Voyager: An Open-Ended Embodied Agent with Large Language Models
-
ArXiv URL: http://arxiv.org/abs/2305.16291v2
-
Authors: Yuke Zhu; Guanzhi Wang; Yunfan Jiang; Chaowei Xiao; Yuqi Xie; Anima Anandkumar; Linxi (Jim) Fan; Ajay Mandlekar
-
Publishing Institutions: Caltech; NVIDIA; Stanford; University of Texas at Austin; University of Wisconsin-Madison
TL;DR
This paper proposes an embodied intelligent agent called Voyager, which for the first time uses a large language model (LLM) to achieve intervention-free lifelong learning in the open world of Minecraft, continuously exploring, acquiring skills, and making new discoveries through an automatic curriculum, a continuously growing skill library, and an iterative prompting mechanism.
Key Definitions
The core of this paper is the Voyager intelligent agent, whose capabilities are defined by the following three innovative key components:
- Automatic Curriculum: A module driven by GPT-4 that automatically proposes exploratory, moderately difficult new tasks based on the agent’s current state (such as inventory and location), completed and failed tasks, and the overall goal of “discovering as many diverse things as possible.”
- Skill Library: A continuously growing database that stores executable code, i.e., skills. Each skill is indexed by the embedding vector of its natural-language description, so it can be retrieved and reused when similar tasks are encountered in the future. This allows skills to be composed, capabilities to accumulate rapidly, and catastrophic forgetting to be effectively mitigated.
- Iterative Prompting Mechanism: A closed-loop process for code generation and self-improvement. This mechanism executes the generated code and gathers feedback from three sources: environment feedback (such as in-game events), execution errors (from the code interpreter), and self-verification (by another GPT-4 instance acting as a critic). It then integrates this feedback into the next prompt to iteratively correct the code until the task succeeds.
Related Work
At present, building a general embodied intelligent agent that can continuously explore, plan, and learn new skills in the open world remains a major challenge in artificial intelligence. Traditional Reinforcement Learning (RL) and imitation learning methods struggle with systematic exploration, interpretability, and generalization.
In recent years, intelligent agents based on Large Language Model (LLM) have made progress in fields such as games and robotics by leveraging their implicit world knowledge to generate high-level plans or executable strategies. However, these agents typically lack lifelong learning capability, meaning they cannot continuously acquire, update, accumulate, and transfer knowledge over a long time span.
This paper aims to address this core problem: creating an agent that can learn autonomously like a human player in an open world such as Minecraft, where there are no preset goals. Specifically, the challenges addressed in this paper are: how to enable the agent to (1) propose appropriate tasks based on its own capabilities and the environment; (2) learn from environmental feedback and refine skills, storing mastered skills in memory for reuse; (3) continue exploring the world in a self-driven manner.
Method
As an LLM-driven embodied lifelong learning agent, Voyager’s core workflow does not rely on model fine-tuning, but is achieved through interaction with a black-box LLM (GPT-4). The entire system consists of the following three collaborating components.
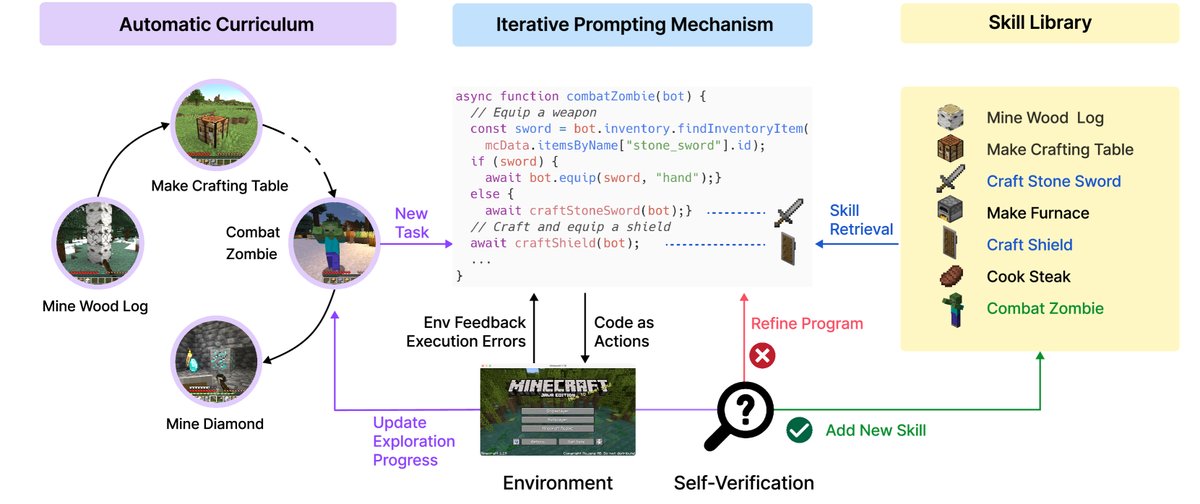 Figure 2: Voyager contains three key components: an automatic curriculum for open-ended exploration, a skill library for increasingly complex behaviors, and an iterative prompting mechanism that uses code as the action space.
Figure 2: Voyager contains three key components: an automatic curriculum for open-ended exploration, a skill library for increasingly complex behaviors, and an iterative prompting mechanism that uses code as the action space.
Automatic Curriculum
In the open world, the agent must face tasks of varying difficulty. An automated curriculum ensures that the learning process is challenging yet manageable, while stimulating the agent’s curiosity. Voyager’s automatic curriculum leverages GPT-4’s vast knowledge to generate a task stream in a bottom-up manner, allowing it to flexibly adapt to exploration progress and the agent’s current state.
The prompt for curriculum generation includes the following parts:
- Instructions: Encourage diverse behavior and set constraints, such as “My ultimate goal is to discover as many different things as possible… the next task should not be too hard.”
- Agent State: Includes inventory, equipment, surrounding environment, biome, health status, and more.
- Historical Tasks: A list of completed and failed tasks, reflecting the agent’s capability boundaries.
- Additional Context: Self-questions and answers generated by GPT-3.5 based on the current state to enrich contextual information.
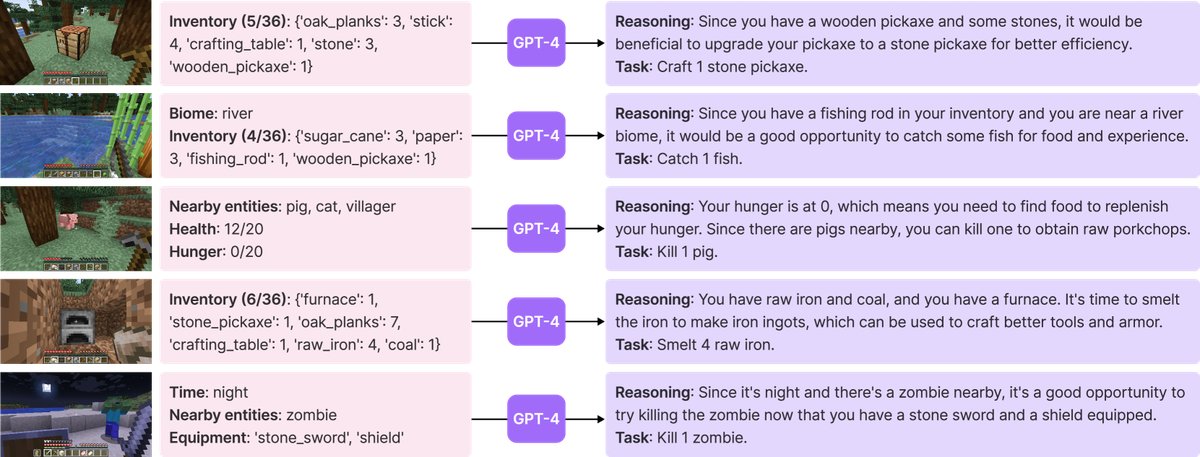 Figure 3: Example tasks proposed by the automatic curriculum. For brevity, only part of the prompt is shown.
Figure 3: Example tasks proposed by the automatic curriculum. For brevity, only part of the prompt is shown.
Skill Library
To handle the increasingly complex tasks proposed by the automatic curriculum, a skill library that can accumulate and evolve capabilities is essential. This paper chooses to represent skills using code, because programs are naturally temporally extensible and compositional, making them well suited for long-horizon tasks in Minecraft.
- Skill Storage: When a new skill (a piece of JavaScript code) is successfully generated and verified through the iterative prompting mechanism, it is added to a vector database. The database “key” is the embedding vector of the skill description text, and the “value” is the skill code itself.
- Skill Retrieval: When the agent faces a new task, the system performs semantic search in the skill library using a query context formed by task planning and environmental feedback, retrieving the top-5 most relevant skills. These retrieved skills are then provided to the LLM as in-context learning examples to help generate new, more complex skill code.
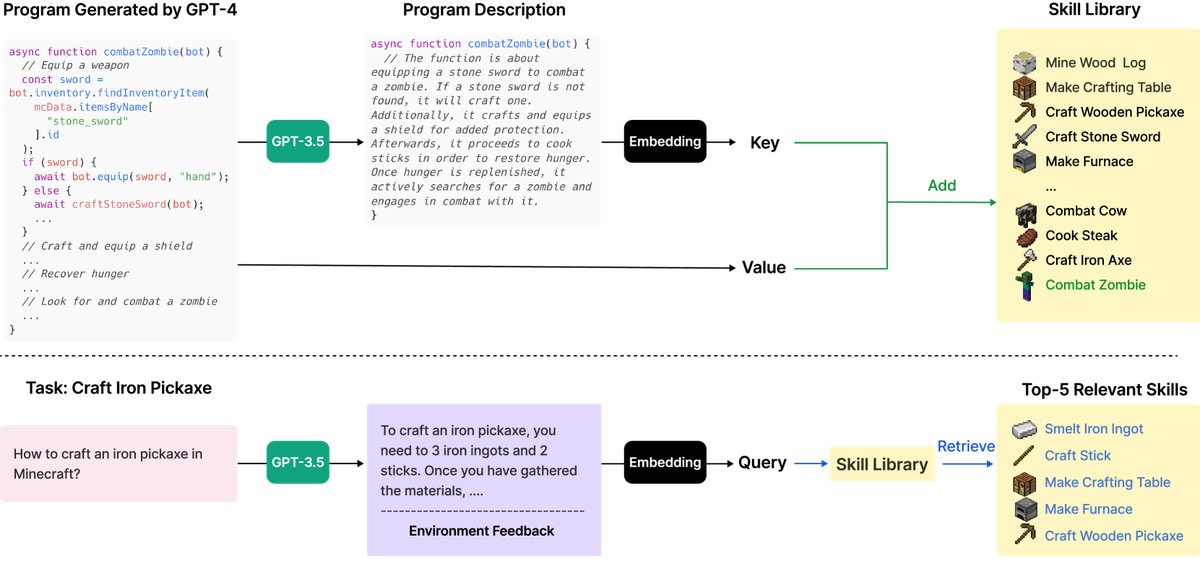 Figure 4: Top: Adding a new skill. After GPT-4 generates and verifies a new skill, it is added to the skill library (a vector database). The key is the embedding vector of the program description, and the value is the program itself. Bottom: Skill retrieval. When facing a new task, the system first generates general advice for solving the task and combines it with environmental feedback as the query, then retrieves the top-5 relevant skills.
Figure 4: Top: Adding a new skill. After GPT-4 generates and verifies a new skill, it is added to the skill library (a vector database). The key is the embedding vector of the program description, and the value is the program itself. Bottom: Skill retrieval. When facing a new task, the system first generates general advice for solving the task and combines it with environmental feedback as the query, then retrieves the top-5 relevant skills.
Iterative Prompting Mechanism
LLMs are hard-pressed to generate fully correct complex code in a single shot. To address this, this paper proposes an iterative prompting mechanism that self-improves through three types of feedback.
- Environment Feedback: Text describing the program’s intermediate execution state. For example, the game may return the message “I can’t craft an iron chestplate because I still need 7 iron ingots,” which points to the cause of failure.
- Execution Errors: Standard error messages from the code interpreter, such as syntax errors or invalid function calls, providing direct clues for fixing bugs.
- Self-verification: To check whether the task has been completed successfully, this paper introduces another GPT-4 instance as a “critic.” Based on the agent’s current state and the task objective, it determines whether the task is complete. If the task fails, it also provides improvement suggestions. This approach is more comprehensive than simple self-reflection because it can both judge success and reflect on failure.
This iterative process continues until the self-verification module confirms that the task is complete. At that point, the new skill is stored in the skill library, and the next goal is requested from the automatic curriculum. If the agent is still stuck after 4 rounds of code generation, it requests a new task.
 Figure 5: Left: Example of environmental feedback. GPT-4 realizes that it still needs 2 wooden planks before making a stick. Right: Example of an execution error. GPT-4 realizes it should craft a wooden axe instead of an acacia axe, because there is no acacia axe in the game.
Figure 5: Left: Example of environmental feedback. GPT-4 realizes that it still needs 2 wooden planks before making a stick. Right: Example of an execution error. GPT-4 realizes it should craft a wooden axe instead of an acacia axe, because there is no acacia axe in the game.
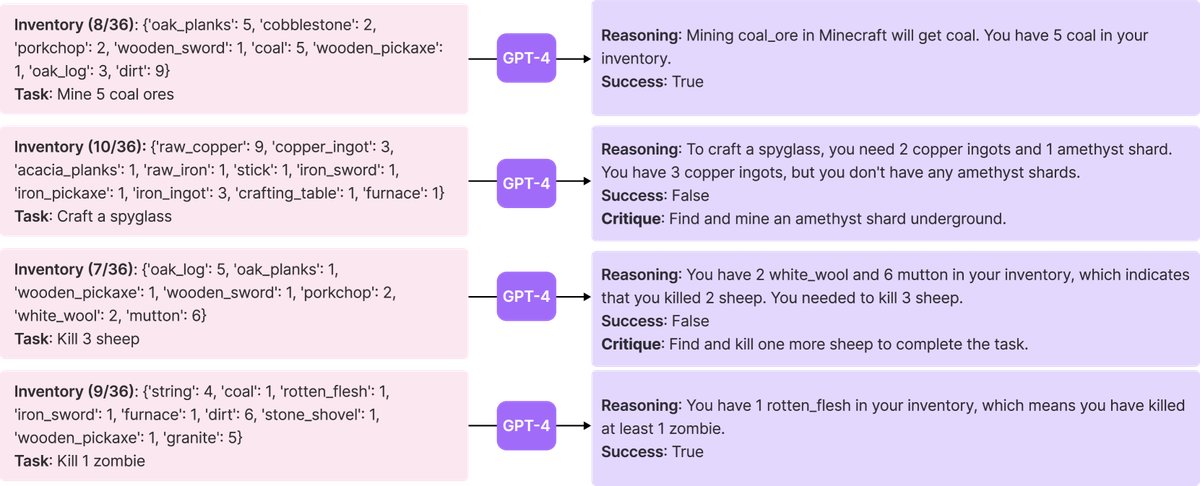 Figure 6: Self-verification example.
Figure 6: Self-verification example.
Experimental Conclusions
This paper systematically evaluates Voyager’s performance across a series of experiments, including exploration performance, tech tree mastery, map coverage, and zero-shot generalization.
Core Performance Evaluation
- Significantly stronger exploration ability: Over 160 prompt iterations, Voyager discovered 63 unique items, 3.3 times more than the baseline methods (ReAct, Reflexion, AutoGPT). Due to the lack of effective curriculum guidance, the baseline methods struggled to make progress under open-ended exploration objectives.
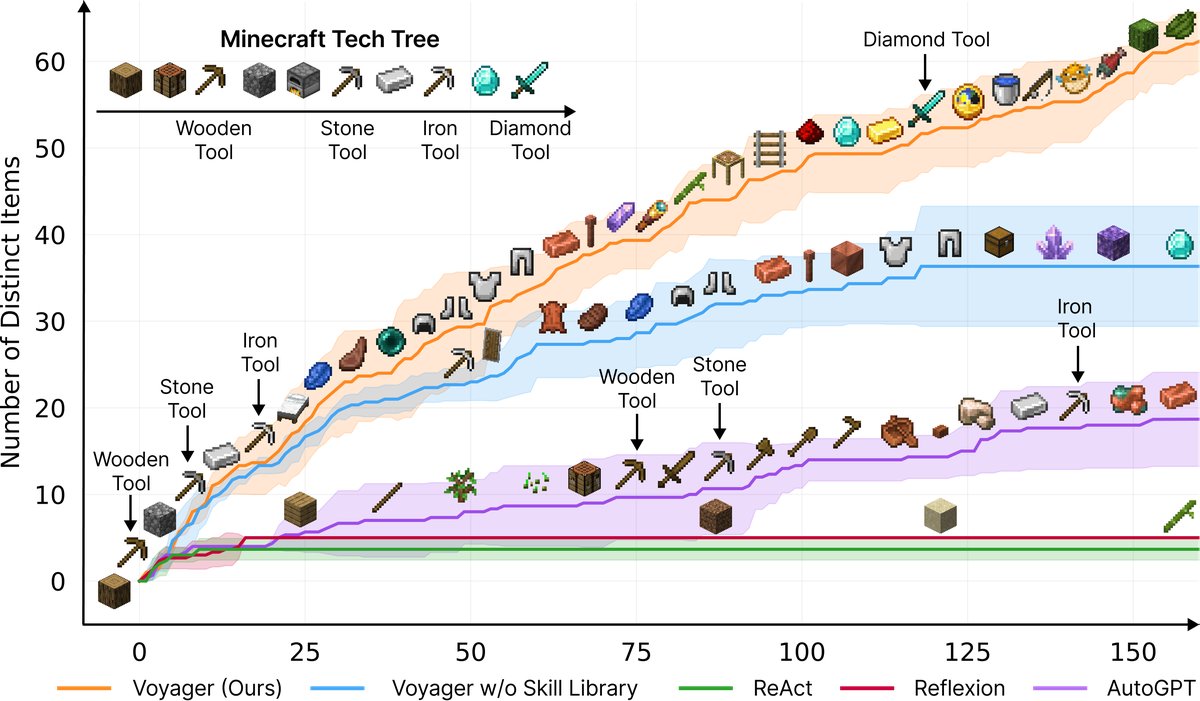 Figure 1: Voyager continuously discovers new items and skills, significantly outperforming the baselines. The X-axis indicates the number of prompt iterations.
Figure 1: Voyager continuously discovers new items and skills, significantly outperforming the baselines. The X-axis indicates the number of prompt iterations.
- Continuous tech tree mastery: In unlocking the Minecraft tech tree (wooden tools → stone tools → iron tools → diamond tools), Voyager showed overwhelming advantages, unlocking wooden, stone, and iron tools 15.3x, 8.5x, and 6.4x faster than the baselines, respectively, and was the only intelligent agent that successfully unlocked diamond-tier tools.
Table 1: Tech tree mastery Scores indicate the number of successful runs out of three independent runs. 0/3 means the method failed to unlock that tier within the maximum number of iterations (160). The numbers are the average prompt iterations over three trials; lower is better.
| Method | Wooden Tools | Stone Tools | Iron Tools | Diamond Tools |
|---|---|---|---|---|
| ReAct | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| Reflexion | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| AutoGPT | $92\pm 72$ (3/3) | $94\pm 72$ (3/3) | $135\pm 103$ (3/3) | N/A (0/3) |
| Voyager (without skill library) | 7±2 (3/3) | 9±4 (3/3) | $29\pm 11$ (3/3) | N/A (0/3) |
| Voyager (our method) | 6±2 (3/3) | 11±2 (3/3) | 21±7 (3/3) | 102 (1/3) |
- Extensive map traversal: Voyager traveled 2.3 times farther than the baselines and successfully crossed diverse terrain. By contrast, the baseline intelligent agents often got stuck in local areas.
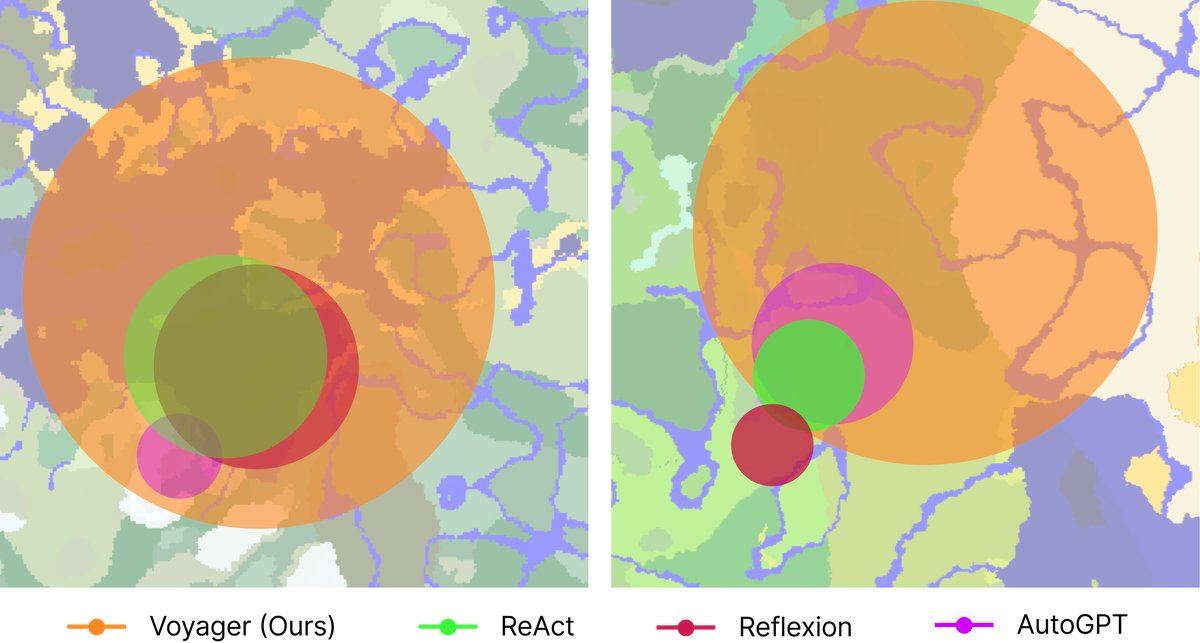 Figure 7: Map coverage: bird’s-eye view. Voyager crossed diverse terrain and traveled 2.3 times farther than the baselines.
Figure 7: Map coverage: bird’s-eye view. Voyager crossed diverse terrain and traveled 2.3 times farther than the baselines.
- Efficient zero-shot generalization: In a brand-new world, when faced with unseen tasks such as crafting a diamond pickaxe, Voyager was able to leverage the skill library built during prior learning and reliably complete all tasks. In contrast, the baseline methods could not complete any task. Interestingly, even AutoGPT improved after being connected to Voyager’s skill library, demonstrating the library’s generality and plug-and-play value.
Table 2: Zero-shot generalization on unseen tasks Scores indicate the number of successful attempts out of three independent runs. 0/3 means the method failed to solve the task within the maximum number of iterations (50). The numbers are the average prompt iterations over three trials; lower is better.
| Method | Diamond Pickaxe | Golden Sword | Lava Bucket | Compass |
|---|---|---|---|---|
| ReAct | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| Reflexion | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| AutoGPT | N/A (0/3) | N/A (0/3) | N/A (0/3) | N/A (0/3) |
| AutoGPT (using our skill library) | 39 (1/3) | 30 (1/3) | N/A (0/3) | 30 (2/3) |
| Voyager (without skill library) | 36 (2/3) | $30\pm 9$ (3/3) | $27\pm 9$ (3/3) | $26\pm 3$ (3/3) |
| Voyager (our method) | 19±3 (3/3) | 18±7 (3/3) | 21±5 (3/3) | 18±2 (3/3) |
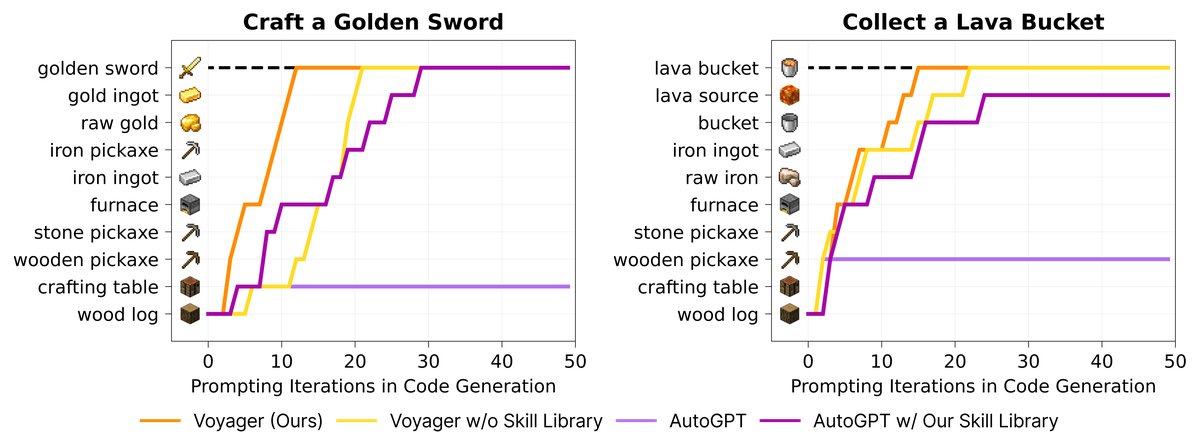 Figure 8: Zero-shot generalization on unseen tasks. The intermediate progress of each method on two tasks is visualized.
Figure 8: Zero-shot generalization on unseen tasks. The intermediate progress of each method on two tasks is visualized.
Ablation Study
- Automatic curriculum is crucial; removing it reduced the number of discovered items by 93%.
- The skill library is essential for avoiding late-stage performance stagnation and for building complex behaviors.
- Self-verification is the most important of all feedback types; removing it reduced performance by 73%.
- Using GPT-4 for code generation is far superior to GPT-3.5, discovering 5.7 times more items, demonstrating GPT-4’s generational leap in coding ability.
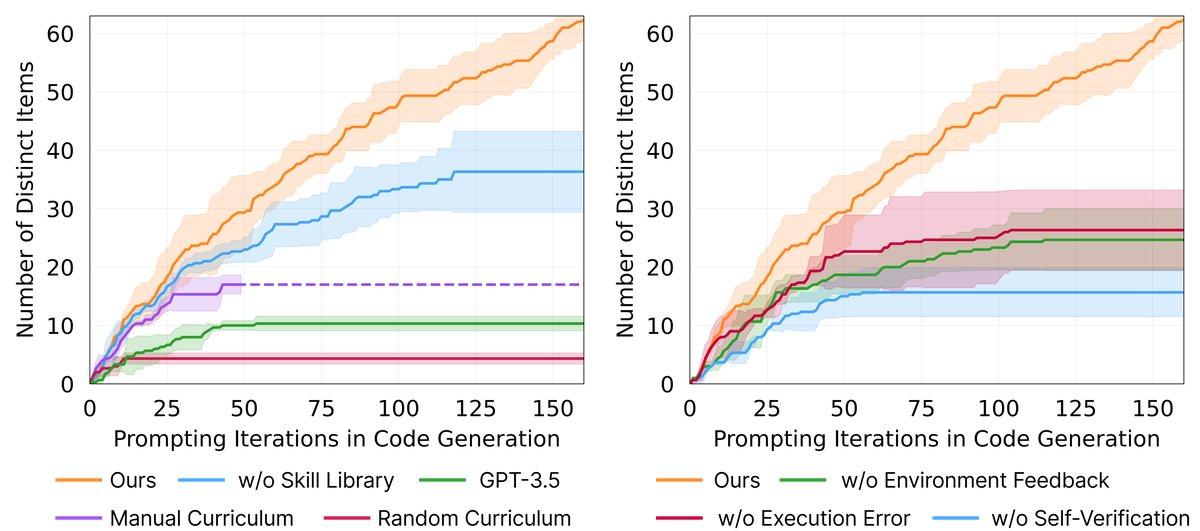 Figure 9: Ablation study. Left: the importance of automatic curriculum, the skill library, and GPT-4. Right: the necessity of each type of feedback in the iterative prompting mechanism.
Figure 9: Ablation study. Left: the importance of automatic curriculum, the skill library, and GPT-4. Right: the necessity of each type of feedback in the iterative prompting mechanism.
Integration with Human Feedback
Although Voyager currently lacks visual perception, experiments show that it can complete more complex tasks by integrating human feedback, such as building a Nether portal or a house. Humans can act as a “critic” (providing visual corrections) or a “curriculum designer” (breaking down complex tasks), enhancing Voyager’s ability to construct three-dimensional spatial structures.
 Figure 10: Progress in building and designing under human input.
Figure 10: Progress in building and designing under human input.
Summary
The Voyager proposed in this paper is the first LLM-driven embodied lifelong learning agent. Experiments show that it can continuously explore the world, develop increasingly complex skills without human intervention, and demonstrate outstanding performance in discovering new items, unlocking the tech tree, exploring the map, and generalizing to new tasks. Voyager’s success provides a strong starting point and example for developing general agent without fine-tuning model parameters.