PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
8B Model Surpasses GPT-5! PaCoRe: A New Paradigm for Unlocking 2 Million Token Inference Compute

Current large language models (LLMs) have a major weakness: their reasoning ability is tightly constrained by the context window. Once the Chain-of-Thought fills up the window, inference has to stop.
ArXiv URL:http://arxiv.org/abs/2601.05593v1
But what if we could break this limit?
A research team from Peking University, StepFun, and Tsinghua University has just released a major work — PaCoRe. With a brand-new “parallel coordinated reasoning” architecture, this technique enables a model with only 8B parameters to reach 94.5% accuracy on the HMMT 2025 math benchmark, surpassing GPT-5 (93.2%) in one fell swoop.
It does this by generating in parallel and collaboratively processing up to 2 million tokens of effective compute during inference, without ever blowing up the model’s context window. How is this possible?
Saying Goodbye to “Single-Threading”: From Serial to Parallel Coordination
Traditional methods for improving reasoning ability, such as CoT, are linear: the model thinks step by step, and all intermediate steps pile up in the same context window. It’s like a person solving a hard problem—once the scratch paper (context) is full, you can’t keep going.
PaCoRe (Parallel Coordinated Reasoning) is completely different. It no longer relies on a single deep search, but instead shifts to broad, coordinated exploration.
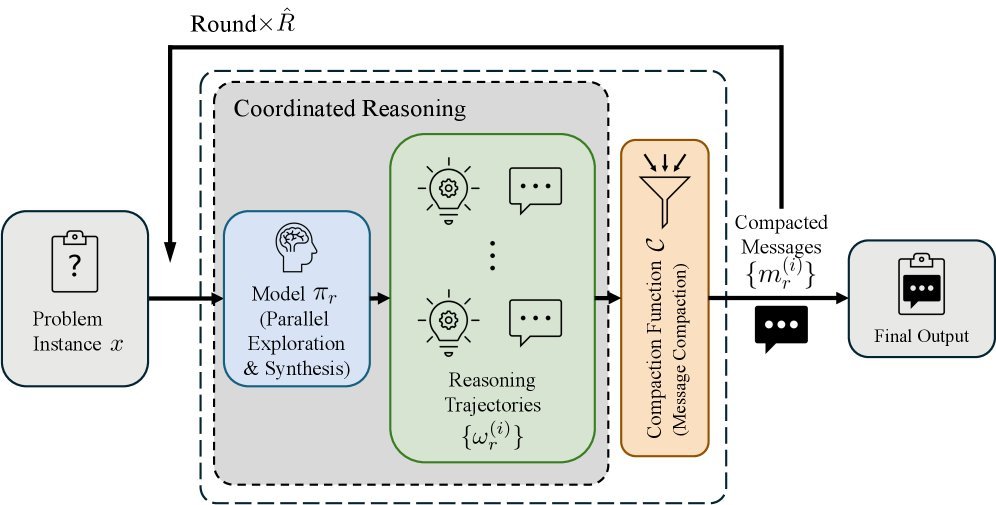
As shown in the figure above, PaCoRe’s reasoning process is like an efficient team collaboration:
-
Parallel Exploration: In each round of reasoning, the model launches multiple parallel reasoning trajectories at the same time. This is like sending out dozens of copies to try different paths simultaneously.
-
Message Compaction: This is PaCoRe’s most elegant step. Instead of stuffing all the chatter from every copy into the next round, it extracts each trajectory’s “final conclusion” and compresses it into a short “message.”
-
Synthesis: The model reads the compressed messages returned by all copies from the previous round, integrates these clues, and guides the next round of exploration.
Through this “generate-compact-coordinate” loop, PaCoRe can accumulate the equivalent of millions of tokens of effective reasoning compute (Test-Time Compute, TTC) over multiple iterations within a fixed-size context window.
The Core Challenge: From “Autocracy” to “Crowdsourcing Ideas”
Simply feeding the parallel results back into the model is not enough. The researchers found that ordinary reasoning models often suffer from “Reasoning Solipsism”: even when given high-quality clues from other branches, they tend to ignore this information and insist on recalculating everything from scratch, wasting compute.
To solve this problem, PaCoRe introduces large-scale, outcome-based Reinforcement Learning.
This is not just simple Majority Voting; it trains the model to master a more advanced ability — Reasoning Synthesis. After training, the PaCoRe model learns to:
-
Examine: Carefully evaluate conflicting evidence from different parallel branches.
-
Reconcile: Find reasonable explanations within contradictory information.
-
Surpass: Integrate clues from all sides to generate a final answer that is better than any single branch.
Experiments show that a model trained this way can even “derive” the correct solution path from a context full of wrong information, demonstrating astonishing robustness.
Experimental Results: The 8B Model’s Big Comeback
PaCoRe’s impact is especially striking on math and coding tasks.
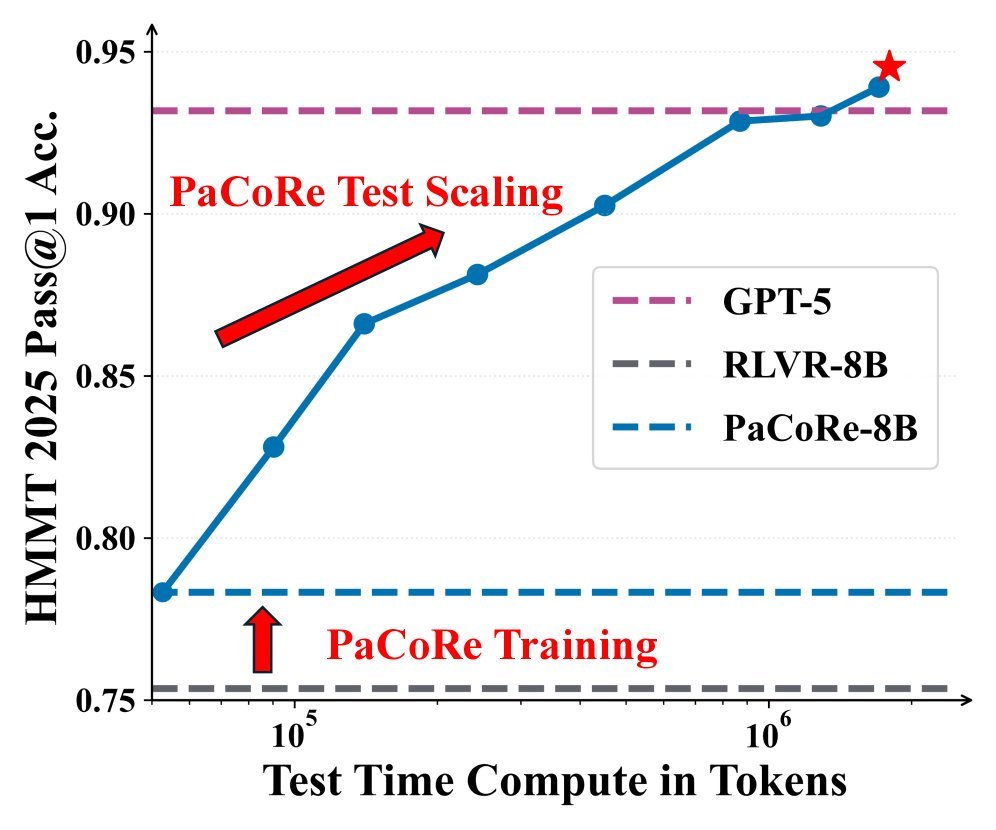
As can be seen on the left side of the figure above, on the HMMT 2025 benchmark:
-
As the amount of reasoning compute (TTC) increases (by increasing the number of parallel trajectories and coordination rounds), PaCoRe-8B’s performance improves steadily.
-
In the end, PaCoRe-8B reaches 94.5% accuracy, surpassing GPT-5 at 93.2%.
-
This proves that through parallel coordinated reasoning, a small model can absolutely trade more inference-time compute for intelligence that exceeds that of a larger model.
On the right side, in the LiveCodeBench test, the model without PaCoRe training (RLVR-8B) shows almost no performance improvement even as compute increases (the blue line stays flat), indicating that it cannot make use of the extra information. In contrast, PaCoRe-8B (red line) surges as compute increases, proving the importance of “synthesis ability.”
Conclusion and Outlook
PaCoRe is not just a specific model, but a general reasoning framework. It reveals a key trend: the future of AI is not only about making models bigger (Pre-training Scaling), but also about using compute more intelligently during inference (Test-Time Scaling).
By decoupling “reasoning volume” from the “context window,” PaCoRe enables the model to engage in nearly unlimited deep thinking. At present, the team has already open-sourced the model weights, training data, and the complete reasoning pipeline, which will undoubtedly accelerate community exploration in this direction.
When an 8B model learns to “divide labor and collaborate” and “hold meetings to summarize” like a human team, the energy it unleashes is enough to put pressure on even the most advanced closed-source models.