Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding
-
ArXiv URL: http://arxiv.org/abs/2510.15253v1
-
Authors: Weihua Luo; Yong Xien Chng; Sensen Gao; Qing-Guo Chen; Shanshan Zhao; Kaifu Zhang; Mingming Gong; Jia-Wang Bian; Xu Jiang; Lunhao Duan
-
Publishing Institutions: Alibaba International Digital Commerce Group; MBZUAI; Tsinghua University; University of Melbourne; Wuhan University
Introduction
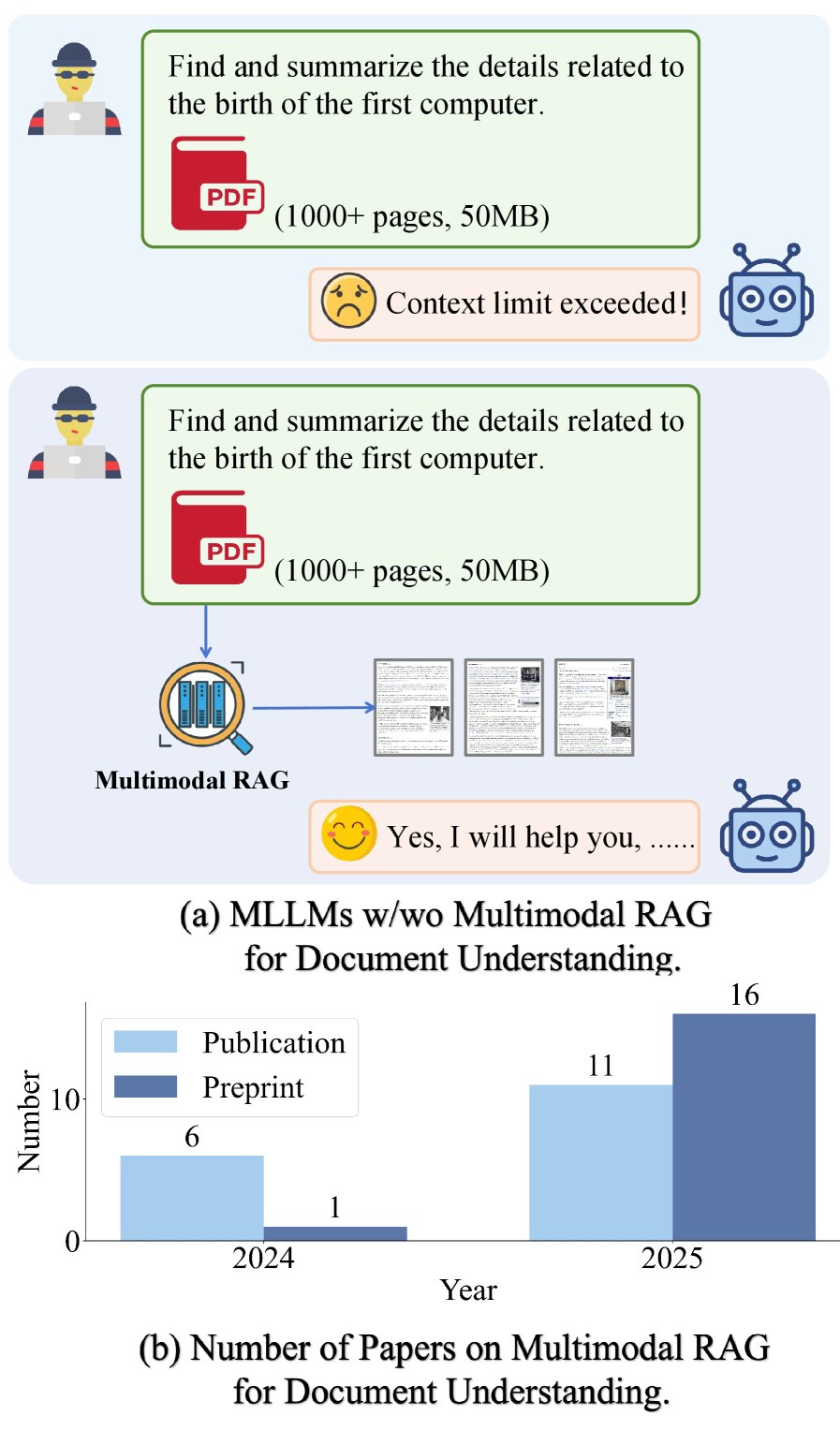 (a) Comparison of multimodal large language models (MLLMs) with and without multimodal RAG in long-document understanding tasks. (b) Growth in related publications from 2024 to 2025.
(a) Comparison of multimodal large language models (MLLMs) with and without multimodal RAG in long-document understanding tasks. (b) Growth in related publications from 2024 to 2025.
Document understanding is a key task in the information age, enabling machines to automatically interpret, organize, and reason over massive amounts of unstructured and semi-structured documents. Early research mainly focused on text-centric documents, relying on optical character recognition (OCR) technology for layout analysis and key information extraction. However, documents in real-world scenarios, especially those in the scientific domain, are often visually rich and contain complex elements such as tables, charts, and images. With the rapid development of large language models (LLM), the demand for understanding complex and diverse documents is growing rapidly.
In the field of visually rich document understanding, a variety of methods have emerged to integrate layout, text, and structural information. Native multimodal large language model (Multimodal LLM, MLLM) approaches typically represent documents as long image sequences, but this runs into sequence-length limits and hallucination risks when processing long documents of hundreds of pages. To improve modularity and robustness, Agent-based methods introduce specialized intelligent agents to handle subtasks, but this increases system complexity. Retrieval-Augmented Generation (RAG) enhances model responses with external knowledge, but traditional RAG is mainly designed for text.
To address the shortcomings of text RAG in handling visually rich documents, namely its inability to fully capture cross-modal cues and structural semantics, recent research has shifted toward multimodal RAG (Multimodal RAG). These methods achieve holistic document retrieval and reasoning through finer-grained modeling (such as tables and charts), graph-structured indexing, and multi-agent frameworks. Although there have been many surveys on RAG and document understanding, few studies explicitly connect the two. This paper aims to fill that gap by providing the first systematic survey of multimodal RAG for document understanding, proposing a taxonomy based on domain, retrieval modality, granularity, and hybrid enhancement methods, and organizing related datasets, benchmarks, and future challenges to provide a roadmap for the future of document AI.
Preliminaries
In a RAG system, the system first retrieves a set of relevant document pages and then generates a response based on that evidence. Retrieval can be closed-domain (limited to a single source document) or open-domain (searching a large corpus). Suppose the candidate pool is $D={d_i}_{i=1}^{N}$, where each document $d_i$ may contain raster images as well as OCR text $T_i$. Using modality-specific encoders, the query and documents are mapped into a shared embedding space.
The query $q$ is usually text, so text-text and text-image similarities are computed in the shared space. The embedding representations of the documents and query are $z_{i}^{\mathrm{img}}=\mathrm{Enc}_{\mathrm{img}}(d_{i})$, $z_{i}^{\mathrm{text}}=\mathrm{Enc}_{\mathrm{text}}(T_{i})$, and $e_{q}^{\mathrm{text}}=\mathrm{Enc}_{\mathrm{text}}(q)$. The similarity between the two modality pairs is computed by inner product: $s_{\mathrm{text}}(e_{q},z_{i})=\langle e_{q}^{\mathrm{text}},z_{i}^{\mathrm{text}}\rangle$ and $s_{\mathrm{img}}(e_{q},z_{i})=\langle e_{q}^{\mathrm{text}},z_{i}^{\mathrm{img}}\rangle$.
Pure Visual Retrieval
When only the image channel is used, documents are ranked according to the score $s_{\mathrm{img}}(e_q, z_i)$, and documents exceeding the threshold $\tau_{\mathrm{img}}$ are selected (or the top-K results are taken):
\[X_{\mathrm{img}}=\left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{img}}(e_{q},z_{i})\geq\tau_{\mathrm{img}}\,\right\}.\]Joint Visual-Text Retrieval
Two common strategies:
-
Confidence-weighted fusion: image and text scores are combined using a convex weight $\lambda_i \in [0,1]$, which reflects the confidence in the image modality for item $d_i$.
\[s_{\mathrm{conf}}(e_{q},z_{i}) = \lambda_{i}\,s_{\mathrm{img}}(e_{q},z_{i}) + \bigl(1-\lambda_{i}\bigr)\,s_{\mathrm{text}}(e_{q},z_{i}),\] \[X_{\mathrm{conf}} = \left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{conf}}(e_{q},z_{i})\geq\tau_{\mathrm{conf}}\,\right\}.\] -
Independent retrieval followed by merging: first retrieve pages independently using each modality, then take the union of the results.
\[X_{\mathrm{img}} = \left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{img}}(e_{q},z_{i})\geq\tau_{\mathrm{img}}\,\right\},\] \[X_{\mathrm{text}} = \left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{text}}(e_{q},z_{i})\geq\tau_{\mathrm{text}}\,\right\},\] \[X_{\cup} = X_{\mathrm{img}}\cup X_{\mathrm{text}}.\]
Generation
The generator $\mathcal{G}$ produces the final response $r$ based on the original query $q$ and the retrieved context $X$ (which can be $X_{\mathrm{img}}$, $X_{\mathrm{conf}}$, or $X_{\cup}$).
\[r=\mathcal{G}(q,X).\]Key Innovations and Methodology
This paper systematically categorizes and discusses multimodal RAG methods along the dimensions of domain openness, retrieval modality, retrieval granularity, graph-based integration, and Agent-based enhancement.
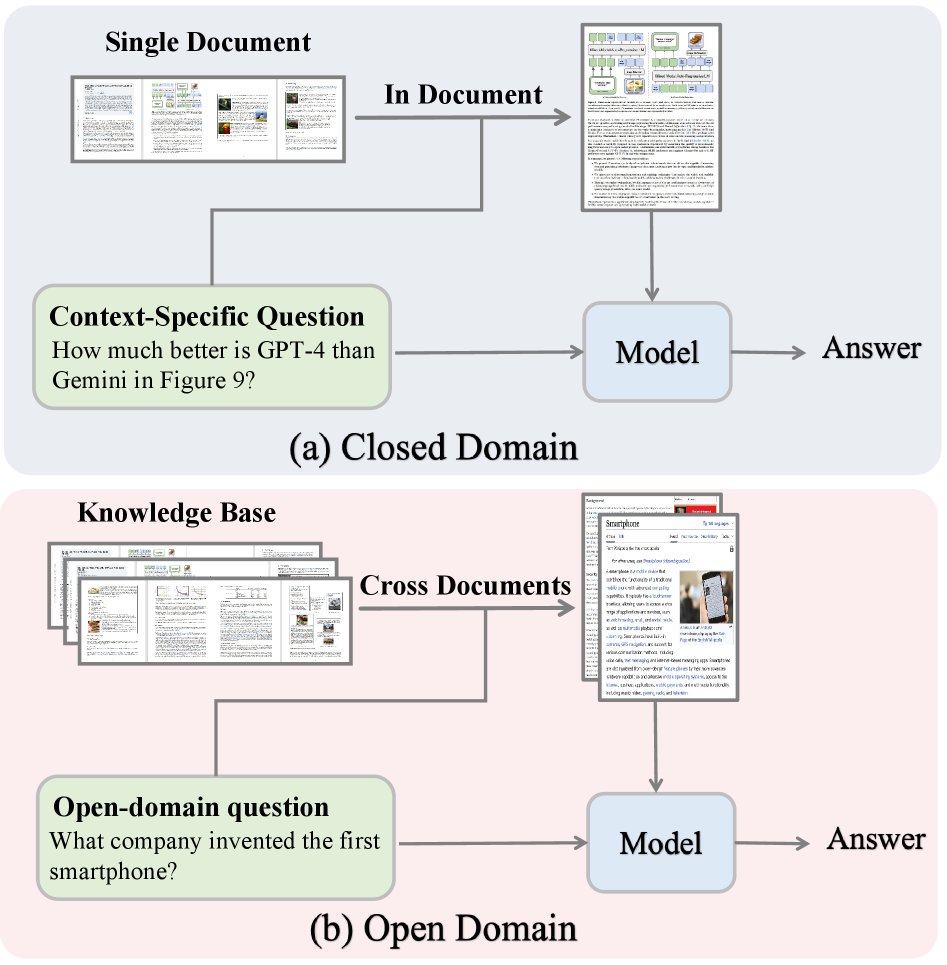 (a) In the closed domain, the model uses retrieval within a single document to answer context-specific questions. (b) In the open domain, the model relies on retrieval across multiple documents to answer open-ended questions.
(a) In the closed domain, the model uses retrieval within a single document to answer context-specific questions. (b) In the open domain, the model relies on retrieval across multiple documents to answer open-ended questions.
Open-Domain and Closed-Domain
RAG systems are divided into open-domain and closed-domain according to their retrieval scope.
Open-domain multimodal RAG retrieves information from large-scale document corpora to build a broad knowledge base and enhance the LLM’s domain-specific knowledge. Early methods relied on OCR to build text indexes, which was computationally expensive. Recent methods such as DSE and ColPali directly encode document pages using vision-language models (VLM), improving efficiency. To address the issue that most methods are limited to reasoning within a single document, M3DocRAG introduces approximate indexing to accelerate large-scale retrieval, while VDocRAG reduces page-level information loss by compressing visual content into dense Token representations aligned with text.
Closed-domain multimodal RAG focuses on a single long document and retrieves only the most relevant page segments as input to the MLLM, addressing the context window limitations and hallucination issues of MLLMs. For example, SV-RAG uses the MLLM itself as a multimodal retriever, FRAG independently scores each page and performs Top-K selection, and CREAM introduces a coarse-to-fine multimodal retrieval framework. These methods all demonstrate that closed-domain RAG can effectively understand long documents without extending the model’s context length.
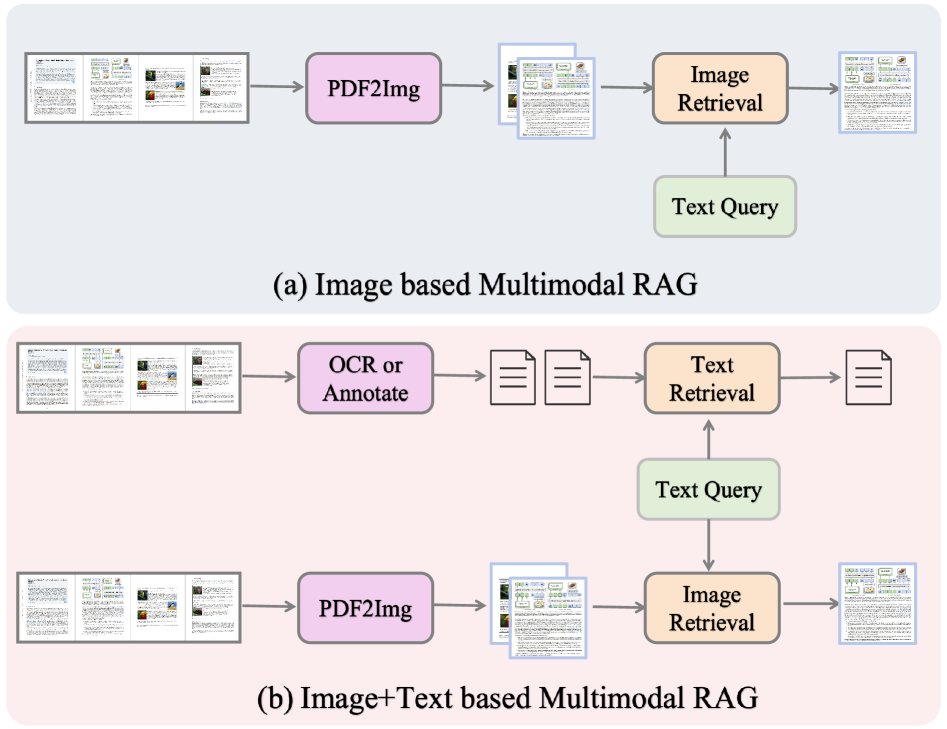 (a) Image-based RAG retrieves information only from page images, offering high efficiency but limited text details; (b) image+text-based RAG combines OCR/annotations with visual features, enabling richer retrieval but with greater processing complexity.
(a) Image-based RAG retrieves information only from page images, offering high efficiency but limited text details; (b) image+text-based RAG combines OCR/annotations with visual features, enabling richer retrieval but with greater processing complexity.
Retrieval Modality
According to the type of information used for retrieval, methods can be divided into pure image retrieval and image-text hybrid retrieval.
Pure image retrieval treats each document page as an image and uses the VLM’s visual encoder to encode it into a page-level representation. The query is encoded in the same way, and pages are ranked and retrieved by computing similarity. For example, MM-R5 introduces a reasoning-enhanced reranker on top of image embeddings, while Light-ColPali reduces embedding size through token merging, enabling memory-efficient visual document retrieval.
Image-text hybrid retrieval combines visual and textual modalities to mitigate the loss of fine-grained text information when relying only on a visual encoder. The text channel is usually extracted via OCR or generated as summary annotations by a large VLM. VisDomRAG and HM-RAG adopt a dual-path pipeline, performing retrieval and reasoning separately for each modality before fusing the results. ViDoRAG and PREMIR first retrieve within each modality, then merge the candidate sets before answer generation. SimpleDoc uses a two-stage scheme: it first selects candidates based on embeddings, then reranks them using page summaries generated by a VLM.
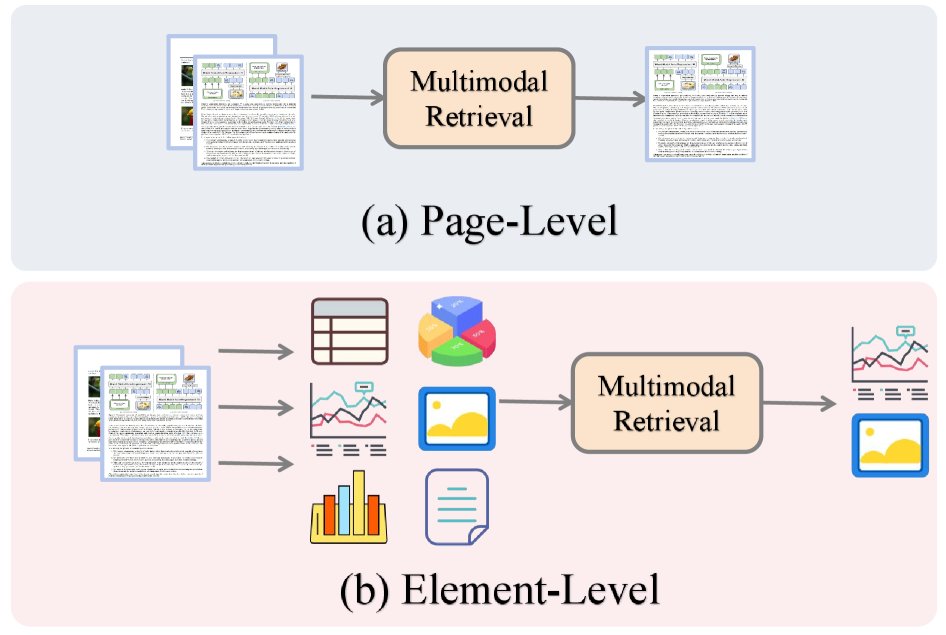 (a) Page-level: the entire page is encoded and ranked as an atomic unit. (b) Element-level: the page is decomposed into tables, charts, images, and text blocks; retrieval operates on these elements to locate evidence and aggregate results.
(a) Page-level: the entire page is encoded and ranked as an atomic unit. (b) Element-level: the page is decomposed into tables, charts, images, and text blocks; retrieval operates on these elements to locate evidence and aggregate results.
Retrieval granularity
The smallest unit of retrieval defines the retrieval granularity, ranging from page-level to finer element-level retrieval.
Early studies typically used the page as the atomic retrieval unit, ignoring fine-grained structures such as tables and charts within the page. Recent work has increasingly focused on intra-page fine-grained retrieval. Some methods improve retrieval accuracy by explicitly encoding these components. For example, VRAG-RL uses reinforcement learning to enable the LLM to attend to fine-grained regions within retrieved pages that are directly relevant to the query. MG-RAG adopts a multi-granularity strategy, allowing retrieval at different levels such as pages, tables, and images. DocVQA-RAP introduces a utility-driven retrieval mechanism that prioritizes document fragments that contribute more to answer quality. MMRAG-DocQA leverages hierarchical indexing and multi-granularity semantic retrieval to capture fine-grained multimodal associations. mKG-RAG uses a multimodal knowledge graph for two-stage retrieval to optimize evidence selection. PREMIR achieves intra-page fine-grained retrieval by generating predefined question-answer pairs for tables and charts.
Hybrid enhancement methods
To further improve multimodal RAG performance, researchers have introduced graph structures and intelligent agent frameworks.
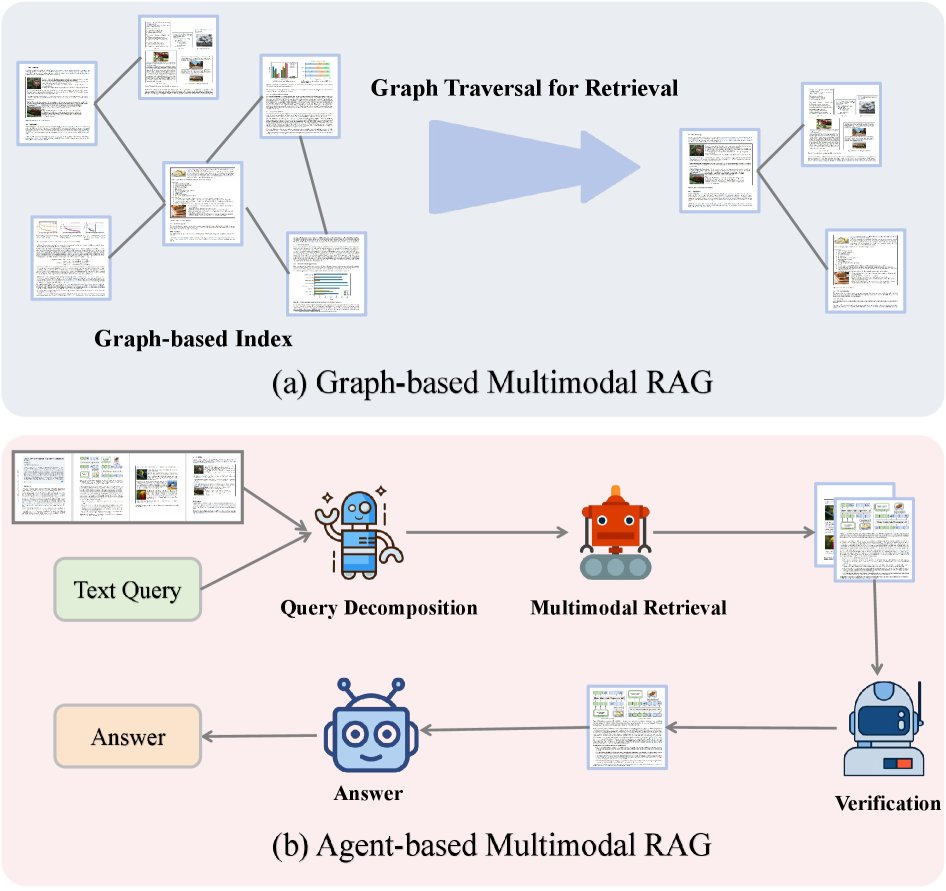 (a) Graph-based: documents/elements form a graph index, and graph traversal is used to retrieve relevant neighborhoods. (b) Agent-based: an LLMagent decomposes the text query, coordinates multimodal retrieval, verifies collected evidence, and synthesizes the final answer.
(a) Graph-based: documents/elements form a graph index, and graph traversal is used to retrieve relevant neighborhoods. (b) Agent-based: an LLMagent decomposes the text query, coordinates multimodal retrieval, verifies collected evidence, and synthesizes the final answer.
Graph-based multimodal RAG
This approach represents multimodal content as an explicit graph, where nodes correspond to modalities or content units (such as pages, text blocks, images, and tables), and edges represent semantic, spatial, and contextual relationships among them. Retrieval and reasoning on this graph can integrate heterogeneous evidence more effectively. For example, HM-RAG uses a graph-based database as one of the key modalities for multi-source retrieval. mKG-RAG explicitly constructs a multimodal knowledge graph as a structured knowledge base to improve retrieval accuracy. MoLoRAG leverages a page graph encoding logical relationships between pages to retrieve evidence through graph traversal.
Agent-based multimodal RAG
This approach deploys autonomous intelligent agents to coordinate the retrieval-generation process. These agents can dynamically formulate queries, select retrieval strategies, and adaptively fuse information from multiple modalities according to task requirements. For example, ViDoRAG introduces an iterative agent workflow responsible for exploration, summarization, and reflection. HM-RAG designs a hierarchical multi-agent architecture, including a decomposition agent, a retrieval agent, and a decision agent. Patho-AgenticRAG uses agents for task decomposition and multi-round search interaction in the medical domain. These frameworks demonstrate how specialized agent designs can enhance the fine-grained retrieval and reasoning capabilities of multimodal RAG systems.
Datasets and benchmarks
The datasets and benchmarks used in multimodal RAG research for document understanding usually consist of visually rich document collections. The table below summarizes existing datasets and benchmarks.
| Dataset/Benchmark | # Queries | Dataset Size | Content Type | Description |
|---|---|---|---|---|
| Commonly used datasets | ||||
| DocVQA | 50k | 12k (I) | q! | Visual question answering focused on document images |
| InfographicVQA | 30k | 5k (I) | q! | Visual question answering for infographics |
| ChartQA | 32k | 27k (I) | q! | Question answering for charts |
| Kleister-NDA | 0.5k | 0.5k (D) | q! | Information extraction from legal documents |
| TAT-QA | 16k | 16k (I) | q! | Question answering over tables and text |
| Emerging benchmarks | ||||
| ViDoRe | 43k | 41k (D) | q!1 | A comprehensive benchmark spanning academic and practical domains |
| VISR-BENCH | 2k | 262 (D) | q!1 | A manually verified diverse dataset |
| M3DocVQA | 6k | 3k (D) | q!1 | Open-domain, cross-document visual question answering |
| VisDoMBench | 2k | 1k (D) | q! | Open-domain, cross-document visual question answering |
| OpenDocVQA | 1k | 39k (D) | q! | Open-domain, cross-document visual question answering |
| ViDoSeek | 84k | 4.8k (D) | q!1 | A visually rich document collection designed for RAG systems |
Note: q: text, !: table, Charts: charts, 1: slides. (D) denotes the number of documents, and (I) denotes the number of images.
Many existing methods also point out the limitations of current benchmarks and build new, more diverse ones. For example, ColPali constructed ViDoRe, a comprehensive benchmark spanning domains such as energy, government, and healthcare. To address the fact that most existing benchmarks focus on single-document retrieval, M3DocVQA, VisDoMRAG, and VDocRAG introduced the open-domain benchmarks M3DocVQA, VisDoMBench, and OpenDocVQA, respectively. ViDoRAG also released ViDoSeek, a visually rich document dataset specifically designed for RAG systems, supporting rigorous evaluation in real retrieval settings.
Applications
Multimodal RAG is increasingly used in document understanding across finance, scientific research, and survey analysis.
- Finance: MultiFinRAG improves question answering over financial reports by jointly modeling text, tables, and charts. FinRAGBench-V provides a benchmark that emphasizes visual citations for evidence traceability.
- Scientific research: HiPerRAG supports cross-modal retrieval and reasoning at the scale of millions of research papers. CollEX enables interactive exploration of multimodal scientific corpora.
- Social sciences: A framework based on the Eurobarometer survey combines RAG with MLLM to jointly process text and infographics, improving the interpretability of survey data.
Together, these applications demonstrate how multimodal RAG enhances the understanding and use of complex documents across domains.
Challenges and future directions
Although multimodal RAG has made steady progress in document understanding, several open challenges remain, pointing to future research directions.
-
Efficiency: Integrating high-dimensional visual and textual features incurs substantial computational cost, limiting scalability. Future research directions include designing lightweight multimodal encoders, adaptive retrieval strategies, and memory-efficient fusion mechanisms to reduce latency without sacrificing retrieval accuracy.
-
Finer-grained document representations: Many existing models operate at the page or paragraph level, overlooking the semantic information in micro-structures such as tables, charts, footnotes, and layout. Hierarchical encoders and attention mechanisms that can capture micro-structures while preserving macro-level context can improve model interpretability and strengthen downstream reasoning and decision-making capabilities.
-
Security and robustness: Models need to be able to resist adversarial attacks and misinformation, ensuring that the retrieved information is trustworthy and the generated content is reliable. Future work should focus on how to verify the sources and consistency of multimodal information, and on designing more robust end-to-end systems.