When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models
Is Less More? 8-bit Quantization Actually Boosts Large Models’ Continual Learning Ability by 15%

In the field of artificial intelligence, we usually believe that “precision is everything”: the higher the precision of model parameters (such as FP16), the better the performance; quantization is often seen as a compromise made to save computing resources, usually at the cost of performance.
ArXiv URL:http://arxiv.org/abs/2512.18934v1
But what if I told you that in the setting of Continual Learning, this common sense is completely overturned?
The latest research finds that low-precision quantized models (such as 8-bit) can actually remember old knowledge better than high-precision models when learning new tasks, and in some tasks their performance even doubles! This is not only a technically counterintuitive finding, but also offers a brand-new approach to deploying AI that can “learn for life” on resource-constrained devices.
This article will take you deep into the paper titled When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models, revealing how quantization noise can become a magical remedy against “catastrophic forgetting.”
The Core Challenge: Catastrophic Forgetting
Large language models (LLMs) are powerful, but they have a fatal weakness: poor memory. When you fine-tune a trained model with new data, it often quickly forgets what it learned before; this phenomenon is known as Catastrophic Forgetting.
To address this problem, researchers usually use a Replay Buffer strategy, mixing a small amount of old-task data into training for new tasks.
However, in real-world deployment we face two constraints:
-
Computing resource limits: We need to quantize the model (for example, from FP16 down to INT4) to reduce memory usage.
-
Storage resource limits: We cannot store large amounts of old data indefinitely, so the replay buffer must be as small as possible.
So the question is: what exactly is the trade-off between quantization precision and replay buffer size?
A Stunning Reversal: Quantization Is Actually Stronger?
The Algoverse research team conducted a series of rigorous experiments on the LLaMA-3.1-8B model. They had the model learn three types of tasks in sequence: natural language understanding (NLU), math reasoning (Math), and code generation (Code).
The results were eye-opening:
-
Initial performance: As expected, the FP16 (high-precision) model performed best on the early tasks.
-
The reversal after continual learning: As tasks kept accumulating, the FP16 model’s performance began to collapse. In contrast, the quantized models (INT8 and INT4) showed remarkable resilience. On the forward accuracy of the final task, the quantized models outperformed FP16 by 8-15%.
-
The miracle of code generation: In the code generation task, the INT4 model’s performance even reached twice that of FP16 (40% vs 20%).
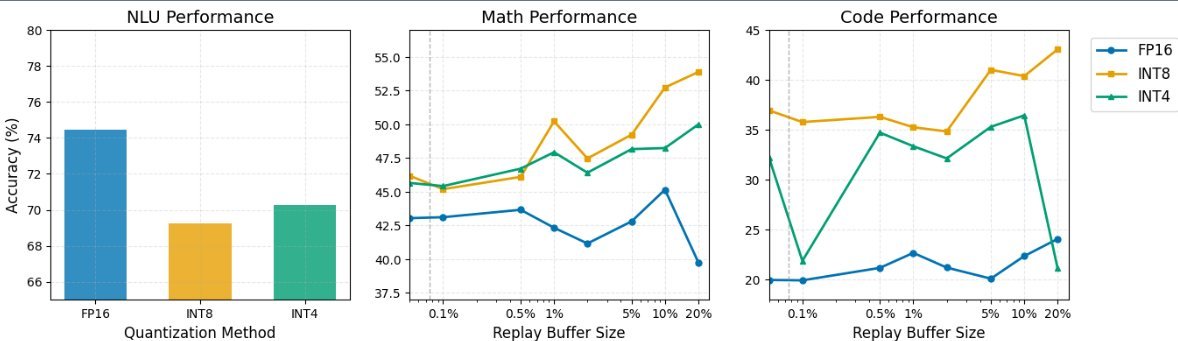
Figure 1: Task performance under different quantization precisions and replay sizes. It can be seen that under low replay ratios, the quantized models, especially INT8, show superior stability.
Why Is “Less” Actually “More”?
Why do lower-precision models learn better and forget less? The paper proposes a very interesting hypothesis: the noise introduced by quantization acts as a form of implicit regularization.
It is like when we learn, if we remember things too rigidly (overfitting), we tend to get stuck in our ways when facing new problems and end up discarding old knowledge.
-
FP16 model: Too “smart” and sensitive, it easily overfits to the gradients of new tasks, causing old knowledge to be quickly overwritten.
-
Quantized models (INT8/INT4): Due to the loss of precision, random noise is introduced. This noise smooths the loss landscape, forcing the model to find flatter, more general minima.
This mechanism allows quantized models, even when faced with very little replay data (or even just 0.1%), to effectively anchor old knowledge, achieving the best balance between plasticity and retention.
Experimental Insight: INT8 Is the Golden Balance Point
By constructing a “quantization-replay trade-off map,” the researchers arrived at several highly practical conclusions:
-
INT8 is the best choice: It strikes a perfect balance between computational efficiency and continual learning dynamics. By contrast, while INT4 performs well in some extreme cases, it is very sensitive to the size of the replay buffer; if the buffer is too small, performance drops off a cliff.
-
Even tiny replay helps a lot: For quantized models, keeping just 0.1% of old data can raise the retention rate on NLU tasks from 45% to 65%.
-
The fragility of FP16: High-precision models forget the fastest when there is not enough replay data. This means that if you must use FP16, you actually need more storage space to keep old data.
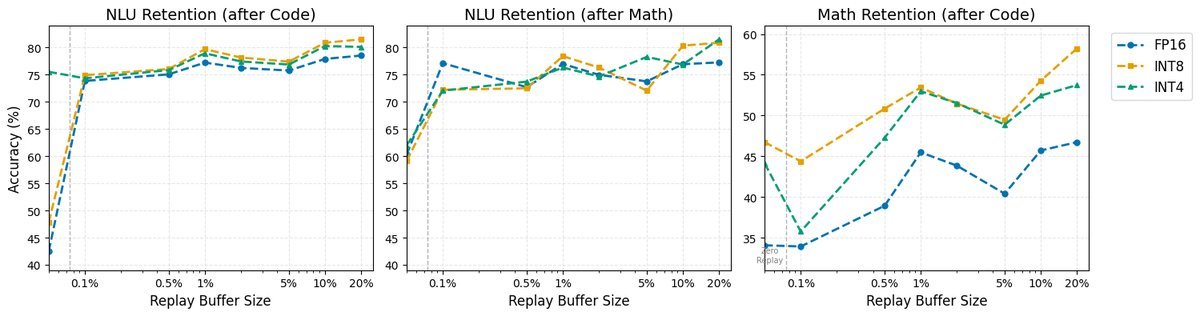
Figure 2: Knowledge retention rates under different precisions. Note the robust performance of INT8 at low replay ratios.
Deployment Advice: How Should You Configure Your Model?
Based on these findings, the paper provides concrete parameter recommendations for real-world deployment:
-
Natural language tasks (NLU): Regardless of precision, a small replay buffer of 1-2% is sufficient.
-
Math and code tasks: These tasks are harder to retain.
-
If you use INT8/INT4: it is recommended to allocate a 5-10% buffer.
-
If you use FP16: to achieve the same retention effect, you may need a 10-20% buffer or even larger.
Conclusion
This study breaks our stereotype about model compression. Quantization is not just about saving money and GPU memory; in the dynamic process of continual learning, it can unexpectedly act as a “protective charm,” preventing the model from favoring the new and forgetting the old.
For developers building edge AI or needing to frequently update model knowledge, this is undoubtedly great news: embrace 8-bit quantization, and you may gain not only speed, but also longer-lasting memory.