What is the objective of reasoning with reinforcement learning?
-
ArXiv URL: http://arxiv.org/abs/2510.13651v1
-
Authors: Damek Davis; Benjamin Recht
-
Affiliations: University of California, Berkeley; University of Pennsylvania
TL;DR
This article proves within a unified mathematical framework that several popular reinforcement learning algorithms for large language models, such as REINFORCE, rejection sampling, and GRPO, can all be viewed as stochastic gradient ascent on some monotonic transformation of the probability of obtaining the correct answer under a given prompt when handling binary rewards, thereby revealing the deep intrinsic connections among these algorithms.
Key Definitions
This article proposes a unified analytical framework, with the core definitions as follows:
-
Unified Objective Function $J_h(\theta)$: The central theoretical construct of this article, defined as $J_{h}(\theta):=\mathbb{E}_{x\sim Q}\left[h\left(\sum_{y\in C(x)}\pi_{\theta}(y\mid x)\right)\right]$. This function aims to maximize the expected value of a monotonic increasing function $h$ applied to the model’s probability of answering correctly. The differences among algorithms can be reduced to choosing different transformation functions $h$.
-
Probability of Correctness $p_{\theta}(C \mid x)$: Defined as $p_{\theta}(C \mid x):=\sum_{y\in C(x)}\pi_{\theta}(y\mid x)$. It represents the total probability that, given a prompt $x$, a response $y$ sampled from the model $\pi_{\theta}$ is judged correct (i.e., belongs to the correct-answer set $C(x)$).
-
Per-sample Weight $Z_i$: Commonly referred to as “advantages” in the reinforcement learning literature. It is the weight applied to the log-probability gradient of each sample during model parameter updates. The update rule is: $\theta\leftarrow\theta+\eta\frac{1}{M}\sum_{i=1}^{M}Z_{i}\nabla_{\theta}\log\pi_{\theta}(y_{i}\mid x)$. The key insight of this article is that different designs of the weight $Z_i$ directly determine the monotonic transformation $h$ in the unified objective function being optimized.
Related Work
At present, in the post-training stage of large language models (LLMs), researchers widely use various reinforcement learning algorithms to align models with human preferences or improve their performance on specific benchmark tasks. These algorithms typically follow a meta-algorithm: sample prompts from a corpus, let the model generate multiple responses, have an external evaluation source (such as human annotation or an automatic verifier) label the responses as “good” or “bad,” and then fine-tune the model based on these triplets (prompt, response, label).
However, there is a key issue in this field: although algorithms such as REINFORCE, rejection sampling fine-tuning, and GRPO all follow the above pattern, their concrete implementations and theoretical motivations differ, making it unclear what specific objective function each of them is actually optimizing. This lack of a unified perspective hinders understanding the intrinsic connections among different algorithms and makes direct comparison difficult.
This article aims to address this issue by providing a unified mathematical framework and proving that these seemingly different algorithms are in fact optimizing a family of very similar objective functions, thereby clearly revealing the relationships among them.
Method
Unified Framework: Weighted Stochastic Gradient Ascent
This article first summarizes most existing RL fine-tuning algorithms for LLM inference into a more specific algorithmic framework (Algorithm 1):
- Select a question $x$ from the corpus $Q$.
- Sample $M$ responses $y_1, \dots, y_M$ for $x$ using the current model.
- Compute a per-sample weight $Z_i$ based on the evaluation result of each response $y_i$ (correct or incorrect).
- Fine-tune the model using a weighted supervised learning update rule:
Innovation: From Weights to Objective Functions
The article’s core innovation is to reveal the direct connection between the above update step and the optimization of a specific objective function. The authors prove that the expected value of this stochastic gradient update is exactly the gradient of an objective function $J_h(\theta)$. Specifically, different choices of the weights $Z_i$ induce different monotonic transformation functions $h$, such that:
\[\mathbb{E}_{y_{1:M}}\left[\frac{1}{M}\sum_{i=1}^{M}Z_{i}\nabla_{\theta}\log\pi_{\theta}(y_{i}\mid x)\right]:=\nabla_{\theta}h_{M}(p_{\theta}(C\mid x))\]This means that the choice of advantage function used by a particular algorithm (i.e., the weight $Z_i$) ultimately determines the form of the objective function $J_h$ it optimizes. Through this framework, the true optimization objectives of existing algorithms can be analyzed and compared.
Deriving the Weight Form and Objective Function
This article considers a class of specific weight forms whose values depend on whether the current sample is correct ($R_i = 1_{y_i \in C(x)}$) and on the number of correct responses among the other $M-1$ samples ($S_i = \sum_{j \neq i} R_j$):
\[Z_{i}=(1-R_{i})a_{S_{i}}+R_{i}b_{S_{i}}\]where $a_s$ and $b_s$ are arbitrary functions of $s$.
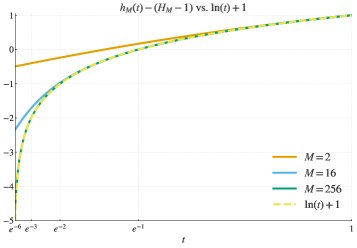
The article proves that algorithms using such weights induce the following objective-function transformation $h_M(t)$:
\[h_{M}(t)=\frac{1}{M}\sum_{s=0}^{M-1}(b_{s}-a_{s})I_{t}(s+1,M-s)\]where $I_t(\cdot,\cdot)$ is the regularized incomplete beta function. This general formula forms the basis for analyzing specific algorithms.
Analysis of Specific Algorithms
“Original” REINFORCE
- Weight Choice: $Z_i = 1_{y_i \in C(x)}$, i.e., the weight is 1 when the response is correct and 0 otherwise.
- Equivalent Objective Function: This choice corresponds to the simplest transformation $h(t) = t$. Therefore, the objective of “original” REINFORCE is to directly maximize the model’s average probability of answering correctly, $\mathbb{E}_{x \sim Q}[p_{\theta}(C \mid x)]$.
Rejection Sampling
- Weight Choice: In one implementation, all correct responses $V$ are selected from the $M$ samples, and the gradient estimator $\frac{1}{ \mid V \mid }\sum_{y\in V}\nabla_{\theta}\log\pi_{\theta}(y\mid x)$ is used. This is equivalent to weights $Z_i = R_i M / \sum_{j} R_j$ (the update is skipped when there are no correct responses).
- Equivalent Objective Function: The objective function $h_M(t)$ induced by this weighting approximates the logarithmic function $h(t) = \log(t)$. The approximation becomes more accurate as the number of samples $M$ increases.
- Pure Logarithmic Objective: The article further points out that a “pure” rejection sampling algorithm (continuously sampling until $B$ correct responses are obtained) can exactly perform stochastic gradient ascent on $J_{\log}(\theta) = \mathbb{E}[\log p_{\theta}(C \mid x)]$. The unbiasedness of its gradient estimator can be proved using the log trick:
GRPO
- Weight Choice: GRPO normalizes gradients using the mean and standard deviation of sample rewards, and its weight form can be expressed as:
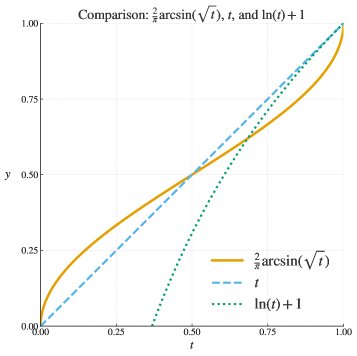
- Equivalent Objective Function: After derivation, the article shows that the objective function $h_{M, \varepsilon}(t)$ induced by GRPO converges in the ideal case ($M \to \infty, \varepsilon \to 0$) to the inverse-sine transformation $h(t) = 2\arcsin\sqrt{t}$. The idealized gradient update can be written as:
The figure below shows that as the sample size $M$ increases and the regularization term $\varepsilon$ decreases, the actual objective function of GRPO (after normalization) approaches the arcsine function. 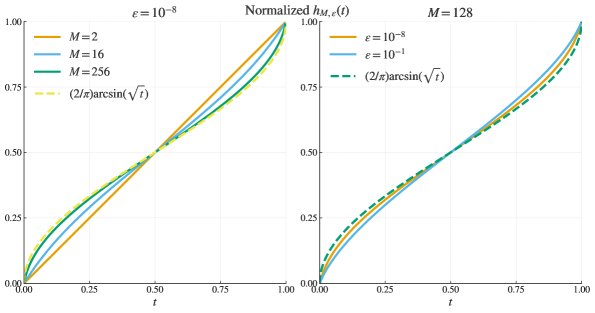
Experimental Conclusions
This paper is a theoretical analysis paper and does not include a specific experimental section. Its conclusions are theoretical insights derived from mathematical derivations:
-
A unified optimization objective: Many seemingly different RL fine-tuning algorithms, such as REINFORCE, rejection sampling, and GRPO, are in fact optimizing the same underlying objective—maximizing the probability of the correct answer—except that each uses a different monotonic function (such as the identity, logarithm, or arcsine) to rescale that probability.
-
An analogy for method selection: Debating which algorithm is best is similar to debating whether Logistic Loss or Hinge Loss is better in supervised classification tasks. Statistically, both usually yield classifiers with comparable performance, and the optimal choice depends on the specific task and data. Likewise, in RL fine-tuning, no scaling function $h$ has universal “magic”; the best algorithm will be context-dependent.
-
Practical implications: The framework in this paper provides a “recipe” for designing new fine-tuning algorithms. Researchers can first determine a desired scaling function $h(t)$ (for example, the log-odds function $h(t)=\log(t/(1-t))$), and then use the Bernstein-polynomial-based method proposed in this paper to reverse-engineer the corresponding sample weights $Z_i$.
Ultimately, the conclusion of this paper is that all these algorithms are pursuing closely related objectives. Since all objective functions are monotonic, their global optima are the same (that is, the model assigns 100% probability to the correct answers for all problems). The differences between algorithms mainly lie in the optimization dynamics rather than the final objective. This unified perspective gives researchers in the field a clearer understanding and greater flexibility in design.