VideoAgentTrek: Computer Use Pretraining from Unlabeled Videos
-
ArXiv URL: http://arxiv.org/abs/2510.19488v1
-
Authors: Hongjin Su; Zekun Wang; Tao Yu; Binyuan Hui; Xinyuan Wang; Haoyuan Wu; Junda Chen; Jingren Zhou; Junli Wang; Jixuan Chen; and 14 others
-
Publishing Organization: Alibaba Group; The University of Hong Kong
TL;DR
This paper proposes a scalable method called VideoAgentTrek, which automatically mines structured training data from unlabeled public screen-recording videos through an inverse dynamics module (VADM), thereby addressing the reliance on large-scale manually annotated data when training computer-use intelligent agent (Agent).
Key Definitions
- VideoAgentTrek: A complete, scalable automated pipeline designed to transform unlabeled screen-recording videos into high-quality data for training computer-use intelligent agent. The pipeline consists of three main stages: video collection and preprocessing, structured action extraction via the VADM module, and model pretraining and fine-tuning using the extracted data.
- VADM (VideoAgentTrek inverse Dynamics Module): The core component of VideoAgentTrek, an inverse dynamics module responsible for recovering structured action information from raw video clips. It contains two key parts: (1) an action event detector, used to precisely locate the start and end times of various GUI interactions in the video down to the millisecond (such as clicks and typing); and (2) an action parameter recognizer, used to extract specific action parameters from the localized video clips, such as click coordinates \((x,y)\) and typed text content.
- GUI-Filter: A lightweight video preprocessing tool. Built on the YOLOv8x model, it efficiently filters and retains only video clips containing graphical user interface (GUI) interactions by detecting whether a mouse cursor is present in video frames, thereby removing irrelevant content such as slides and live narration.
Related Work
At present, there are three main ways to obtain training data for computer-use intelligent agent:
- Manual annotation: By manually recording operation trajectories, high-quality and highly accurate annotated data can be generated, but the cost is extremely high, making it difficult to scale, and the covered application scenarios are limited.
- Programmatic synthesis: Large amounts of interaction data are automatically generated in simulators or scripted environments. Although the scale is large and the parameters are precise, it often lacks the diversity and complexity of real-world UIs and deviates from real scenarios.
- Web mining: Data is obtained from online tutorials, RPA logs, and other resources. This offers broad coverage and good diversity, but it usually lacks precise action time boundaries and structured action parameters, and the data quality is uneven.
The key bottleneck in this research area is the lack of a data acquisition method that can balance scale, diversity, and quality. This paper aims to solve this core problem: how to automatically transform the large amount of unstructured screen-recording videos on the internet into structured interaction trajectories with precise parameters that can be directly used for intelligent agent training, thereby eliminating dependence on expensive manual annotation.
Method
The proposed VideoAgentTrek is a three-stage automated pipeline that converts unlabeled web videos into structured training data for intelligent agent.
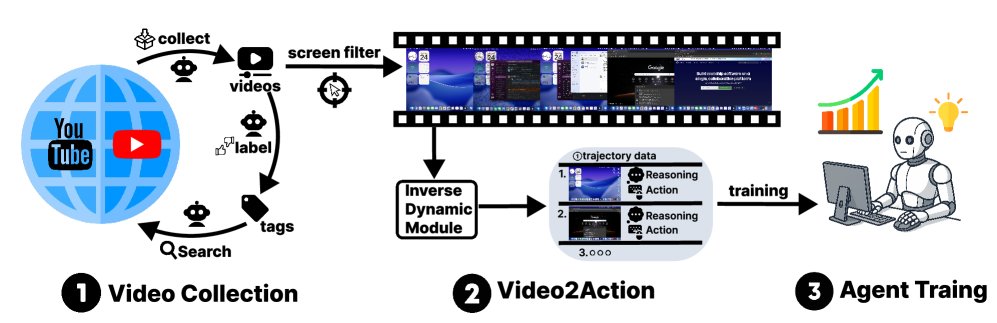 Overview of VideoAgentTrek. (1) Video collection and preprocessing: Crawl screen-recording tutorials and use GUI-Filter to select GUI operation clips. (2) VADM: An inverse dynamics module that first performs dense action event detection to localize clips and assign action types, then performs *action parameterization (e.g., click coordinates, typed text) to produce structured $(\text{screenshot}, \text{action}, \text{parameter})$ trajectories. (3) Model pretraining and fine-tuning: Use the mined trajectories for continued pretraining and supervised fine-tuning of computer-use intelligent agent.*
Overview of VideoAgentTrek. (1) Video collection and preprocessing: Crawl screen-recording tutorials and use GUI-Filter to select GUI operation clips. (2) VADM: An inverse dynamics module that first performs dense action event detection to localize clips and assign action types, then performs *action parameterization (e.g., click coordinates, typed text) to produce structured $(\text{screenshot}, \text{action}, \text{parameter})$ trajectories. (3) Model pretraining and fine-tuning: Use the mined trajectories for continued pretraining and supervised fine-tuning of computer-use intelligent agent.*
Video Collection and Preprocessing
Video Collection
This paper adopts a scalable video collection strategy. It first uses seed keywords such as “Excel tutorial” to search for videos, and then ingests all videos from high-quality channels (sample pass rate $\geq$ 80%) as a whole, using the channels’ tags and metadata for iterative discovery. This “channel consistency”-based strategy efficiently collected about 55,000 candidate videos (about 10,000 hours) with a small amount of human supervision.
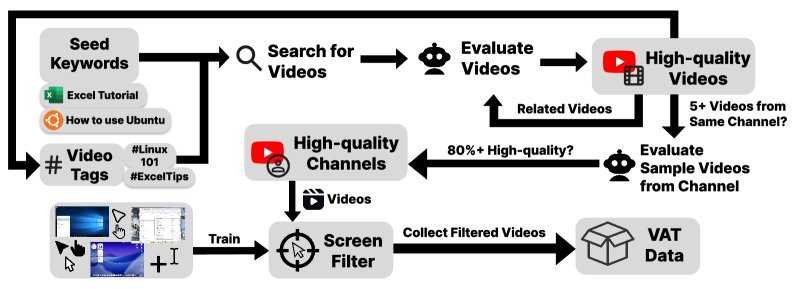 Starting from seed keywords and tags, videos are searched and evaluated, expanded to related videos and high-quality channels (pass rate $\geq$80%), and GUI-containing videos are iteratively collected for VAT.
Starting from seed keywords and tags, videos are searched and evaluated, expanded to related videos and high-quality channels (pass rate $\geq$80%), and GUI-containing videos are iteratively collected for VAT.
Video Preprocessing
To precisely extract GUI-interaction clips from candidate videos, this paper developed the \(GUI-Filter\) model. This is a lightweight cursor detection model based on YOLOv8x that can filter out non-interactive content such as slides. The specific filtering criterion is: clips lasting more than 6 consecutive seconds and with at least 80% of frames containing a cursor are retained. In the end, this tool successfully extracted 7,377 hours of valid GUI interaction recordings from 10,000 hours of raw video.
Data Analysis
The collected video data shows high quality in both resolution (97% are 720p or higher) and topic coverage. Analysis of titles and descriptions shows that the videos are mainly tutorials (69.6%), covering multiple domains such as operating systems, professional software, office work, and everyday applications, with operating system (OS)-related content accounting for the largest share (about 36%), ensuring both breadth and practicality of the data.
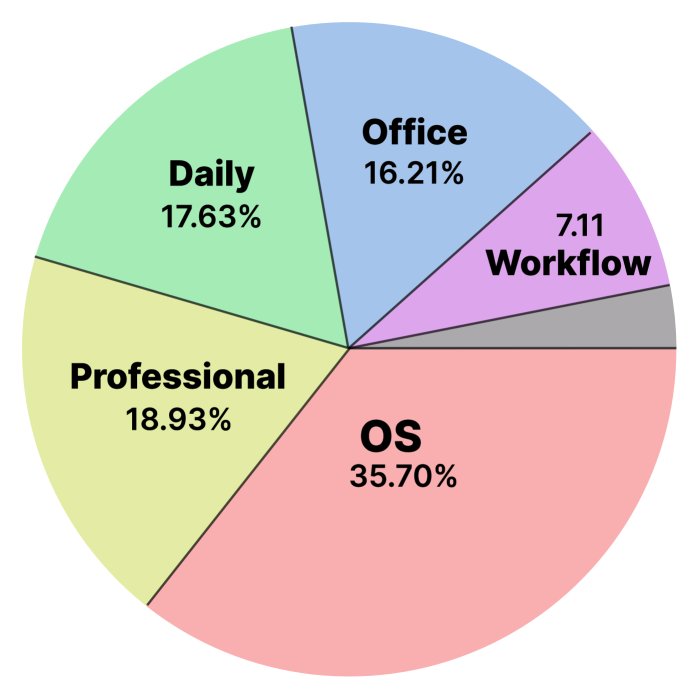 Domain distribution chart
Domain distribution chart
VADM: Inverse Dynamics Module
VADM is the technical core of this paper. It mimics the inverse dynamics idea in robotics, inferring the executed actions from observations (video pixels). Without manual annotation, this module can convert videos into structured \((screenshot, action, thought)\) sequences.
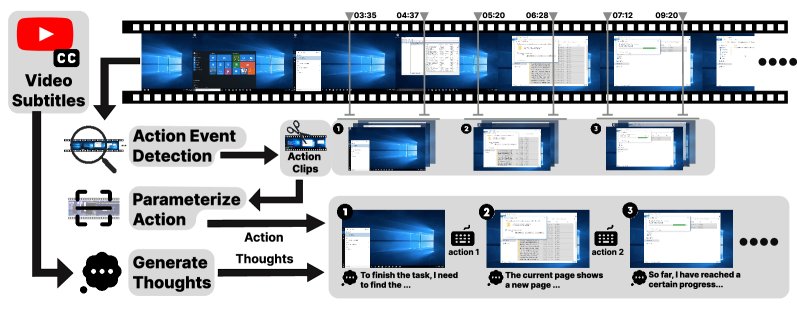 VADM pipeline: given a screen-recording video (optional subtitles), the module (1) detects GUI action events and segments clips, (2) parameterizes each action (type and parameters), and (3) generates step-level thoughts, ultimately producing a trainable {action clip, action, thought} sequence.
VADM pipeline: given a screen-recording video (optional subtitles), the module (1) detects GUI action events and segments clips, (2) parameterizes each action (type and parameters), and (3) generates step-level thoughts, ultimately producing a trainable {action clip, action, thought} sequence.
Action Event Detection
The goal of this stage is to perform dense event detection in the unlabeled video \(v\) and output a set of actions with precise start and end times \(S={(a_k, t_k^s, t_k^e)}_k=1^K\).
\[f_{\theta}(v) \rightarrow \mathcal{S}=\{(a_{k},t_{k}^{\mathrm{s}},t_{k}^{\mathrm{e}})\}_{k=1}^{K},\quad a_{k}\in\mathcal{A},\ 0\leq t_{k}^{\mathrm{s}}<t_{k}^{\mathrm{e}}\leq T.\]The paper uses the OpenCUA dataset to automatically generate timestamped GUI events as supervision data, and fully fine-tunes the Qwen2.5-VL-7B-Instruct model so that it can directly predict action types and their millisecond-level time boundaries from video.
Action Parameterization
After detecting the action clip $v_k=v[t_k^s:t_k^e]$, the goal of this stage is to identify the specific action parameters \(π_k\).
\[h_{\phi}(v_{k}) \rightarrow (\hat{a}_{k},\pi_{k}).\]For example, for a click action, the output is \((click, (x,y))\); for a typing action, the output is \((type, <content>)\). Similarly, the paper uses the original logs from OpenCUA to generate supervision data and fine-tunes the Qwen2.5-VL model so that it can directly decode the action type and specific parameters from video clips.
Inner Monologue Generation
To help the model learn the intent behind each action, this paper also generates a short “inner monologue” \(r_k\) for every action. By providing GPT-4.5 Medium with contextual information such as the action type, parameters, screenshots before and after the action, and related automatic speech recognition (ASR) text, the model generates a text that describes the intent and plan. This turns the final data format into a ReAct-like \((screenshot, thought, action, parameters)\) sequence, which helps improve the model’s planning and reasoning abilities.
Pretraining Computer-Use Models
This paper adopts a two-stage training strategy to validate the effectiveness of the VideoAgentTrek data.
Data Preparation
- VideoAgentTrek data: 39,000 videos were processed through the above pipeline, generating about 15.2 million interaction steps (about 26 billion tokens).
- Human-annotated data: Human-labeled trajectories from public datasets such as OpenCUA and AGUVIS were integrated, totaling about 8 billion tokens.
- GUI localization data: Localization pairs from the OSWorld-G dataset were introduced to enhance the model’s perception of interface elements, totaling about 1 billion tokens.
Training Strategy
- Stage 1: Continued pretraining: The large-scale, diverse, but potentially noisy data generated by VideoAgentTrek is used to pretrain the Qwen2.5-VL-7B model. The goal of this stage is to let the model learn broad GUI interaction patterns and visual foundations.
- Stage 2: Supervised fine-tuning (SFT): Fine-tuning is performed on a small amount of high-quality, human-annotated data. The goal of this stage is to sharpen the model’s policy execution and instruction-following abilities on specific tasks.
This “learn broadly first, then refine carefully” strategy aims to fully leverage the breadth of large-scale video data to build robust foundational capabilities, and then use the precision of high-quality labeled data to optimize higher-level policies.
Experimental Results
This paper validates the effectiveness of the method on two mainstream computer-use intelligent agent benchmarks: OSWorld-Verified (online real-world environment) and AgentNetBench (offline evaluation).
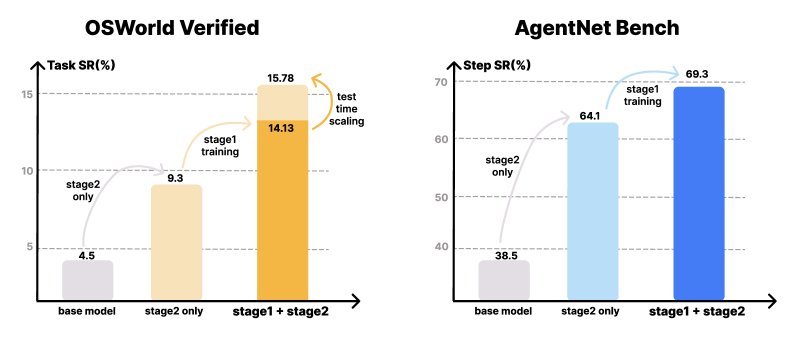 Experimental results on OSWorld-Verified and AgentNetBench. VideoAgentTrek shows significant improvements over the baseline model, and test-time scaling in the number of steps brings additional performance gains.
Experimental results on OSWorld-Verified and AgentNetBench. VideoAgentTrek shows significant improvements over the baseline model, and test-time scaling in the number of steps brings additional performance gains.
Main Results:
- Significant improvements in both online and offline performance: On AgentNetBench, after adding video pretraining, the model’s single-step success rate improved from the baseline’s 64.1% to 69.3%. In the more challenging online environment OSWorld-Verified, the task success rate increased substantially from 9.3% with SFT only to 15.8% (with a 50-step budget), a relative improvement of 70%. This demonstrates that the knowledge transfer brought by video pretraining is effective, especially in online environments that require handling real-world visual changes.
- Performance scales with data size: Experiments show that as the amount of video data used in the pretraining stage increases from 0% to 100%, the model’s final performance improves steadily on both benchmarks, validating the scalability of the VideoAgentTrek method.
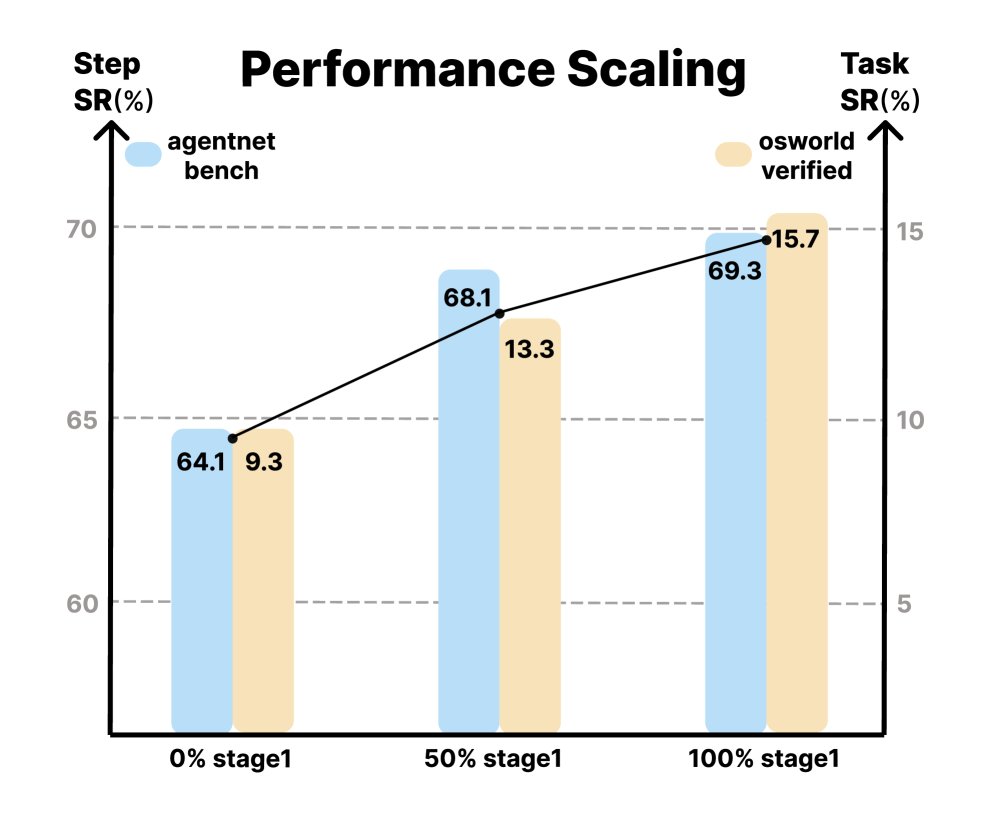 Performance scaling
Performance scaling
- Improved long-horizon planning ability: The trajectories generated by VideoAgentTrek have an average length of 39.25 steps, far exceeding existing datasets. Pretraining on such long trajectories brings clear benefits: in OSWorld-Verified, when the allowed number of interaction steps increases from 20 to 50, the task success rate of the video-pretrained model rises from 14.13% to 15.78%, showing effective test-time scaling. In contrast, the model trained only with SFT shows no further improvement, indicating that it lacks the ability to use extra steps for exploration and error correction.
- Reliable VADM module performance: The action event detector in VADM performs well on the held-out test set, achieving an overall precision of 0.88 and a recall of 0.71, with especially strong recognition of visually distinctive actions such as clicking and scrolling. Although the action parameterization module is difficult to evaluate automatically, manual blind review found that its predicted parameters are accurate and executable in most cases, sufficient for constructing effective training trajectories.
| Action Event Detector Evaluation (Held-out Test Set) | ||
|---|---|---|
| Action Type | F1 Score | Precision |
| Click | 0.817 | 0.949 |
| Drag | 0.449 | 0.583 |
| Press | 0.449 | 0.596 |
| Scroll | 0.840 | 0.985 |
| Type | 0.771 | 0.902 |
| Micro Avg. | 0.784 | 0.879 |
| Action Parameterization Evaluation (Manual Blind Review) | ||
|---|---|---|
| Action Type | Number Evaluated | Accuracy |
| Click | 324 | 0.713 |
| Drag | 22 | 0.366 |
| Press | 47 | 0.362 |
| Scroll | 34 | 0.735 |
| Type | 73 | 0.671 |
Final Conclusion: The experimental results strongly demonstrate that the large amount of passive screen-recording video available on the internet can be successfully transformed into high-quality supervision signals, providing a scalable and effective path for training more powerful and robust computer-use intelligent agents, and serving as a viable alternative to expensive human annotation.