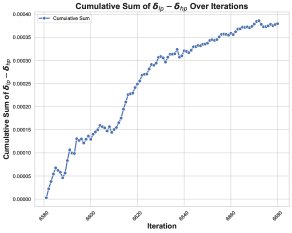
Together, these two findings reveal the first link in the failure chain: because the coefficient stays positive, the similar low-rank error \(R\) keeps accumulating across training steps instead of canceling out randomly. This cumulative error contaminates the weight updates, causing the spectral norm of the weights and the activation values to grow abnormally, and eventually collapsing the training dynamics.
Cause 2: Biased rounding error makes the coefficient \((δ_lp - δ_hp)[T]\) positive
Next, the paper investigates why the coefficient \((δ_lp - δ_hp)[T]\) stays positive. The error in \(δ\), namely \(δ_lp - δ_hp\), mainly comes from the elementwise product of \(dO\) and \(O_lp - O_hp\). The analysis shows that on some key feature dimensions, the values of \(dO\) and the computation error of \(O\), \(O_lp - O_hp\), tend to be negative at the same time, making their product positive and thus contributing a positive \(δ\) error.
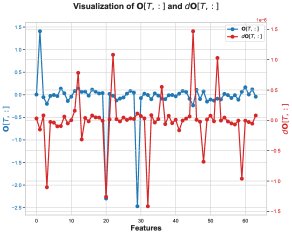
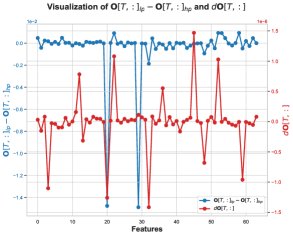
The error term \(O_lp - O_hp\) for \(O\) is negative, which means the BF16-computed output \(O_lp\) is systematically biased toward values that are more negative than the FP32 result \(O_hp\). The paper traces this bias to an intermediate step in the computation of \(O\): the matrix multiplication for the unnormalized output \(Ō = P̄V\).
Core Finding 3: In this matrix multiplication, numerical errors mainly occur at positions where the attention probability \(P̄[T, t]\) is exactly 1. This usually happens when one of the scores before softmax is the maximum value in that row. When \(P̄[T, t] = 1\), the computation of \(P̄V\) simplifies to summing certain rows of the \(V\) matrix.
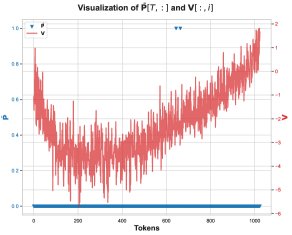
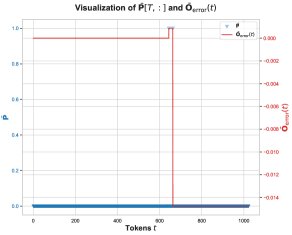
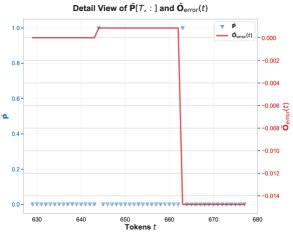
Core Finding 4: On the problematic feature dimensions, the values in the \(V\) matrix are overwhelmingly negative. Therefore, when accumulating these predominantly negative BF16 values, the BF16 rounding mechanism produces a biased rounding error, making the accumulated sum systematically more negative than the true value. This explains why \(O_lp\) tends to be more negative.
Solution
Based on the above analysis, the paper proposes a very simple fix: in the Flash Attention implementation, make a small modification to mitigate the biased rounding error in the computation of \(Ō = P̄V\). Although the paper does not spell out the exact code changes, it suggests that this may be achieved by changing the accumulation order or by using higher precision in key accumulation steps. This simple change successfully stabilizes the training process that would otherwise fail.
Experimental Conclusions
The paper’s experimental conclusions are mainly reflected in its analysis and validation process:
- Advantage Validation: The minimalist modification proposed in this article successfully resolves the BF16 Flash Attention training failure issue that has long troubled the community. This success itself is strong evidence for the correctness of its causal analysis. The experiments show that the training failure is not a random event, but a deterministic process jointly determined by the underlying numerical computation mechanism and the data/model state.
- Effect: This method precisely addresses the specific training instability issue it targets. By solving the root cause (biased rounding error), it provides a more principled solution than temporary fixes such as QK clipping.
- Final Conclusion: The training failure of Transformer under low precision (BF16) and Flash Attention stems from a clear causal chain:
- The values in specific dimensions of the \(V\) matrix exhibit a biased distribution (for example, mostly negative).
- When computing \(Ō = P̄V\), BF16 accumulation operations produce biased rounding error on these biased values, causing \(Ō_lp\) to systematically deviate from \(Ō_hp\).
- This bias propagates to \(O_lp\), making the sign of the computation error \(O_lp - O_hp\) consistently correlated with the upstream gradient \(dO\), thereby causing the error term \((δ_lp - δ_hp)\) to remain consistently positive.
- At the same time, the model’s weights and inputs evolve into similar low-rank structures \(R\) across different training steps.
- Ultimately, the positive coefficients combined with the similar low-rank error structure cause the gradient error to continuously accumulate over multiple training steps, contaminating the weights, causing their spectral norm to explode, and ultimately destroying the entire training process.
The analysis in this article not only explains the problem, but the proposed fix also provides important practical guidance for achieving more robust and efficient low-precision large model training.