Unifying Large Language Models and Knowledge Graphs: A Roadmap
-
ArXiv URL: http://arxiv.org/abs/2306.08302v3
-
Authors: Linhao Luo; Jiapu Wang; Chen Chen; Xindong Wu; Shirui Pan; Yufei Wang
-
Affiliations: Beijing University of Technology; Griffith University; Hefei University of Technology; Monash University; Nanyang Technological University; Zhejiang Lab
Introduction
Large Language Models (LLMs), such as ChatGPT and GPT-4, have sparked a new wave in natural language processing and artificial intelligence due to their emergent capabilities and generalization. However, LLMs are black-box models and often struggle to capture and access factual knowledge. In contrast, Knowledge Graphs (KGs) are structured knowledge models that explicitly store rich entity knowledge. KGs can enhance the reasoning ability and interpretability of LLMs by providing external knowledge. At the same time, KGs themselves face difficulties in construction and evolution, making it hard for existing methods to generate new facts and represent unseen knowledge. Therefore, unifying LLMs and KGs and leveraging their strengths in a complementary way is both necessary and mutually beneficial.
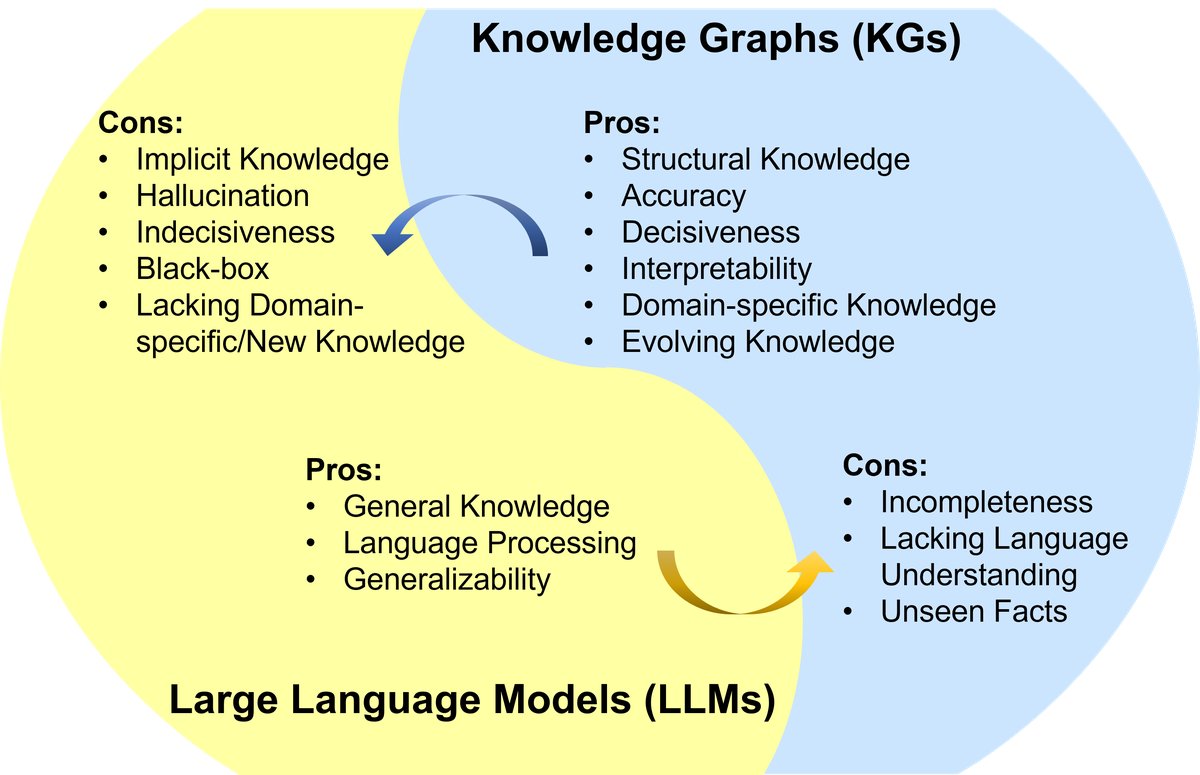
Figure 1: Summary of the strengths and weaknesses of LLMs and KGs. LLM strengths: general knowledge, language processing, generalization ability; LLM weaknesses: implicit knowledge, hallucination, uncertainty, black box, lack of domain/new knowledge. KG strengths: structured knowledge, accuracy, determinism, interpretability, domain-specific knowledge, evolvable knowledge; KG weaknesses: incompleteness, lack of language understanding, inability to handle unseen facts.
This article aims to provide a forward-looking roadmap for unifying LLMs and KGs. The roadmap includes three general frameworks:
- KG-enhanced LLMs: Incorporating KGs into the pretraining and inference stages of LLMs, or using them to improve understanding of the knowledge learned by LLMs.
- LLM-augmented KGs: Using LLMs to handle various KG tasks, such as embedding, completion, construction, graph-to-text generation, and question answering.
- Synergized LLMs + KGs: LLMs and KGs play equally important roles and work in a mutually beneficial way to achieve bidirectional reasoning driven by both data and knowledge, jointly enhancing each other.
This article reviews and summarizes existing work under these three frameworks and points out future research directions.
Background
Large Language Models (LLMs)
LLMs are language models pretrained on large-scale corpora and have shown excellent performance across a variety of natural language processing (NLP) tasks. Most LLMs originate from the Transformer architecture, which uses the self-attention mechanism to empower its encoder and decoder modules.
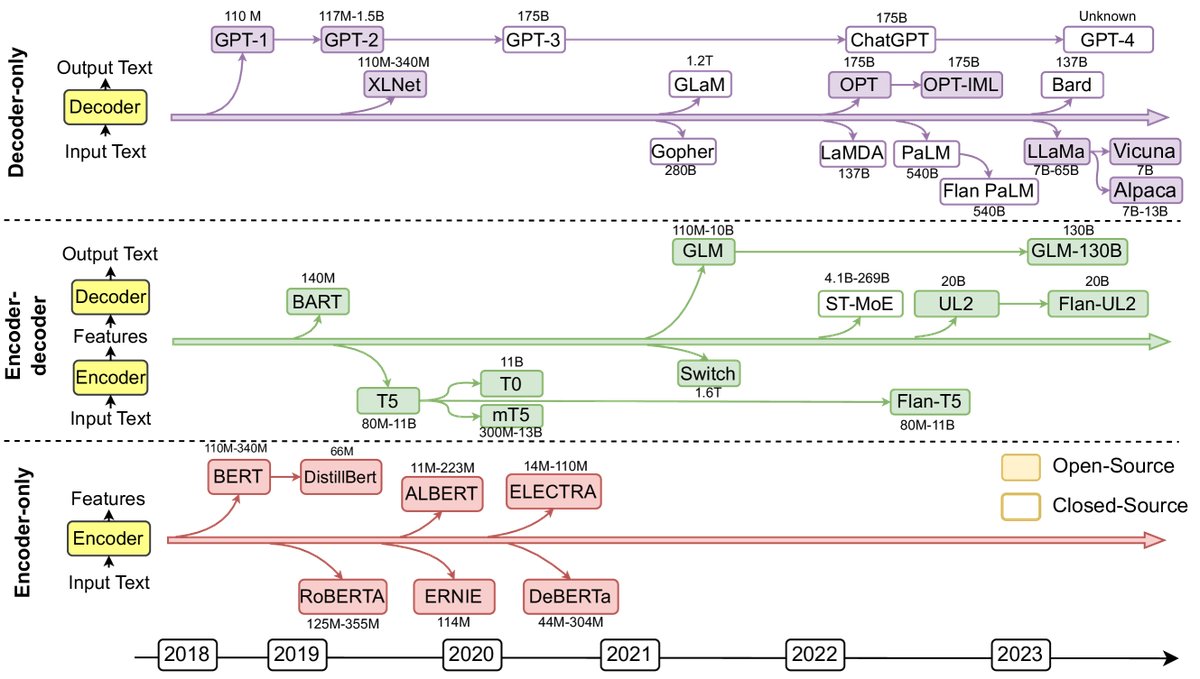
Figure 2: Representative Large Language Models (LLMs) in recent years. Solid squares indicate open-source models, and hollow squares indicate closed-source models.
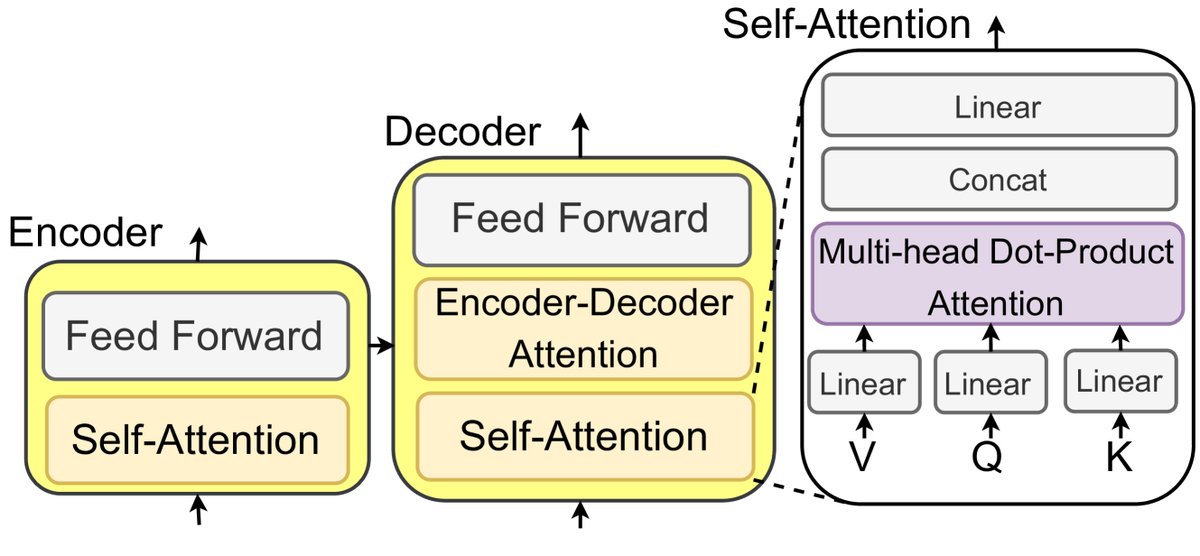
Figure 3: An illustration of an LLM based on Transformer and self-attention mechanisms.
According to their architecture, LLMs can be divided into three categories:
- Encoder-only LLMs: Such as BERT and RoBERTa, used to understand the entire sentence and suitable for tasks like text classification and named entity recognition.
- Encoder-decoder LLMs: Such as T5 and GLM-130B, used to generate text based on context and suitable for tasks like summarization, translation, and question answering.
- Decoder-only LLMs: Such as the GPT series and LLaMA, used to predict the next word based on preceding text, and capable of performing downstream tasks with only a few examples or instructions.
Prompt Engineering
Prompt engineering is an emerging field that maximizes LLM performance in various applications by designing and optimizing prompts. A prompt usually contains an Instruction, Context, and Input Text. For example, Chain-of-thought (CoT) prompting guides the model to perform intermediate-step reasoning to solve complex tasks. Prompt engineering also makes it possible to integrate structured data such as KGs into LLMs, for example by linearizing a KG into text passages through templates.
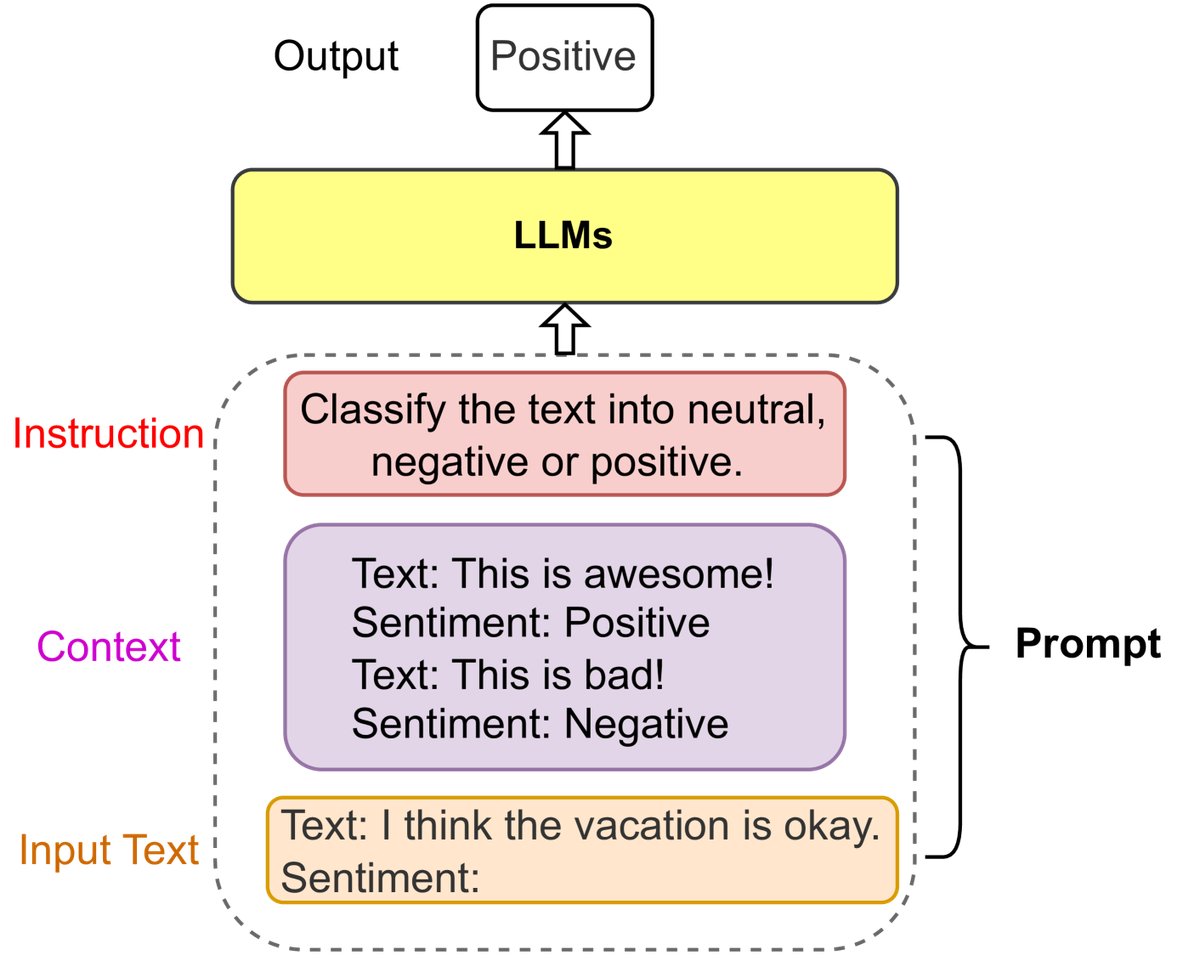
Figure 4: An example of a sentiment classification prompt.
Knowledge Graphs (KGs)
Knowledge graphs store structured knowledge in the form of triples $\mathcal{KG}={(h,r,t)\subseteq\mathcal{E}\times\mathcal{R}\times\mathcal{E}}$, where $\mathcal{E}$ is the entity set and $\mathcal{R}$ is the relation set.
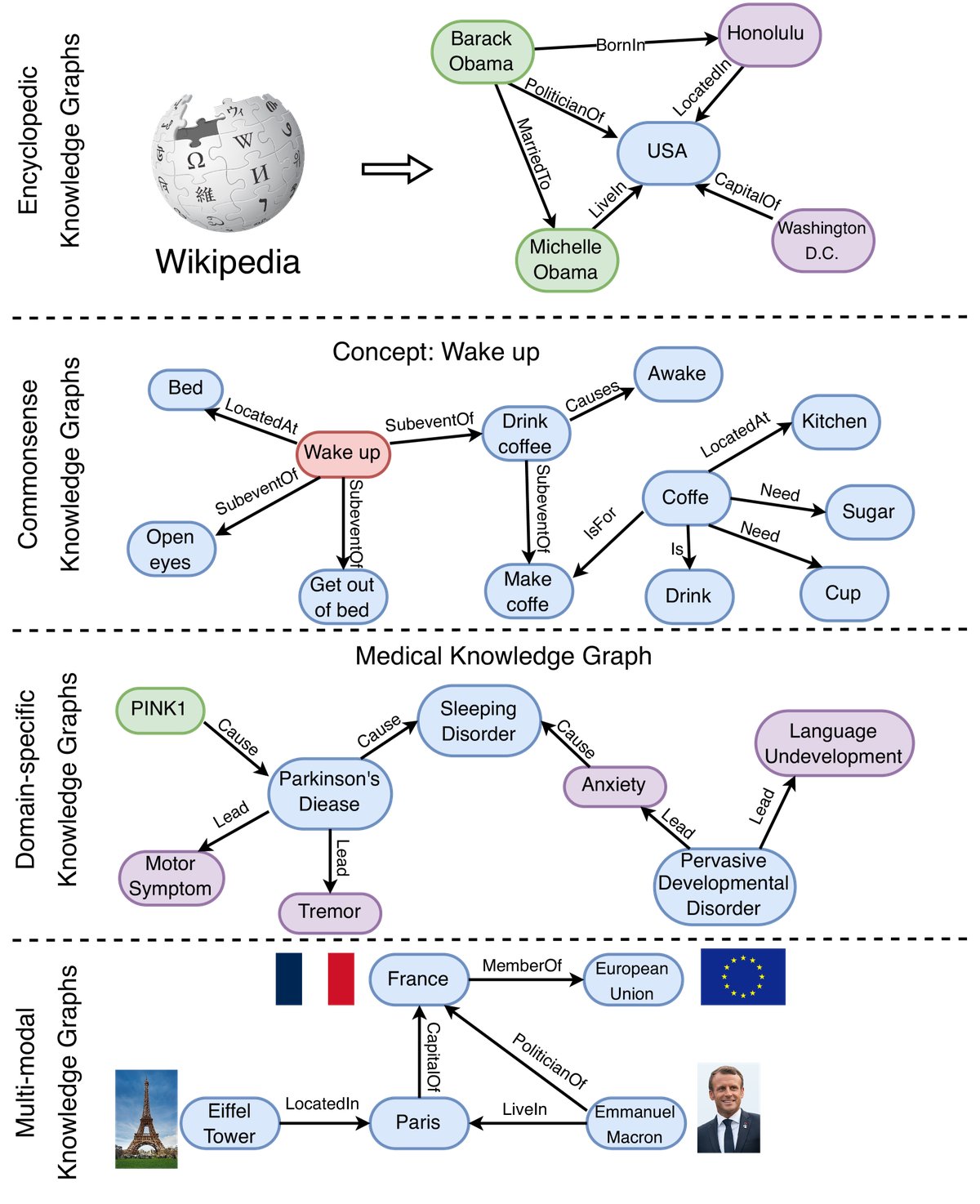
Figure 5: Examples of different types of knowledge graphs, including encyclopedic knowledge graphs, commonsense knowledge graphs, domain knowledge graphs, and multi-modal knowledge graphs.
According to the type of information they store, KGs can be divided into four categories:
- Encyclopedic KGs: Represent general knowledge in the real world, such as Wikidata, Freebase, and YAGO. They are usually built from large information sources such as Wikipedia.
- Commonsense KGs: Store knowledge about everyday concepts, objects, and events, as well as their relationships, such as ConceptNet and ATOMIC.
- Domain-specific KGs: Represent knowledge in specific domains, such as UMLS in medicine, finance, biology, and more. These KGs are smaller in scale but more accurate and reliable.
- Multi-modal KGs: Represent facts using multiple modalities, such as images and audio, for example IMGpedia and MMKG.
Applications
LLMs and KGs have been widely applied in a variety of real-world applications.
| Name | Category | LLMs | KGs | Link |
|---|---|---|---|---|
| ChatGPT/GPT-4 | Chatbot | ✓ | \(https://shorturl.at/cmsE0\) | |
| ERNIE 3.0 | Chatbot | ✓ | ✓ | \(https://shorturl.at/sCLV9\) |
| Bard | Chatbot | ✓ | ✓ | \(https://shorturl.at/pDLY6\) |
| Firefly | Image editing | ✓ | \(https://shorturl.at/fkzJV\) | |
| AutoGPT | AI assistant | ✓ | \(https://shorturl.at/bkoSY\) | |
| Copilot | Coding assistant | ✓ | \(https://shorturl.at/lKLUV\) | |
| New Bing | Web search | ✓ | \(https://shorturl.at/bimps\) | |
| Shop.ai | Recommendation system | ✓ | \(https://shorturl.at/alCY7\) | |
| Wikidata | Knowledge base | ✓ | \(https://shorturl.at/lyMY5\) | |
| KO | Knowledge base | ✓ | \(https://shorturl.at/sx238\) | |
| OpenBG | Recommendation system | ✓ | \(https://shorturl.at/pDMV9\) | |
| Doctor.ai | Health assistant | ✓ | ✓ | \(https://shorturl.at/dhlK0\) |
Table I: Representative applications using LLMs and KGs.
Roadmap and Taxonomy
This section presents a clear roadmap for unifying LLMs and KGs and categorizes related research.
Roadmap
The roadmap proposed in this article identifies three frameworks for unifying LLMs and KGs.
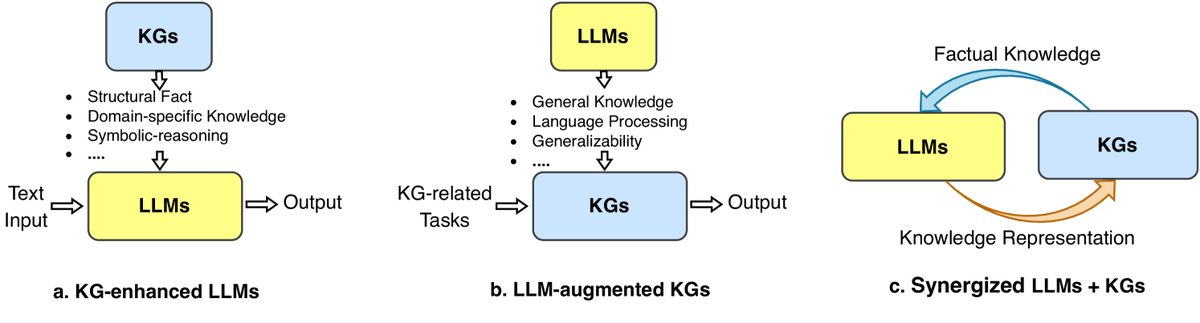
Figure 6: A general roadmap for unifying KGs and LLMs. (a) KG-enhanced LLMs. (b) LLM-augmented KGs. (c) Synergized LLMs + KGs.
-
KG-enhanced LLMs (KG-enhanced LLMs): To address the issues of hallucination and lack of interpretability in LLMs, KGs are used to enhance LLMs. The explicit structured knowledge in KGs can be injected into an LLM during pre-training, or used as an external knowledge source during inference, thereby improving the knowledge-awareness and interpretability of LLMs.
-
LLM-augmented KGs (LLM-augmented KGs): To address problems such as incompleteness and difficulty in construction in KGs, LLMs’ strong generalization ability is leveraged to solve KG-related tasks. LLMs can serve as text encoders to enrich KG representations, or be used to extract entity relations from raw corpora to build KGs.
-
Synergized LLMs + KGs (Synergized LLMs + KGs): This is a unified framework designed to enable LLMs and KGs to mutually promote and work collaboratively.
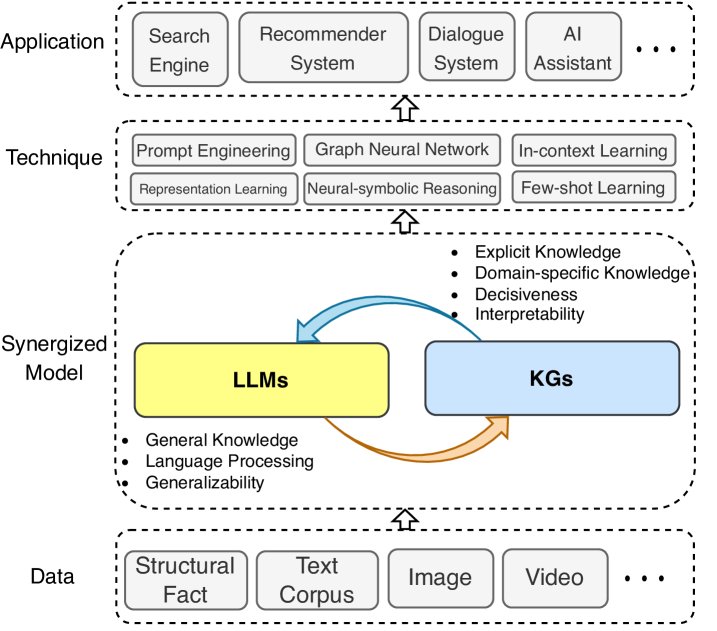
Figure 7: A general framework for synergized LLMs + KGs, consisting of four layers: 1) data layer, 2) synergized model layer, 3) technique layer, and 4) application layer.
This synergistic framework contains four layers:
- Data: LLMs process text data, KGs process structured data, and it can be extended to multimodal data.
- Synergized Model: LLMs and KGs collaborate at this layer to enhance capabilities.
- Technique: Relevant techniques that integrate LLMs and KGs are incorporated to further improve performance.
- Application: The integrated model is applied to real-world applications such as search engines, recommendation systems, and AI assistants.
Taxonomy
To better understand research on unifying LLMs and KGs, this article provides a fine-grained taxonomy for each framework.
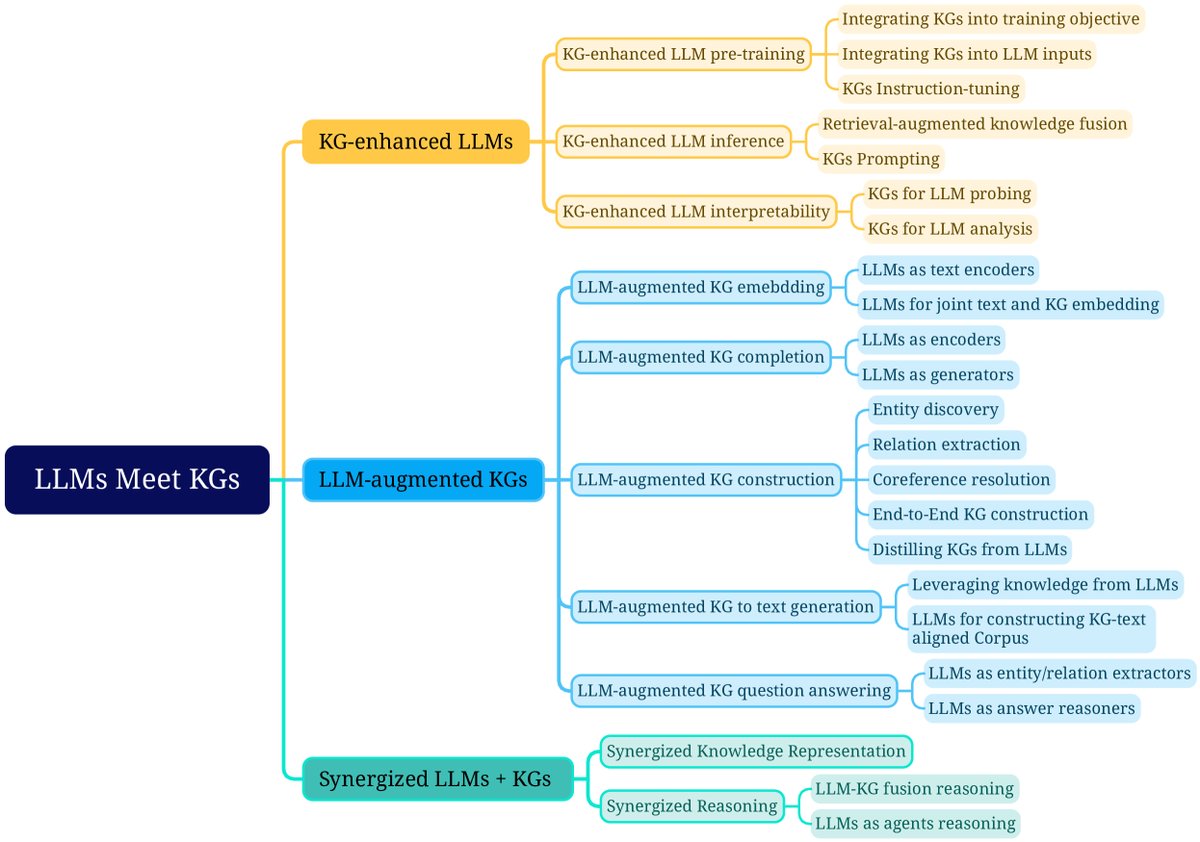
Figure 8: Fine-grained taxonomy of research on unifying LLMs and KGs.
KG-enhanced LLMs
Research under this framework is divided into three categories:
- KG-enhanced LLM pre-training: Apply KGs during the pre-training stage to improve the knowledge representation ability of LLMs.
- KG-enhanced LLM inference: Use KGs during inference so that LLMs can access up-to-date knowledge without retraining.
- KG-enhanced LLM interpretability: Use KGs to understand the knowledge learned by LLMs and explain their reasoning process.
LLM-augmented KGs
Research under this framework is divided into five categories according to task type:
- LLM-augmented KG embedding: Apply LLMs to enrich KG representations by encoding textual descriptions.
- LLM-augmented KG completion: Use LLMs to encode text or generate facts to improve KG completion performance.
- LLM-augmented KG construction: Apply LLMs to handle tasks such as entity discovery and relation extraction to build KGs.
- LLM-augmented graph-to-text generation: Use LLMs to generate natural language text that describes KG facts.
- LLM-augmented KG question answering: Use LLMs to connect natural language questions with answers in KGs.
Synergized LLMs + KGs
This article reviews recent attempts at synergized LLMs + KGs from two perspectives: knowledge representation and reasoning.
Knowledge Graph-Enhanced Large Language Models
To address the shortcomings of LLMs, such as lacking factual knowledge and being prone to factual errors, researchers have proposed integrating KGs to enhance LLMs. The table below summarizes typical KG-enhanced LLM methods.
| Task | Method | Year | KG Type | Technique |
|---|---|---|---|---|
| KG-enhanced LLM pre-training | ERNIE [35] | 2019 | E | Integrate KG into training objectives |
| GLM [102] | 2020 | C | Integrate KG into training objectives | |
| Ebert [103] | 2020 | D | Integrate KG into training objectives | |
| KEPLER [40] | 2021 | E | Integrate KG into training objectives | |
| WKLM [106] | 2020 | E | Integrate KG into training objectives | |
| K-BERT [36] | 2020 | E + D | Integrate KG into language model input | |
| CoLAKE [107] | 2020 | E | Integrate KG into language model input | |
| ERNIE3.0 [101] | 2021 | E + D | Integrate KG into language model input | |
| KP-PLM [109] | 2022 | E | KG instruction-tuning | |
| RoG [112] | 2023 | E | KG instruction-tuning | |
| KG-enhanced LLM inference | KGLM [113] | 2019 | E | Retrieval-augmented knowledge fusion |
| REALM [114] | 2020 | E | Retrieval-augmented knowledge fusion | |
| RAG [92] | 2020 | E | Retrieval-augmented knowledge fusion | |
| Li et al. [64] | 2023 | C | KG prompting | |
| Mindmap [65] | 2023 | E + D | KG prompting | |
| KG-enhanced LLM interpretability | LAMA [14] | 2019 | E | KG for LLM probing |
| LPAQA [118] | 2020 | E | KG for LLM probing | |
| KagNet [38] | 2019 | C | KG for LLM analysis | |
| knowledge-neurons [39] | 2021 | E | KG for LLM analysis |
Table II: Summary of KG-enhanced LLM methods. E: encyclopedic knowledge graph, C: commonsense knowledge graph, D: domain knowledge graph.
KG-enhanced LLM Pre-training
There are three main ways to incorporate KGs into LLM pre-training:
1. Integrating KGs into training objectives
This line of work focuses on designing knowledge-aware training objectives.
- Entity-based objective design: ERNIE proposed a text-knowledge alignment training objective, enabling the model to learn alignment relationships between text tokens and KG entities. KEPLER combines the objectives of knowledge graph embedding and masked language modeling in a shared encoder for training. WKLM injects knowledge by replacing entities in text and asking the model to determine whether they have been replaced.
- Graph-structure-based objective design: GLM uses the graph structure of KGs to assign different masking probabilities to entities, with nearby entities having a higher chance of being masked.
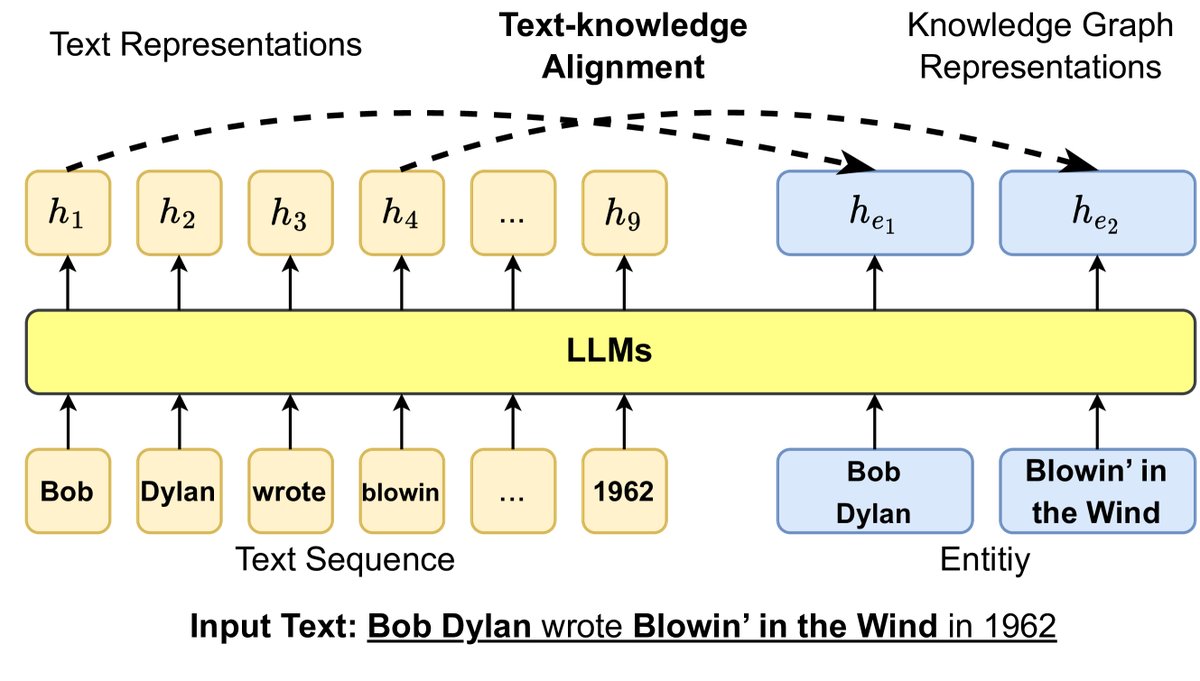
Figure 9: Injecting KG information into LLM training objectives through a text-knowledge alignment loss, where $h$ denotes the hidden representation generated by the LLM.
2. Integrating KGs into LLM input
This line of work introduces relevant knowledge subgraphs into the input of LLMs.
- Avoiding knowledge noise: Directly serializing KG triples and concatenating them with sentences, as in ERNIE 3.0, may lead to “knowledge noise.” To address this, K-BERT designs a “visible matrix” so that tokens in a sentence can only see each other, while knowledge entities can additionally see triple information. CoLAKE constructs a unified word-knowledge graph that connects text tokens and KG entity nodes.
- Focusing on long-tail entities: DkLLM focuses on low-frequency and long-tail entities, replacing these entities with pseudo-token embeddings as new inputs to the LLM.
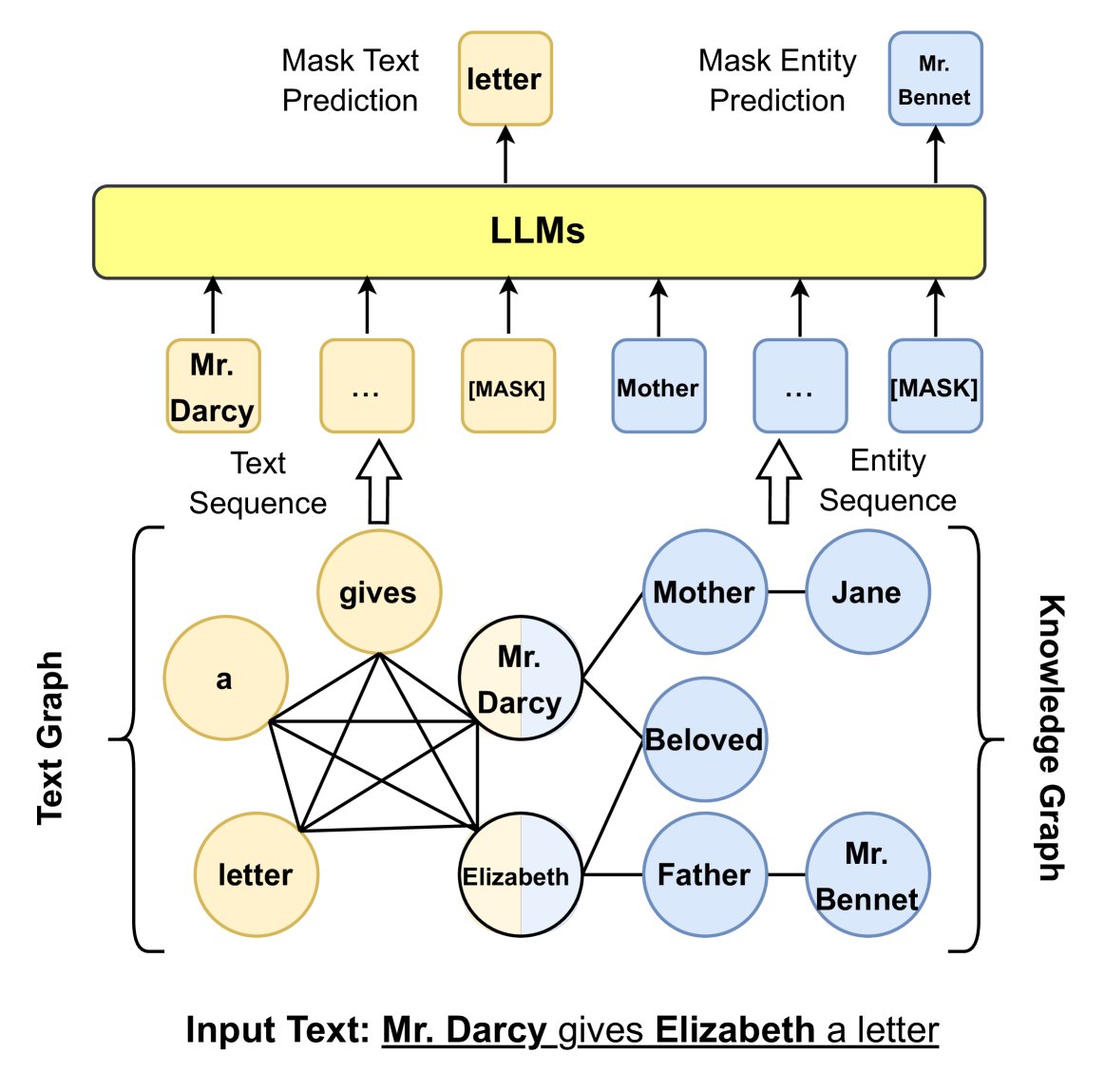
Figure 10: Injecting KG information into LLM input using graph structure.
3. KG instruction-tuning
This method aims to fine-tune LLMs so that they can better understand KG structures and follow instructions. It uses facts and structures from KGs to create instruction-tuning datasets. For example, KP-PLM designs templates that convert graph structures into natural language text and uses them to fine-tune the LLM. RoG fine-tunes the LLM to generate KG-based relation paths as planning, guiding the model toward faithful reasoning.
KG-enhanced LLM inference
Pre-training methods cannot update knowledge without retraining the model. Therefore, researchers have developed methods that inject knowledge at inference time, especially for question answering (QA) tasks that require up-to-date knowledge.
1. Retrieval-Augmented Knowledge Fusion
The core idea of this method is to retrieve relevant knowledge from a large corpus and then integrate it into the LLM.
- RAG models first retrieve relevant documents from a non-parametric knowledge base before generating an answer, and then feed these documents as additional context into a parametric Seq2Seq LLM.
- REALM integrates a knowledge retriever during the pretraining stage, enabling it to retrieve and attend to documents from a large corpus during both pretraining and fine-tuning.
- KGLM selects facts from the KG based on the current context to generate factual sentences.
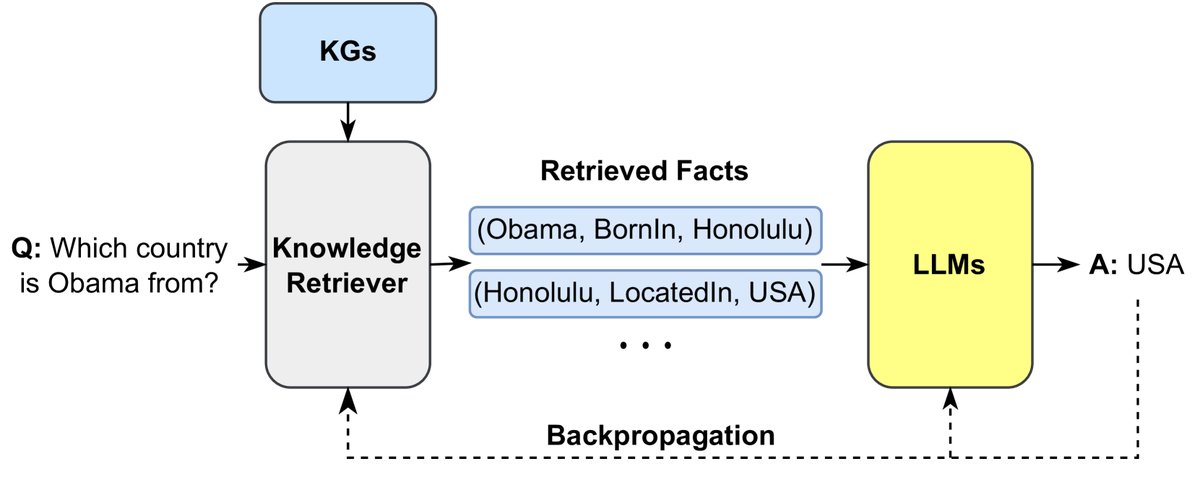
Figure 11: Retrieving external knowledge to enhance the generation process of LLMs.
2. KGs Prompting
This method aims to design sophisticated prompts that convert structured KGs into text sequences as context for LLMs.
- Li et al. use predefined templates to convert each triple into a short sentence.
- Mindmap designs a prompt that converts graph structures into a mind map, enabling the LLM to integrate facts from the KG with its own implicit knowledge for reasoning.
- CoK (Chain-of-Knowledge) proposes a knowledge-chain prompt that uses a series of triples to guide the LLM in step-by-step reasoning and ultimately derive the answer.
Comparison of Pretraining and Inference
- KG-enhanced LLM pretraining: This can deeply align knowledge representations with language context, allowing the LLM to learn how to use knowledge from scratch and often achieve state-of-the-art performance on knowledge-intensive tasks. However, the downside is that knowledge updates are costly, and it cannot handle dynamically changing or unseen new knowledge.
- KG-enhanced LLM inference: Knowledge can be updated easily by changing the inference input, making it better suited for new knowledge and new domains. However, the LLM itself may not have been sufficiently trained to effectively use these temporarily injected knowledge sources, which can lead to suboptimal performance.
Recommendation: For time-insensitive knowledge, such as common sense and reasoning, pretraining methods should be considered. For open-domain knowledge that changes frequently, inference-time enhancement methods are more appropriate.
Interpretability of KG-Enhanced LLMs
Although LLMs have achieved great success, their black-box nature and lack of interpretability remain widely criticized. Because of their structured and interpretable properties, KGs are used to improve the interpretability of LLMs. This mainly falls into two categories:
1. KGs for LLM Probing
LLM probing aims to understand the knowledge stored inside LLMs. LLMs implicitly store knowledge through training on large corpora, but it is difficult to know exactly what they have stored, and they also suffer from the problem of “hallucination.”
Figure 12: A general framework for probing language models using knowledge graphs.
LAMA is the first work to use KGs to probe LLM knowledge. As shown in Figure 12, LAMA first converts facts in the KG into cloze-style sentences through predefined prompt templates (for example, converting the triple \((Dante, born in, Florence)\) into the sentence “Dante was born in [MASK]”), and then asks the LLM to predict the masked entity. By comparing the LLM’s predictions with the ground-truth answers in the KG, the extent to which the LLM has mastered factual knowledge can be evaluated.