Reinforcement Learning for Machine Learning Engineering Agents
-
ArXiv URL: http://arxiv.org/abs/2509.01684v1
-
Author: Percy Liang; Joy He-Yueya; Sherry Yang
-
Publisher: Stanford University
TL;DR
This paper shows that gradient updates via reinforcement learning (RL) on a smaller language model (such as Qwen2.5-3B) can outperform much larger static models (such as Claude-3.5-Sonnet) on machine learning engineering (MLE) tasks. Its core contribution is two key techniques for overcoming RL challenges in the Agent setting: duration-aware gradient updates for handling operations with variable execution times, and environment instrumentation for providing partial credit to address sparse rewards.
Key Definitions
This paper proposes the following core concepts to improve reinforcement learning applied to machine learning engineering agents:
- Duration-aware gradient updates: A modified policy gradient update rule. In asynchronous distributed RL, actions with shorter execution times finish sooner and produce more gradient updates, causing the policy to favor fast but suboptimal solutions. This method counteracts that frequency bias by weighting each gradient update by the corresponding action execution duration \(Δt\), ensuring that long-running but high-reward actions receive the attention they deserve in policy updates.
- Environment instrumentation: A technique designed to address sparse rewards. It uses a separate, static language model to automatically insert verifiable \(print\) statements into code generated by the agent, tracking the execution progress of key steps such as data loading, model training, and inference. By checking whether these print outputs appear, the system can provide the agent with partial credit, distinguishing nearly correct programs from those that fail early and thereby offering denser reward signals for learning.
- Partial credit: A direct product of environment instrumentation, this is an intermediate reward mechanism. It rewards the agent for completing substeps of a task rather than only giving a reward when the task succeeds at the end. This effectively guides the agent to learn step by step and avoids getting stuck in local optima or failing to learn because the final reward is too sparse.
Related Work
Current machine learning engineering (MLE) agents mainly rely on prompting powerful large language models (LMs) to solve tasks. Although using more sophisticated agent frameworks or increasing inference time can improve performance to some extent, these agents are static and cannot fundamentally improve their capabilities through gradient updates from collected experience.
This paper aims to address two key bottlenecks encountered when applying reinforcement learning (RL) to MLE agents:
- Variable-duration action execution: In MLE tasks, different code snippets generated by the agent (actions) can have vastly different execution times (for example, training different models). In standard asynchronous distributed RL frameworks, this causes the policy to disproportionately favor fast-executing but poorer solutions, because they generate training samples and gradients more quickly.
- Sparse reward signals: Using only final test-set performance as the reward provides very limited feedback. A program that fails at the last step and one that cannot even load the data from the beginning may receive exactly the same reward (usually zero). This makes it difficult for the agent to learn complex multi-step tasks, and it may even learn to “game the system” (for example, by exploiting evaluation-function behavior to bypass machine learning modeling).
Method
To address the above challenges, this paper proposes an RL framework for MLE agents centered on duration-aware gradient updates and environment instrumentation. The agent can also perform multi-step optimization through self-improvement prompts.

Figure 4: Overview of the proposed framework. Duration-aware gradient updates reweight policy gradient updates according to action execution duration. Environment instrumentation uses a static LM to insert print statements, whose execution outputs can be extracted as partial credit. The agent can further be asked to improve a previous solution, and its response can be further strengthened through RL.
Duration-aware gradient updates
In asynchronous distributed RL, because different code solutions generated by the agent have different execution times \(Δt\), the gradient contribution of an action per unit time is inversely proportional to its execution time, leading to a preference for fast actions.
To correct this bias, the paper proposes weighting each policy gradient update by the action execution duration \(Δt_k\). The new policy gradient update rule is as follows:
\[\nabla_{\theta}J(\pi_{\theta})=E_{\pi,\mu,\mathcal{P}}\left[\sum_{k=0}^{K}\Delta t_{k}\cdot\nabla_{\theta}\log\pi_{\theta}(a_{k} \mid s_{k})\cdot\hat{A}(s_{k},a_{k})\right]\]where \(Δt_k\) is the execution duration of action \(a_k\), and \(A_hat(s_k, a_k)\) is the advantage estimate. By introducing \(Δt_k\), each action’s contribution to the gradient update is decoupled from its execution frequency, ensuring that long-running but high-return actions (such as training a more complex model) can also be learned effectively. In practice, to avoid overly large gradients, the average execution time within a batch is used to scale \(Δt_k\).
Environment instrumentation for partial credit
To address the sparse-reward problem, this paper designs a mechanism that provides intermediate rewards, i.e., “partial credit.” It is implemented through a separate, static language model (a separate static copy of the original LM), which is responsible for “instrumenting” the code generated by the agent.
The process is as follows:
- Code insertion: Before executing the code generated by the agent, an auxiliary LM inserts \(print\) statements into the code to track progress, such as marking key milestones like “data loading complete” and “model construction complete.”
- Execution and parsing: The modified code is executed.
- Reward assignment: Terminal output is matched with regular expressions to check which \(print\) statements were successfully executed. A small positive reward (for example, +0.1) is given for each successfully reached milestone. A completely failed program receives a large negative reward (for example, -10). If the program runs successfully and generates a submission file, the actual competition score is used as the final reward.
Using a separate static LM is crucial, as it prevents the learning agent from “cheating” to obtain partial credit, for example by generating only \(print\) statements without actually performing the task.
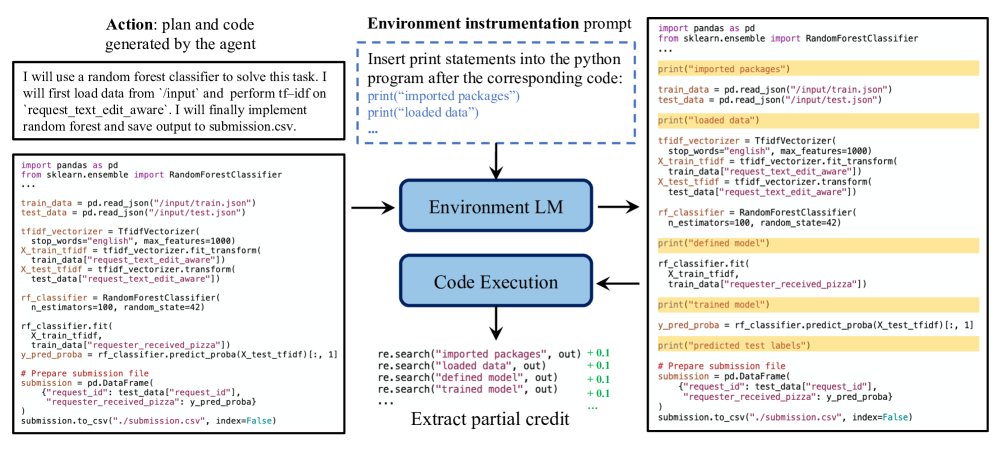
Figure 5: Overview of environment instrumentation. Another copy of a small LM (Qwen2.5-3B) is prompted to insert print statements into code generated by the agent. After the code is executed, terminal output is parsed, and partial credit is assigned through regular-expression matching.
Multi-step reinforcement learning with self-improvement prompts
This paper also explores the agent’s ability to self-improve. During training, one of two prompts is randomly selected with 50% probability:
- Solve the task from scratch.
- Improve an existing solution: Provide the agent with a previously generated solution and its execution output (including information such as training/test accuracy from environment instrumentation), and ask it to improve the solution.
At test time, the model first generates a solution from scratch, then runs once more to improve that solution, and finally selects the better-performing one of the two.
Experimental Results
The paper conducts experiments on a subset of MLEBench containing 12 Kaggle tasks, comparing the RL-trained small model (Qwen2.5-3B) with large models that rely on prompt engineering (such as Claude-3.5-Sonnet and GPT-4o).
Key Findings
-
Small-model RL surpasses large-model prompting: After RL training, Qwen2.5-3B achieved better final performance than all frontier large models (Llama3.1-405B, Claude-3.5-Sonnet, GPT-4o) on 8 of the 12 tasks. Compared with Claude-3.5-Sonnet, the average performance improved by 22%.
-
Better than different agent frameworks: The RL-trained Qwen2.5-3B outperformed GPT-4o using different agent frameworks (AIDE, OpenHands, MLAB) on 9 of the 12 tasks.
-
Learning-curve comparison: Although the large model performed far better than the small model at the beginning of training, as RL training progressed, the small model’s performance continued to improve through gradient updates and eventually surpassed the large model. This shows that gradient updates are a more effective long-term improvement path than prompting alone.
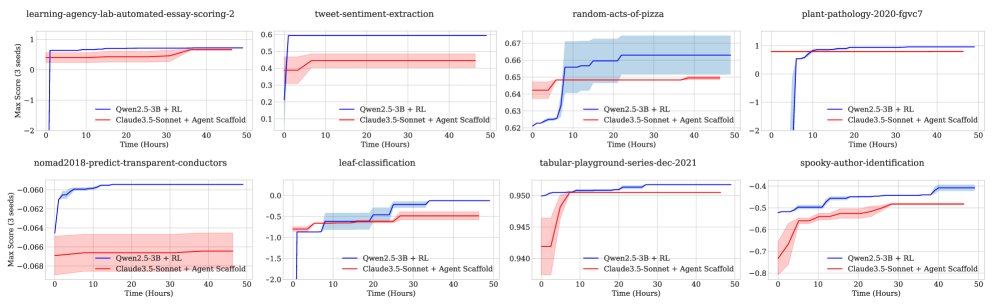
Figure 7: Comparison of the best scores achieved by the agent at different points in time. The RL-trained small model initially scored lower on many tasks, but eventually outperformed the prompted large model.
Ablation Study
| Task | GPT-4o AIDE | GPT-4o OpenHands | GPT-4o MLAB | Qwen2.5-3B RL |
|---|---|---|---|---|
| detecting-insults-in-social-commentary ($\uparrow$) | NaN | 0.867 +/- 0.017 | 0.749 +/- 0.039 | 0.895 +/- 0.001 |
| learning-agency-lab-automated-essay-scoring-2 ($\uparrow$) | 0.720 +/- 0.031 | 0.681 +/- 0.010 | 0.533 +/- 0.080 | 0.746 +/- 0.002 |
| random-acts-of-pizza ($\uparrow$) | 0.645 +/- 0.009 | 0.591 +/- 0.048 | 0.520 +/- 0.013 | 0.663 +/- 0.011 |
| tweet-sentiment-extraction($\uparrow$) | 0.294 +/- 0.032 | 0.415 +/- 0.008 | 0.158 +/- 0.057 | 0.596 +/- 0.002 |
| tabular-playground-series-may-2022 ($\uparrow$) | 0.884 +/- 0.012 | 0.882 +/- 0.030 | 0.711 +/- 0.050 | 0.913 +/- 0.000 |
| tabular-playground-series-dec-2021 ($\uparrow$) | 0.957 +/- 0.002 | 0.957 +/- 0.000 | 0.828 +/- 0.118 | 0.951 +/- 0.000 |
| us-patent-phrase-to-phrase-matching ($\uparrow$) | 0.756 +/- 0.019 | 0.366 +/- 0.039 | NaN | 0.527 +/- 0.003 |
| plant-pathology-2020-fgvc7 ($\uparrow$) | 0.980 +/- 0.002 | 0.680 +/- 0.113 | 0.735 +/- 0.052 | 0.970 +/- 0.004 |
| leaf-classification ($\downarrow$) | 0.656 +/- 0.070 | 0.902 +/- 0.018 | 4.383 +/- 2.270 | 0.124 +/- 0.000 |
| nomad2018-predict-transparent-conductors ($\downarrow$) | 0.144 +/- 0.031 | 0.183 +/- 0.120 | 0.294 +/- 0.126 | 0.059 +/- 0.000 |
| spooky-author-identification ($\downarrow$) | 0.576 +/- 0.071 | 0.582 +/- 0.020 | 0.992 +/- 0.463 | 0.404 +/- 0.011 |
| lmsys-chatbot-arena ($\downarrow$) | 1.323 +/- 0.147 | 1.131 +/- 0.019 | 10.324 +/- 4.509 | 1.081 +/- 0.002 |
- Effect of time-aware gradients: This mechanism enables the intelligent agent to explore solutions that take longer to execute but yield higher returns (such as gradient-boosted trees), whereas training without this mechanism converges to fast but suboptimal solutions (such as linear logistic regression).
- Effect of environment detection: This mechanism significantly accelerates the convergence of RL training and improves training stability, because the partial credit it provides helps the intelligent agent overcome initial obstacles more quickly (such as data loading failures).
- Effect of self-improvement prompts: Compared with solving tasks from scratch only, training with self-improvement prompts achieved better final performance on 10/12 tasks, with an average improvement of 8%.
Final Conclusion
The experimental results strongly show that for complex tasks such as machine learning engineering, where the cost of action execution cannot be ignored, allocating computational resources to RL training of small models is a more effective strategy for adaptation and performance improvement than relying solely on large-model prompting.