Outcome-based Exploration for LLM Reasoning
-
ArXiv URL: http://arxiv.org/abs/2509.06941v1
-
Authors: Yuda Song; Julia Kempe
-
Affiliations: CMU; Meta; NYU
TL;DR
This paper proposes an “Outcome-based Exploration” method that effectively improves the accuracy of large language models on reasoning tasks by providing exploration rewards during reinforcement learning training based on the final answer rather than the entire reasoning process, while also mitigating the decline in generation diversity caused by traditional RL training.
Key Definitions
- Outcome-based Exploration: A reinforcement learning exploration strategy whose core idea is that the exploration bonus depends only on the final result of the generated content (such as the answer to a math problem), rather than the entire high-dimensional reasoning path (the token sequence). This method leverages the fact that in reasoning tasks, the “outcome space” is much smaller than the “reasoning space,” making exploration efficient and tractable.
- Transfer of Diversity Degradation: A phenomenon identified in this paper. When reinforcement learning causes the model to converge to a small number of correct answers on already-solved problems, this loss of diversity “transfers” to unsolved problems, reducing the model’s ability to explore new answers on those problems and thus trapping it in a local optimum.
- Tractability of the Outcome Space: Refers to the fact that in verifiable reasoning tasks (such as math competitions), although the number of possible reasoning traces is enormous, the number of valid final answers reached by different paths is relatively limited and manageable. This is a key prerequisite for the feasibility of the “Outcome-based Exploration” method.
- Historical Exploration: An outcome-based exploration algorithm designed to encourage the model to visit more diverse answers throughout the training history. It improves exploration efficiency during training by giving UCB (Upper Confidence Bound)-style rewards to historically rare answers, with the main goal of improving \(pass@1\) accuracy.
- Batch Exploration: Another outcome-based exploration algorithm designed to improve generation diversity at test time. It directly incentivizes the model to produce diverse outputs by penalizing answers that repeatedly appear within the current generation batch, with the main goal of improving \(pass@k\) performance at high \(k\) values.
Related Work
Currently, post-training large language models (LLMs) with reinforcement learning (RL) is the mainstream approach for improving their reasoning ability. Outcome-based reinforcement learning, which gives rewards only according to the correctness of the final answer, has been shown to significantly improve model accuracy.
However, this approach has a serious bottleneck: systematic loss of diversity. After RL training, the diversity of answers generated by the model drops sharply, as reflected in the \(pass@k\) metric—when \(k\) is large, the RL-trained model can even perform worse than the base model. This collapse in diversity harms the model’s scalability in real applications, because performance gains at test time through multiple sampling or tree search depend on generation diversity.
The core problem this paper aims to solve is: how to improve LLM reasoning accuracy through reinforcement learning while avoiding or mitigating the severe decline in generation diversity, thereby achieving a better balance between accuracy and diversity.
Method
The core innovation of this paper is the proposal of an “Outcome-based Exploration” framework, which shifts the focus of exploration from the intractable space of reasoning paths to the manageable space of final answers.
RL as a Sampling Process: Perspective and Motivation
The paper first views the RL training process as a sampling process over the training set and compares it with direct sampling from the base model. Two key phenomena are observed experimentally, which motivate the proposed method:
- Transfer of Diversity Degradation: RL reinforces correct answers on already-solved problems, causing the probability distribution to collapse. This reduction in diversity generalizes to unsolved problems, lowering the model’s ability to explore new answers on those problems as well. As shown in the figure below, RL (solid line) discovers fewer new answers on unsolved problems (dashed line) than base-model sampling.
- Tractability of the Outcome Space: In tasks such as mathematical reasoning, although the reasoning process can vary widely, the set of final answers is limited (usually fewer than 50). This makes answer-based counting and exploration possible.
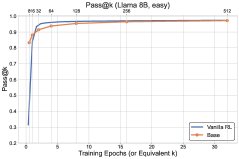
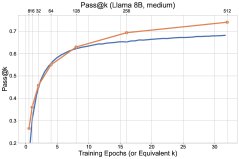
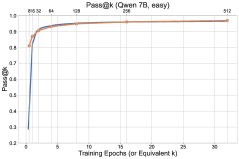
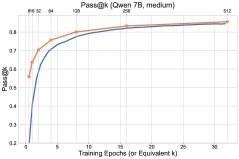
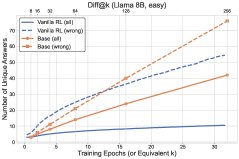
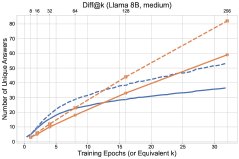
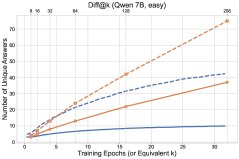
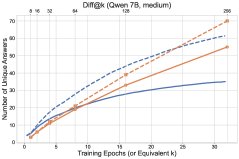
Figure 2: Comparison of RL training dynamics and base-model sampling. Top: number of solved problems; bottom: number of distinct answers discovered. Solid lines represent all problems, dashed lines represent unsolved problems.
Historical Exploration (\(Historical Exploration\))
To address the decline in diversity, the paper first introduces a history-count-based exploration method, similar to the classic UCB algorithm. An exploration reward is added to the RL objective:
\[\widehat{\operatorname{\mathbb{E}}}\_{x,\{y\_{i},a\_{i}\}\_{i=1}^{n}\sim\pi(\cdot\mid x)}\left[\frac{1}{n}\sum\_{i=1}^{n}\widehat{A}\left(x,\{y\_{i},a\_{i}\}\_{i=1}^{n}\right)\_{i}+cb\_{\mathsf{ucb}}(x,a\_{i})-\beta\widehat{\mathrm{KL}}(\pi(\cdot\mid x),\pi\_{\mathsf{base}}(\cdot\mid x))\right],\]where the exploration reward is $b_{\mathsf{ucb}}(x,a)=\min\left{1,\sqrt{\frac{1}{N(x,a)}}\right}$, and $N(x,a)$ is the number of times answer $a$ has historically appeared for problem $x$.
-
Problem with Naive UCB: Experiments show that directly using the above UCB reward (called naive UCB) can improve exploration efficiency during training (solving more problems faster), but its improvement on test performance is unstable. This may be because it encourages the model to repeatedly revisit known wrong answers, thereby harming generalization.
-
UCB with Baselines (\(UCB-Mean\) & \(UCB-Con\)): To address this issue, the paper introduces a baseline into the exploration reward, enabling a “negative exploration” signal (i.e., a penalty).
- \(UCB-Mean\): Uses the mean of the UCB rewards within the current batch as the baseline. This encourages the model to explore answers that are relatively rare within the current batch.
- \(UCB-Con\): Uses a fixed constant $b_0$ as the baseline, so the reward term becomes $b_{\mathsf{ucb}}(x,a_{i})-b_{0}$. This causes answers that have been visited too often to receive negative rewards. For example, when $b_0=0.5$, answers visited more than 4 times receive negative rewards. Experiments show that \(UCB-Con\) performs best among all methods and can consistently improve test performance.
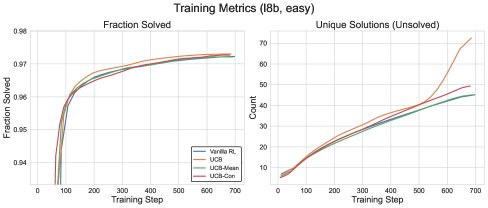
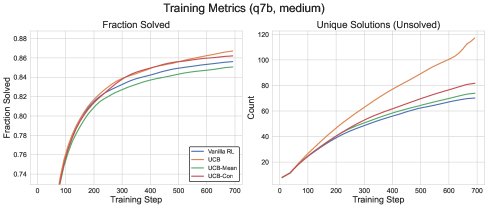 Figure 3: Training performance comparison between different UCB variants and the GRPO baseline.
Figure 3: Training performance comparison between different UCB variants and the GRPO baseline.
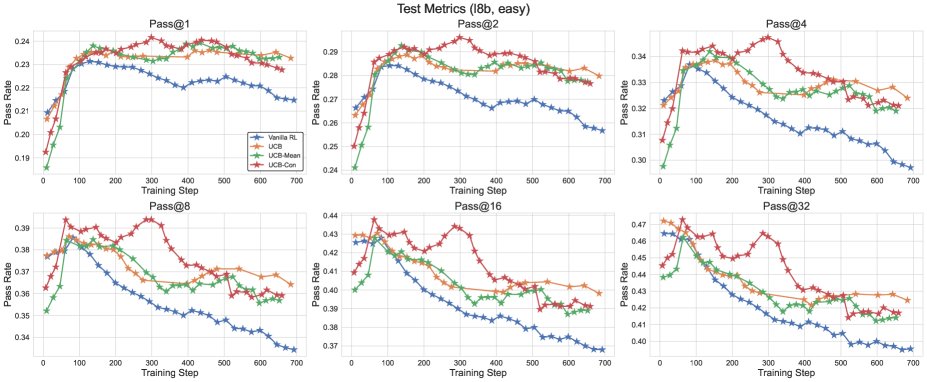
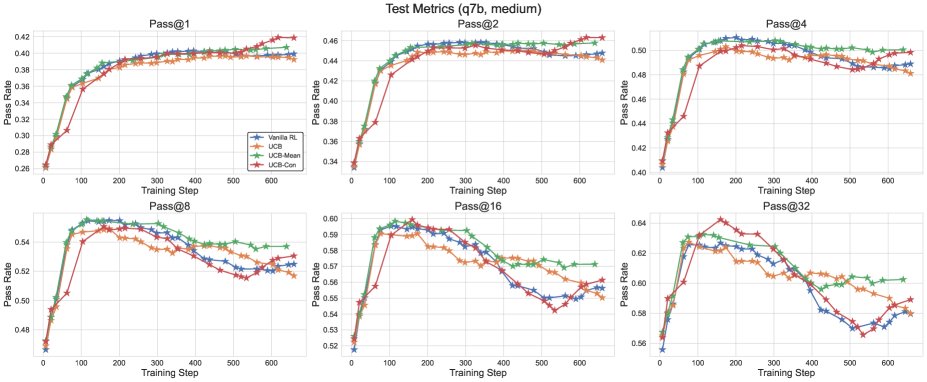 Figure 4: Test performance comparison between different UCB variants and the GRPO baseline.
Figure 4: Test performance comparison between different UCB variants and the GRPO baseline.
Batch Exploration (\(Batch Exploration\))
Historical exploration aims to find the optimal solution (optimizing \(pass@1\)), but it does not necessarily guarantee generation diversity at test time. To directly optimize test-time diversity (high-\(k\) \(pass@k\)), the paper proposes batch exploration. Its reward mechanism is replaced with:
\[b\_{\mathsf{batch}}\left(x,\{y\_{i},a\_{i}\}\_{i=1}^{n}\right)\_{i}=-\frac{1}{n}\sum\_{j\neq i}\mathbf{1}\{a\_{i}=a\_{j}\}\]This reward directly penalizes answers that repeatedly appear within the current batch, thereby incentivizing the model to generate more diverse answers for the same problem.
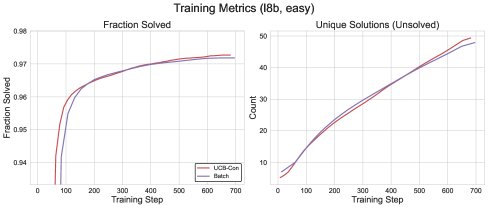
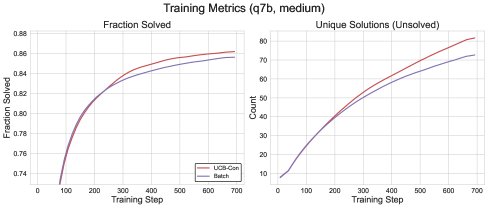 Figure 5: Comparison of the training performance of \(Batch\) and \(UCB-Con\).
Figure 5: Comparison of the training performance of \(Batch\) and \(UCB-Con\).
Theoretical Analysis: Outcome-Based Bandits
To theoretically justify the rationale behind “outcome-based exploration,” this paper proposes a new model called Outcome-Based Bandits. This model abstracts the inference process of LLMs: there are $K$ arms (representing reasoning paths), but only $m$ outcomes (representing final answers), where $m \ll K$.
- Theorem 4.1 (informal) shows that without additional generalization assumptions, simply partitioning by outcome does not reduce the problem complexity; the regret lower bound still depends on the number of arms $K$.
- Theorem 4.2 (informal) proves that if a reasonable generalization assumption is made (i.e., updating one reasoning path can affect other paths that produce the same answer), then an UCB-style exploration algorithm based on outcomes achieves a regret upper bound that depends only on the number of outcomes $m$, namely $O\left(\sqrt{mT\log T}\right)$. This theoretically demonstrates the sample efficiency of the proposed method.
Experimental Results
This paper conducted extensive experiments on the \(Llama\) and \(Qwen\) model families using mathematical reasoning datasets such as \(MATH\) and \(DAPO\).
Core Experimental Comparison
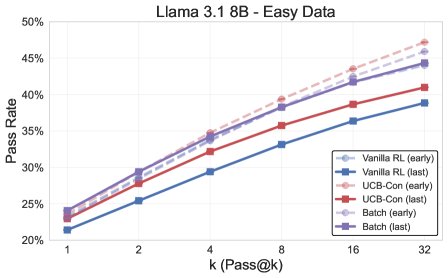
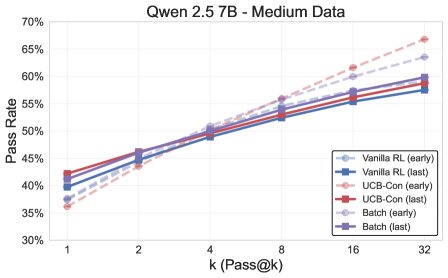 Figure 1: Overview of the final experimental results. The exploration methods (\(UCB-Con\) and \(Batch\)) outperform the baseline \(GRPO\) across the board on the \(pass@k\) metric.
Figure 1: Overview of the final experimental results. The exploration methods (\(UCB-Con\) and \(Batch\)) outperform the baseline \(GRPO\) across the board on the \(pass@k\) metric.
- Exploration methods comprehensively outperform the baseline: All proposed exploration methods (\(UCB-Mean\), \(UCB-Con\), \(Batch\)) almost always outperform the standard RL baseline (\(GRPO\)) on \(pass@k\) on the test set (for $k \in {1, …, 32}$).
- \(UCB-Con\) delivers the best performance gains: Among the historical-exploration variants, \(UCB-Con\) (with a constant baseline) performs best. It consistently improves performance across all $k$ values and effectively mitigates the over-optimization issue that appears in standard RL later in training (i.e., performance degradation).
- \(Batch\) offers a better diversity-accuracy trade-off: Although batch exploration (\(Batch\)) is less efficient than \(UCB-Con\) during training, it can produce more diverse answers at test time. Therefore, in the later stages of training, it excels on high-$k$ \(pass@k\), achieving a better accuracy-diversity trade-off and making it especially suitable for scenarios targeting test-time scalability.
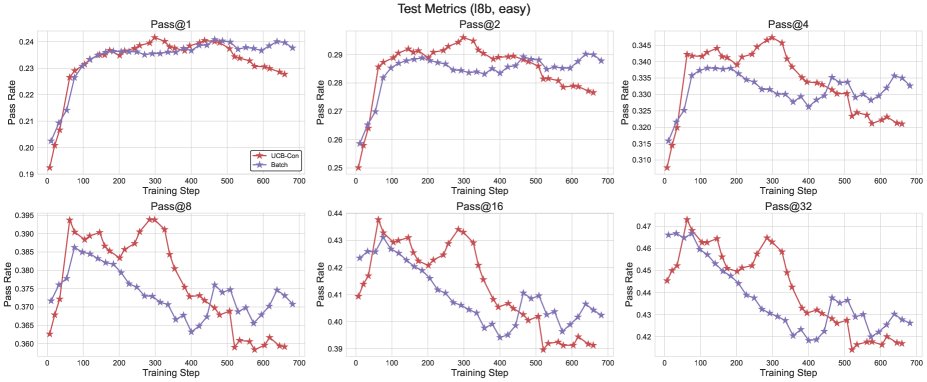
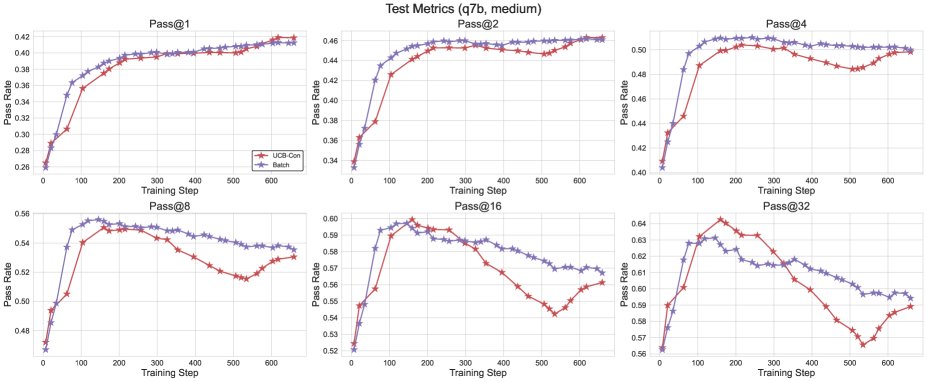 Figure 6: Comparison of the test performance of \(Batch\) and \(UCB-Con\). \(Batch\) shows an advantage on high-$k$ \(pass@k\) in the later stages of training.
Figure 6: Comparison of the test performance of \(Batch\) and \(UCB-Con\). \(Batch\) shows an advantage on high-$k$ \(pass@k\) in the later stages of training.
Additional Analysis
- Generation entropy: The \(Batch\) method has significantly higher token-level entropy when generating incorrect answers than \(GRPO\) and \(UCB-Con\), indicating that its generated content is inherently more variable.
| Correct generation | Incorrect generation | All | |
|---|---|---|---|
| \(GRPO\) | 0.080 (0.01) | 0.096 (0.04) | 0.095 (0.02) |
| \(UCB-Con\) | 0.084 (0.01) | 0.103 (0.03) | 0.100 (0.02) |
| \(Batch\) | 0.086 (0.01) | 0.153 (0.07) | 0.125 (0.03) |
Table 1: Comparison of the entropy of generated content across different methods.
- In-batch diversity: The \(Batch\) method also generates a significantly larger number of distinct answers within each batch, which is fully consistent with its design goal.
| Solved problems | Unsolved problems | All | |
|---|---|---|---|
| \(GRPO\) | 2.279 (0.018) | 4.805 (0.075) | 2.883 (0.024) |
| \(UCB-Con\) | 2.272 (0.020) | 4.855 (0.084) | 2.926 (0.035) |
| \(Batch\) | 2.284 (0.057) | 5.390 (0.102) | 3.230 (0.062) |
Table 2: Comparison of the number of distinct answers generated within each batch.
Summary
This paper confirms that outcome-based exploration is an effective way to address the loss of diversity during RL training. Historical exploration, especially \(UCB-Con\), can significantly improve overall reasoning accuracy, while batch exploration (\(Batch\)) maximizes generation diversity at test time while maintaining accuracy. These two methods are complementary and point to a practical and feasible direction for training LLM reasoning intelligent agents that are both accurate and diverse.