Sentence-Anchored Gist Compression for Long-Context LLMs
LLM Long-Text “Slimming” by 8x: A New Method Lets Models Read by Sentence, with Almost No Performance Loss
As models like Kimi and GPT-4 push their context windows into the millions of tokens, a practical problem confronts every AI practitioner: massive compute and memory costs. The expense of processing long text, especially the $O(n^2)$ self-attention mechanism in the Transformer architecture, has become a bottleneck limiting the widespread adoption of large models. Is there a way to “slim down” LLM context processing without sacrificing too much performance?
Paper Title: Sentence-Anchored Gist Compression for Long-Context LLMs ArXiv URL: http://arxiv.org/abs/2511.08128v1
Researchers from institutions including FusionBrainLab have proposed a new method called Sentence-Anchored Gist Compression. Through a clever design, it teaches the LLM to “distill summaries” while reading, achieving up to 8x KV cache compression with almost no performance drop on multiple long- and short-text benchmarks.
What Is Gist Token Compression?
To understand this technique, we first need to understand the concept of Gist Tokens (Gist Token or Beacon Token).
Imagine you are reading a thick book. You are unlikely to remember every word on every page. A more efficient approach is to write down one or two core summary sentences after finishing each chapter. When you need to review earlier content while reading later chapters, you only need to look at those summaries instead of rereading the entire chapter.
Gist Tokens play the role of “chapter summaries.” They are special learnable tokens used to summarize and compress the core information of a text segment. By inserting these Gist Tokens into the text, the model can condense the information of a long sequence into a few vectors, greatly reducing the burden of subsequent computation. It is a simple yet powerful idea, but the key question is: when should the summary be written, and how much is appropriate?
Core Innovation: The Art of Sentence-Anchored Compression
Previous methods usually adopt a fixed strategy, such as inserting one Gist Token every N tokens. This one-size-fits-all approach is simple, but it ignores the semantic structure of the text itself.
The biggest highlight of this paper is that it proposes a more intuitive, data-dependent strategy: insert a Gist Token at the end of each sentence.
Why sentences? Because sentences are natural, complete semantic units in language. Summarizing information at the end of a sentence is obviously more reasonable than breaking it at arbitrary positions. This approach aligns compression boundaries with semantic boundaries in the text, helping the model generate more meaningful and coherent “summaries.”
In practice, during text preprocessing, the model automatically identifies punctuation such as periods, question marks, and exclamation marks, and inserts $N_g$ learnable Gist Tokens after them (for example, 1, 2, or 4).
Unveiling the “Sentence Attention” Mechanism
To make Gist Tokens truly effective, the researchers designed a clever attention mask, which we call “sentence attention.” It redefines the visibility rules between different tokens in the model.
Let’s continue with the book-reading analogy:
- The view of Regular Tokens: When the model processes a word in a sentence, it can only “see” the other words within that sentence, as well as the Gist Tokens (summaries) of all previous sentences. It cannot directly look back at the original text of earlier sentences. This greatly reduces computation.
- The view of Gist Tokens (summaries): When the model generates the Gist Token for a sentence, it is given higher privileges. It can “see” all words in the current sentence, and it can also “see” the Gist Tokens (summaries) of all previous sentences. This ensures that the Gist Token can fully summarize the current sentence and inherit historical summaries.
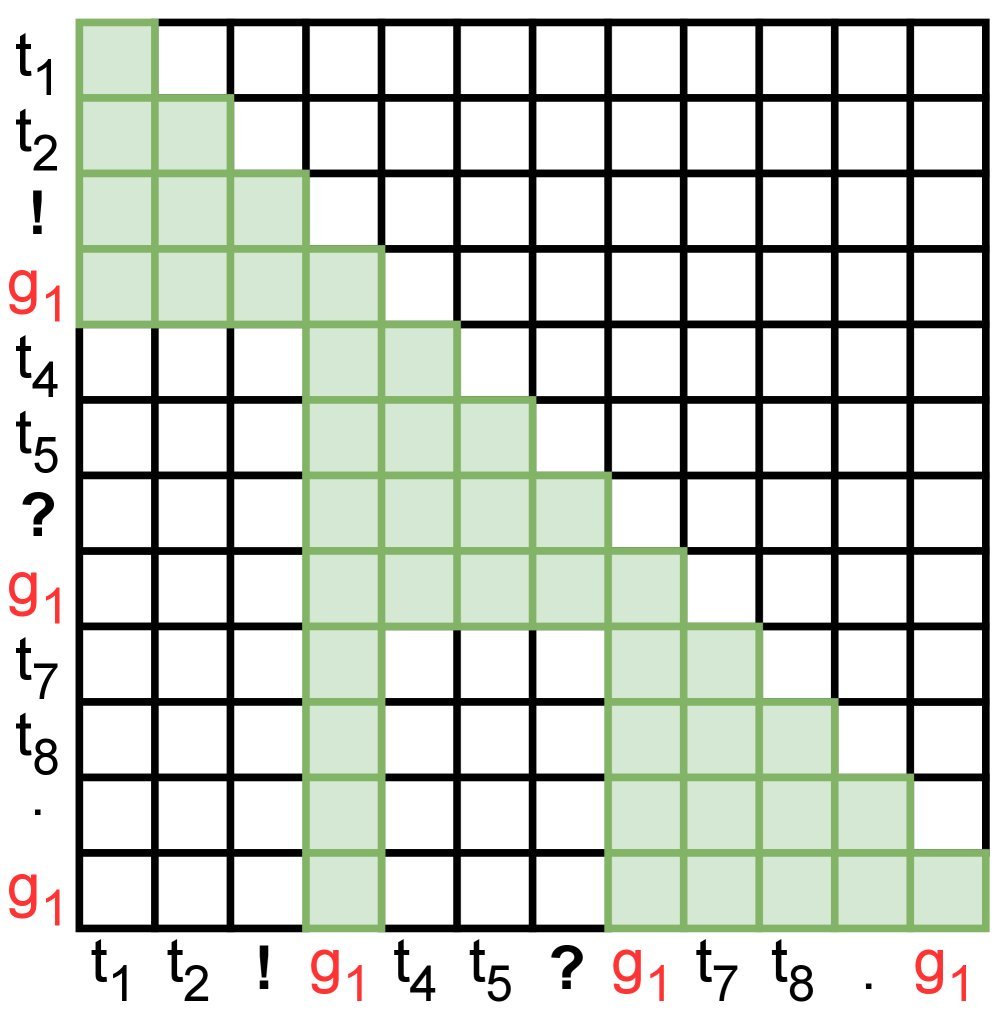 Figure 1: (a) Standard causal attention vs. (b) sentence attention. In sentence attention, regular tokens ($t_i$) only attend to in-sentence information and historical summaries ($g_1$), while the summary ($g_1$) aggregates information from the entire current sentence.
Figure 1: (a) Standard causal attention vs. (b) sentence attention. In sentence attention, regular tokens ($t_i$) only attend to in-sentence information and historical summaries ($g_1$), while the summary ($g_1$) aggregates information from the entire current sentence.
This design is implemented through a modified attention mask, without changing the core Transformer architecture, allowing efficient parallelism in both training and inference.
A Three-Step Training Strategy
To help the model stably learn this compression skill, the researchers adopted a carefully designed three-stage training method:
- Gist Token warm-up: Freeze the main parameters of the large model and train only the newly added Gist Tokens. Let these “summary pens” first learn how to capture information.
- Full-model fine-tuning: Unfreeze all parameters and fine-tune the entire model. Let the model learn how to effectively use these Gist Tokens for inference.
- Large-batch cooling: In the final stage, train with an ultra-large batch size to help the model converge more stably.
The entire training process uses only the standard language modeling objective, without introducing extra reconstruction losses like some other methods. The approach is very clean and simple.
Experimental Results: 8x Compression, No Performance Loss
The study conducted experiments based on the Llama3.2-3B model. The results are impressive:
On short-text benchmarks such as MMLU, the compressed model matches the original model’s performance, proving that this compression mechanism does not harm the model’s basic language and knowledge capabilities.
On long-text benchmarks such as HELMET, the model proposed in this paper (Sentence Llama) performs particularly well. Although its parameter count (3B) is only half that of other baseline models (such as Activation Beacon, 7B), its performance is on par with them, and even better on some tasks.
Table 2: Comparison on the long-text benchmark HELMET (tiny). Sentence Llama-3B ($N_g=4$) performs comparably to the 7B model.
More importantly, the compression ratio is key. When using 4 Gist Tokens per sentence ($N_g=4$), the method achieves an average KV cache compression ratio of about 6x on long-text tasks. By comparison, the similar Activation Beacon model achieves only 2x compression. This means that with a smaller model and less GPU memory, the same complex long-text tasks can be handled.
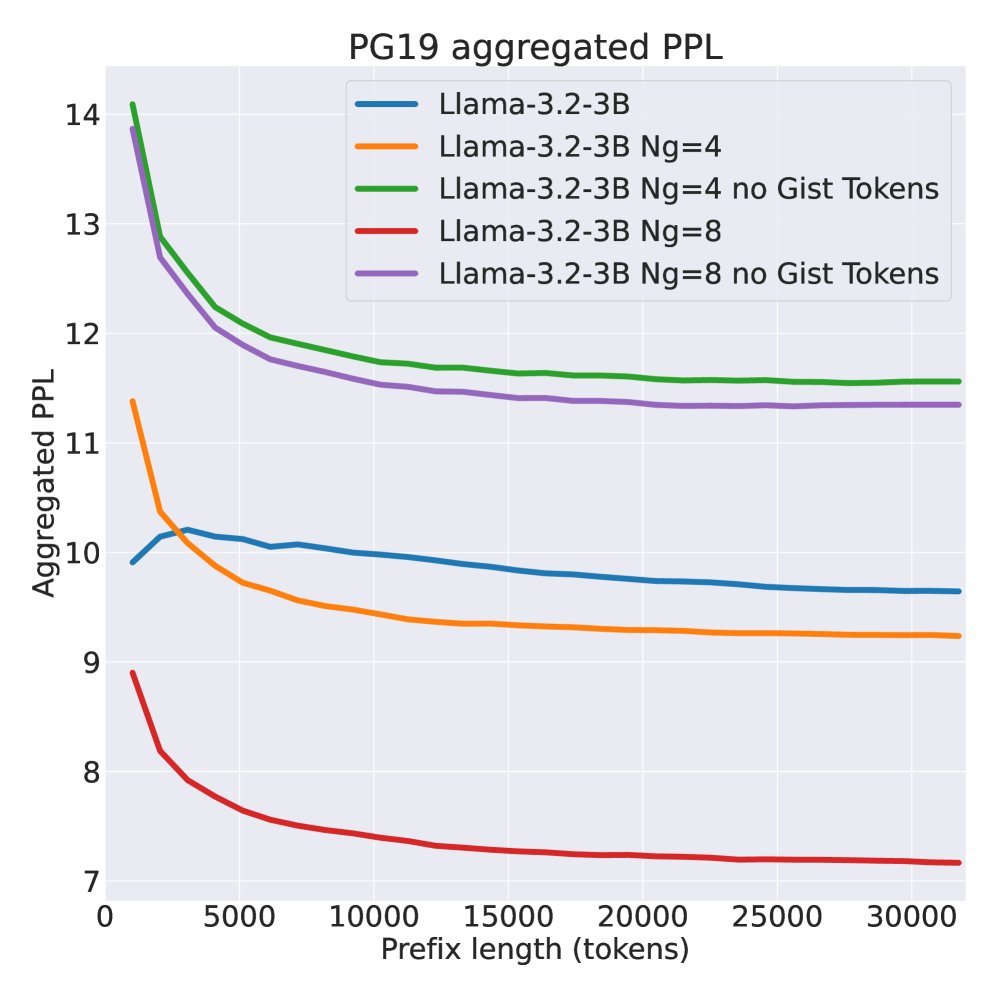 Figure 2: Perplexity on the PG19 dataset. The overall perplexity of the compressed model (solid blue/orange lines) is even lower than the baseline, showing its strong modeling ability.
Figure 2: Perplexity on the PG19 dataset. The overall perplexity of the compressed model (solid blue/orange lines) is even lower than the baseline, showing its strong modeling ability.
Conclusion and Limitations
Sentence-Anchored Gist Compression provides an elegant and efficient solution to the efficiency problem of long-text processing in LLMs. By aligning compression points with sentence semantic boundaries and designing a simple attention mechanism and training pipeline, it achieves high compression while maintaining strong performance.
Of course, this study also has some limitations. For example, all experiments are currently based on a 3B model, and its scalability to larger models remains to be verified. In addition, because the method relies on punctuation, its performance is relatively sensitive to the regularity of text formatting.
Even so, this work undoubtedly points to a highly promising path for developing more economical and easier-to-deploy long-context large models. It tells us that the most efficient compression may be hidden in the most basic structures of language itself.