Prompt-R1: Collaborative Automatic Prompting Framework via End-to-end Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2511.01016v1
-
Authors: Jiapu Wang; Haoming Liu; Xueyuan Lin; Haoran Luo; Rui Mao; Erik Cambria
-
Affiliations: Hainan University; Hong Kong University of Science and Technology; Nanjing University of Science and Technology; Nanyang Technological University; National University of Singapore; Tsinghua University
TL;DR
This paper proposes an end-to-end reinforcement learning framework called Prompt-R1, which trains a small language model (as the intelligent agent) to generate and refine prompts through multi-turn interaction, thereby collaborating with a large language model (as the environment) to solve complex problems at lower cost and higher efficiency.
Key Definitions
The paper introduces or adopts the following core concepts:
- Prompt-R1: A collaborative automatic prompting framework based on end-to-end reinforcement learning. Its core idea is to use a small language model as the intelligent agent, which learns how to generate the optimal prompt sequence by interacting with a large language model to solve complex tasks.
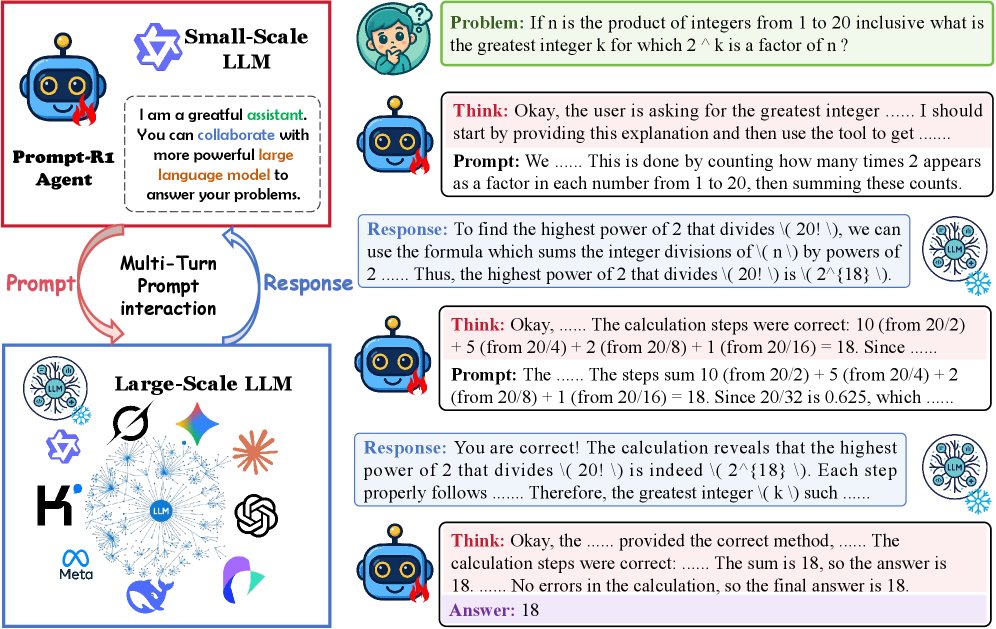
- agent (Agent): In the Prompt-R1 framework, this role is played by a small-scale LLM. It is responsible for “thinking” about the problem, generating guiding prompts, and iterating over multiple rounds based on feedback from the large language model, ultimately producing the answer.
- Environment: In the Prompt-R1 framework, this role is played by a large-scale LLM. It receives prompts from the intelligent agent and generates responses based on its strong reasoning ability. This large model is “plug-and-play” and requires no additional training.
- Multi-Turn Prompt Interaction: A series of “prompt-response” loops between the intelligent agent and the environment. In each round, the intelligent agent adjusts its thinking and prompts based on the historical interaction record, gradually guiding the environment toward the correct answer.
- Double-constrained Reward: A specific reward function designed for the reinforcement learning process, consisting of two parts: format reward ensures that the intelligent agent’s output (reasoning process and prompts) follows the preset structure and conventions; answer reward evaluates the accuracy of the final answer. This design ensures that the model not only pursues correctness but also generates a well-structured and logically coherent reasoning path.
Related Work
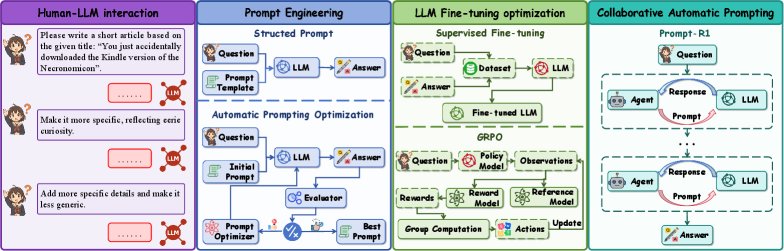
Current methods for improving the performance of large language models (LLMs) mainly include prompt engineering, model fine-tuning, and reinforcement learning-based optimization.
- SOTA:
- Prompt Engineering: Methods such as Chain-of-Thought (CoT) stimulate the reasoning ability of LLMs by designing structured prompts, but they rely on manual design. Automatic prompt optimization (APO) methods such as OPRO and TextGrad attempt to automatically search for better prompts through algorithms.
- Fine-tuning Optimization: Parameter-efficient fine-tuning methods such as LoRA can adapt LLMs to specific tasks, but for large models, the computational and storage overhead is enormous.
- Reinforcement Learning Optimization: Methods such as RLHF and DPO use feedback to align model behavior and improve reasoning ability, but they usually act directly on the large model itself, making the training process complex and expensive.
- Key Problems and Bottlenecks:
- Capability Limits of Small LLMs: Small models perform poorly when handling long-range dependencies and complex reasoning tasks.
- Optimization Cost of Large LLMs: Fine-tuning large models requires massive computational resources, while API-based usage is costly and cannot support adaptive optimization.
- Low Collaboration Efficiency: Existing methods often rely on complex APIs, redundant layers, or cumbersome prompt engineering, reducing collaboration efficiency and cost-effectiveness in dynamic, multi-task environments.
This paper aims to address the above issues by proposing a resource-efficient, adaptive, and scalable collaborative framework that enables small LLMs to effectively leverage the capabilities of large LLMs without fine-tuning the large LLMs.
Method
The core of Prompt-R1 is a collaborative process between an intelligent agent played by a small LLM and an environment played by a large LLM, with the entire process optimized end to end through reinforcement learning.
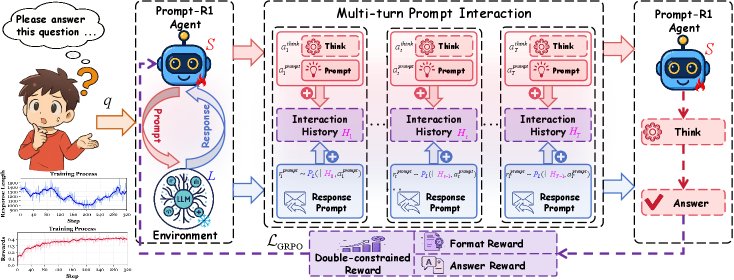
Multi-Turn Prompt Interaction Framework
The framework models the problem-solving process as a multi-turn dialogue between the intelligent agent (small LLM $S$) and the environment (large LLM $L$).
- Role Definitions:
- Intelligent Agent \(S\) (Agent): Responsible for thinking about the problem \(q\) and generating the reasoning process $a_t^{\text{think}}$ and the interaction prompt $a_t^{\text{prompt}}$.
- Environment \(L\) (Environment): Receives the intelligent agent’s prompt and generates the response $r_t^{\text{prompt}}$.
- Interaction Process:
-
In round \(t\), the intelligent agent \(S\) generates an action based on the historical interaction record $H_{t-1}$ and the problem \(q\). This action consists of two parts: “thinking” and “generating a prompt”:
\[(a_t^{\mathrm{think}}, a_t^{\mathrm{prompt}}) \sim S(q, H_{t-1})\]
-
-
The environment \(L\) receives the prompt $a_t^{\text{prompt}}$ and generates a response:
$$ r_t^{\mathrm{prompt}} \sim P_L(\cdot \mid H_{t-1}, a_t^{\mathrm{prompt}}) $$ -
The history is updated as $H_t = H_{t-1} \oplus (a_t^{\text{prompt}}, r_t^{\text{prompt}})$, preparing for the next round of interaction.
- This process is repeated for \(T\) rounds until the intelligent agent decides to generate the final answer \(y\).
Double-constrained Reinforcement Learning Optimization
To enable the intelligent agent to learn how to generate high-quality prompts, the paper designs a reinforcement learning-based optimization strategy centered on a double-constrained reward function and a GRPO optimization objective.
- Innovation: Double-constrained Reward This reward \(R\) consists of two parts, aiming to ensure both the regularity of the generation process and the accuracy of the final result.
-
Format Reward $R_{\text{fmt}}$: Used to ensure that the intelligent agent generates non-empty thinking and prompts at every step, and that the final answer is correctly formatted and complete.
\[R_{\mathrm{fmt}}=\min\!\Bigl(\epsilon,\;\alpha\!\sum_{t=1}^{T-1}\!M_{t}+\beta A_{p}+\gamma A_{n}+\delta C_{f}\Bigr)\]
-
Here, $M_t$ checks the completeness of intermediate steps, and $A_p, A_n, C_f$ check the compliance of the final answer. * Answer Reward $R_{\text{ans}}$: Uses the F1 score to measure the consistency between the predicted answer $\hat{a}$ and the ground-truth answer \(g\).
$$
R_{\text{ans}}=\max_{g\in\mathcal{G}(q)}\mathrm{F1}(\hat{a},g)
$$
-
Gated Combination: This is a key design in which the answer reward is included in the total reward \(R\) only when the format is completely correct ($R_{\text{fmt}}=\epsilon$). This forces the intelligent agent to first learn to “say the right thing” before pursuing “saying it correctly.”
$$ R=\begin{cases}-\epsilon+R_{\text{fmt}}+R_{\text{ans}},&R_{\text{fmt}}=\epsilon,\\ -\epsilon+R_{\text{fmt}},&\text{otherwise},\end{cases} $$
-
Optimization Objective: The paper adopts a GRPO (Group Relative Policy Optimization)-based loss function, converting trajectory-level rewards into token-level weights to achieve end-to-end optimization. It standardizes the rewards within a batch to compute the advantage value $\hat{A}^{(i)}$, and uses it to weight the policy’s log-likelihood loss.
\[\mathcal{L}_{\mathrm{GRPO}} = \frac{1}{M}\sum_{i=1}^{M}\frac{1}{ \mid u^{(i)} \mid }\sum_{t=1}^{ \mid u^{(i)} \mid }\Bigl[-\hat{A}^{(i)}\log\pi_{\theta}\!\left(w_{t}^{(i)}\mid u^{(i)}_{<t},q\right) + \beta\,\mathrm{KL}(\dots)\Bigr]\]
This objective encourages trajectories with high rewards while using a KL-divergence constraint to prevent the policy from drifting too far from the initial reference policy.
Efficient Training and Inference
One of the framework’s biggest advantages is its “plug-and-play” nature, which decouples the training and inference stages.
- Training phase: Any open-source large LLM (for example, \(m_train\)) can be used as the environment to train the policy \(π_θ\) of the intelligent agent (a small LLM). This process can be completed locally or in a private environment, with controllable cost.
- Inference phase: The trained intelligent agent can collaborate with any other large LLM (for example, \(m_test\), which can be a closed-source API model such as GPT-4o-mini). This means that by training a small intelligent agent only once, its capabilities can be “transferred” and empowered across multiple different, more powerful large models, greatly improving the framework’s flexibility and practicality.
Experimental Conclusions
The experiments were conducted around several research questions, including the effectiveness, generalization, transferability, and component effectiveness of Prompt-R1.
- Effectiveness (RQ1): Prompt-R1 significantly outperformed baseline methods (such as SFT and CoT) and other automatic prompt optimization methods (such as OPRO and TextGrad) on eight public datasets. It achieved the best performance across a variety of tasks, including multi-hop reasoning, mathematical computation, standard question answering, and text generation, with the most notable improvements on multi-hop QA tasks that require complex reasoning.
| Method | Multi-hop Reasoning (F1) | Standard QA (F1) | Mathematical Reasoning (EM) | Text Generation (SSim) | |||||
|---|---|---|---|---|---|---|---|---|---|
| Task | 2Wiki | Hotpot | MusiQue | PopQA | GSM8K | DAPO | BookSum | W.P | Average |
| Baseline (GPT-4o-mini) | 39.5 | 45.2 | 34.6 | 60.1 | 55.4 | 51.5 | 60.8 | 63.5 | 51.3 |
| SFT | 38.3 | 43.5 | 34.2 | 59.9 | 53.9 | 50.1 | 60.1 | 62.4 | 50.3 |
| CoT | 41.8 | 46.0 | 36.1 | 62.1 | 57.2 | 53.0 | 62.9 | 65.0 | 53.0 |
| OPRO | 44.5 | 49.3 | 37.9 | 64.9 | 59.6 | 55.3 | 64.8 | 67.2 | 55.4 |
| TextGrad | 42.1 | 47.7 | 36.8 | 63.5 | 58.1 | 53.7 | 63.3 | 66.0 | 53.9 |
| GEPA | 43.6 | 48.1 | 37.4 | 64.1 | 59.0 | 54.7 | 64.2 | 66.8 | 54.8 |
| Prompt-R1 | 47.6 | 52.3 | 41.2 | 68.2 | 63.4 | 58.6 | 69.3 | 71.7 | 59.0 |
| $\Delta$$\uparrow$ | +8.1 | +7.1 | +6.6 | +8.1 | +8.0 | +7.1 | +8.5 | +8.2 | +7.7 |
- Generalization (RQ2): Tests on four out-of-distribution (OOD) datasets showed that Prompt-R1 has strong generalization ability. Even on unseen tasks, its performance comprehensively surpassed other methods, demonstrating that the framework learned a universal strategy for “how to ask questions and collaborate,” rather than merely overfitting to specific tasks.
| Method | AMBIGQA (F1) | SQuAD2.0 (F1) | TriviaQA (EM) | XSUM (SSim) | Average |
|---|---|---|---|---|---|
| Baseline | 35.1 | 65.5 | 73.0 | 39.0 | 53.2 |
| SFT | 34.8 | 64.2 | 72.5 | 38.4 | 52.5 |
| CoT | 36.9 | 67.3 | 75.2 | 41.2 | 55.2 |
| OPRO | 38.8 | 69.8 | 77.8 | 43.5 | 57.5 |
| TextGrad | 37.4 | 68.0 | 76.1 | 41.9 | 55.9 |
| GEPA | 38.1 | 69.2 | 77.0 | 42.8 | 56.8 |
| Prompt-R1 | 41.3 | 71.5 | 80.3 | 45.6 | 59.7 |
| $\Delta$$\uparrow$ | +6.2 | +6.0 | +7.3 | +6.6 | +6.5 |
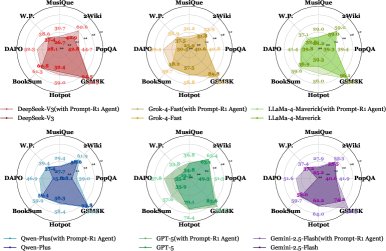
- Transferability (RQ3/RQ5): Experiments demonstrated the “plug-and-play” nature of Prompt-R1. An intelligent agent trained with an open-source model (a zero-cost environment) can directly collaborate with closed-source models such as GPT-4o-mini (a cost-bearing environment) and significantly improve their performance. As shown in the figure below, across multiple datasets and LLMs, models equipped with the Prompt-R1 intelligent agent consistently improved, proving that the framework’s strategy can be successfully transferred.

- Final conclusion: The Prompt-R1 framework successfully improves performance on complex tasks by enabling a small intelligent agent trained with reinforcement learning to collaborate with a large LLM. It not only outperforms existing methods across a variety of tasks and datasets, but also demonstrates excellent generalization and transferability. This “small model guiding large model” paradigm offers a new and promising path for efficiently and cost-effectively leveraging and enhancing the capabilities of existing LLMs.