Virtual Width Networks
ByteDance VWN: Widening Transformer Without Extra Compute, Training Speed Up to 3x!

If you want a large model to become stronger, the most direct way is to “widen” it—by increasing the hidden-layer dimension. But this causes compute costs to explode quadratically, becoming a hard bottleneck to overcome.
Paper Title: Virtual Width Networks
ArXiv URL:http://arxiv.org/abs/2511.11238v1
Is there a way to enjoy the benefits of “going wider” without paying the hefty price?
ByteDance’s latest research, Virtual Width Networks (VWN), offers an extremely clever answer. Through an innovative approach, it expands the model’s “virtual width” with almost no increase in core compute load, delivering astonishing performance gains.
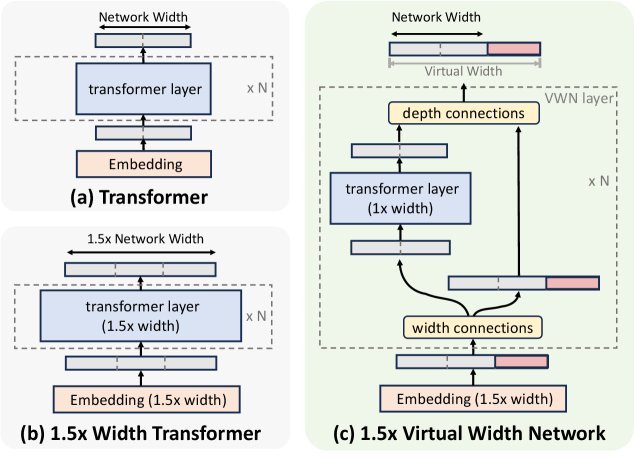
Caption: (a) Standard Transformer, (b) naive widening (quadratic compute growth), (c) VWN decouples representation width from backbone width.
The Core Idea of VWN: Decoupling Representation and Computation
In a traditional Transformer, the dimension of the token embedding (Embedding) and the hidden dimension $D$ of the network backbone (Backbone) are the same. If you want to double $D$, the parameter count and compute of both the attention mechanism and the feed-forward network will increase by about four times.
The key insight of VWN is: decouple representation width from backbone width.
Simply put, VWN allows us to use a very wide token embedding dimension $D^{\prime}$ (for example, 8 times the original width $D$), but when the core computation modules of each Transformer layer (such as self-attention and FFN) process it, a lightweight operation “compresses” it back to the original width $D$.
After processing, it is then “expanded” back to the wide dimension $D^{\prime}$ and passed to the next layer. In this way, the model passes richer “wide” representations between layers, while the most expensive computations still happen in the “narrow” dimension, cleverly avoiding the quadratic growth in compute cost.
GHC: The Bridge Between Virtual and Reality
The key to implementing the above “compress-expand” operation is a new module called Generalized Hyper-Connections (GHC).
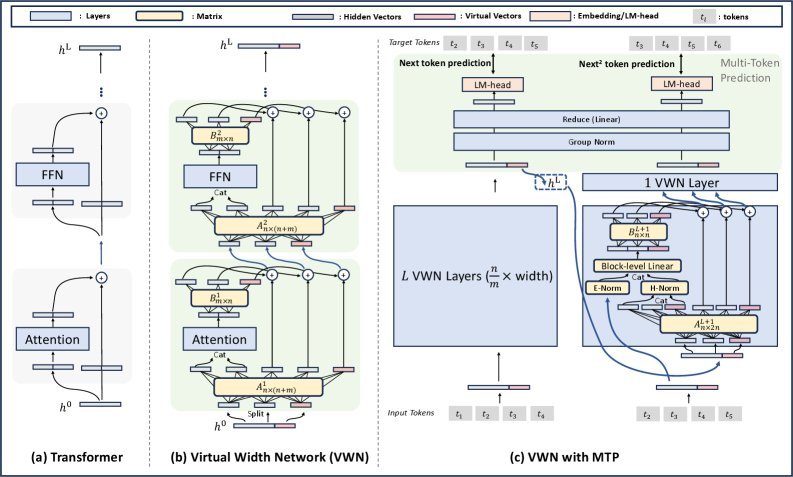
Caption: Overview of the VWN architecture. GHC enables flexible interaction between wide and narrow dimensions through lightweight matrices A and B.
GHC is essentially a set of lightweight linear transformations. In each Transformer layer:
-
Compression: GHC uses a projection matrix $\mathbf{A}^{l}$ to compress the input over-width hidden states (Over-Width Hidden States) to the standard width required by the backbone network.
-
Expansion: After the backbone network finishes processing, GHC uses another projection matrix $\mathbf{B}^{l}$ to expand the output back to the wide dimension and fuse it with the original over-width hidden states.
Going further, the study also proposes Dynamic GHC (DGHC), where the transformation matrices $\mathbf{A}$ and $\mathbf{B}$ can be generated dynamically based on the input, giving the model stronger adaptability. The compute and memory overhead of the entire GHC module is very small, almost negligible.
Synergy: When VWN Meets Multi-Token Prediction
To better leverage the wider representation space brought by VWN, the study combines it with Multi-Token Prediction (MTP).
MTP requires the model to predict multiple future tokens at the same time, which itself demands stronger short-range compositional modeling ability. The ultra-wide representation space provided by VWN happens to offer sufficient “bandwidth” for learning such complex relationships.
Conversely, the dense supervision signal provided by MTP also effectively drives the learning of VWN’s wide representations. The two form a perfect synergy.
Astonishing Experimental Results
How effective is VWN? The study validated it on a series of large-scale MoE models, and the results are impressive.
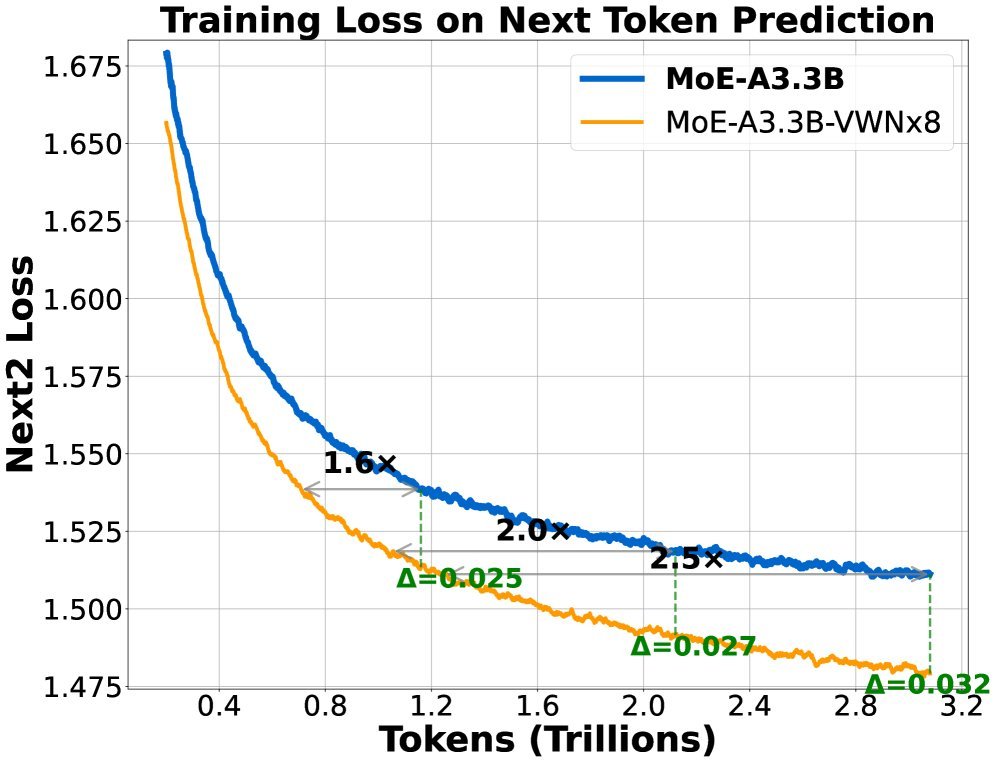
Caption: Training loss comparison between VWN (orange line) and the baseline (blue line) on a 3.3B-parameter MoE model.
On an MoE model with 3.3B active parameters, VWN with 8x virtual width expansion (VWNx8) showed major advantages:
-
Training speedup: On single-token prediction tasks, optimization speed improved by more than 2x; on two-token prediction tasks, the speedup reached as high as 3x.
-
Data efficiency: VWN achieved the same loss level using only 1/2.5 to 1/3.5 of the data required by the baseline model.
-
Amplified advantage: As training progressed, the performance gap between VWN and the baseline model kept widening, showing strong scaling potential.
The study also found an approximate log-linear relationship between virtual width and model loss, suggesting that “virtual width scaling” may become a third effective scaling law for improving large-model efficiency, following model parameters and data size.
Deep Attention: A New Perspective
The paper also offers a very insightful interpretation: viewing VWN as a kind of attention mechanism along the depth axis.
If we treat the stacked Transformer layers as a “depth sequence,” then:
-
Standard residual connections: only focus on the output of the previous layer, equivalent to a sliding window of size 2.
-
VWN/GHC: by passing and fusing wide representations across layers, it realizes a multi-layer, linear-attention-like information aggregation mechanism. It allows the current layer to “see” compressed information from multiple previous layers, greatly expanding the model’s “depth receptive field.”
Summary
Virtual Width Networks (VWN) proposes a highly forward-looking model architecture paradigm. By decoupling representation width from compute width, it allows us to gain the huge benefits of a “wider” model at very low cost. This work not only significantly improves training efficiency and performance, but more importantly, it opens up a brand-new and highly promising dimension for scaling large models. Simple and effective, VWN once again demonstrates the crucial role of architectural innovation in the development of AI.