ORION: Teaching Language Models to Reason Efficiently in the Language of Thought
Is Large-Model Inference Too “Chatty”? ORION Compresses Reasoning Paths by 16x, Cutting Costs by 9x

Large models are getting stronger at complex reasoning tasks such as math and coding, but have you noticed that, in order to arrive at the correct answer, they often need to generate an extremely long “thought process”? This kind of “chatty” reasoning not only leads to high compute costs and latency, but also often introduces redundant or even contradictory steps.
ArXiv URL:http://arxiv.org/abs/2511.22891v1
Recently, researchers from Harvard, MIT, and Hippocratic AI proposed a brand-new solution: ORION. Inspired by the human “Language of Thought Hypothesis,” this work teaches large models to think in an extremely compressed symbolic language, shortening reasoning paths by 4-16x, reducing inference latency by 5x, and slashing training costs by 7-9x! Most impressively, while being so efficient, it still retains 90-98% of the original model’s accuracy, and even surpasses GPT-4o and Claude 3.5 Sonnet on some math benchmarks.
The “Chatty” Dilemma: Why Do Large Models Think So Much?
Since the advent of Chain-of-Thought (CoT), making models “think step by step and speak step by step” has become the mainstream paradigm for improving reasoning ability. Frontier models such as DeepSeek-R1 and OpenAI o1 also rely on generating detailed intermediate steps to solve complex problems.
However, this approach has also led to the phenomenon of “overthinking.” As shown in the figure below, even for simple questions, models may generate a large amount of verbose, repetitive text, in sharp contrast to the concise and efficient way humans think.

This verbosity not only wastes token, increases inference time and cost, but may also accumulate errors because of too many steps, ultimately reducing accuracy. How can we make models both thoughtful and concise? That is exactly the core problem ORION aims to solve.
Mentalese: A “Language of Thought” Built for Machines
The inspiration for this work comes from the cognitive science Language of Thought Hypothesis. The hypothesis suggests that human cognition does not operate directly in natural language, but rather in a more abstract and symbolic internal language, known as Mentalese.
Based on this, the researchers designed a compact symbolic reasoning format called Mentalese. It abandons the verbosity of natural language and uses a series of structured operators (such as \(SET\), \(CALC\), \(SOLVE\)) and expressions to describe the core logic of reasoning.

A Mentalese reasoning trajectory consists of a series of clearly defined steps, with each step containing only the core information needed to solve the problem. This makes the reasoning process highly compressed while preserving logical rigor and interpretability.
A Two-Stage Training Method: From Alignment to Optimization
To teach the model this efficient “language of thought,” ORION adopts a clever two-stage training pipeline.
Stage 1: Supervised Fine-Tuning (SFT) to Align with Mentalese
First, the researchers built a \(MentaleseR-40k\) dataset containing 40,000 math problems, each paired with an expert-written Mentalese reasoning path.
They then used this dataset to perform supervised fine-tuning (SFT) on a pretrained base model, such as DeepSeek R1 Distilled 1.5B. The goal was to teach the model to imitate this concise symbolic reasoning style.
But a problem emerged here: although SFT successfully compressed the reasoning process, it also caused a significant drop in model performance, with average accuracy falling by about 35%. This is because the strict symbolic format limited the model’s ability to explore and self-correct during reasoning.
Stage 2: Reinforcement Learning with SLPO
To recover performance without sacrificing conciseness, the team introduced reinforcement learning and proposed one of the paper’s core innovations: Shorter Length Preference Optimization (SLPO).
Traditional length-penalty methods are too blunt and may penalize longer thinking that is necessary to solve difficult problems. SLPO, by contrast, is much smarter:
Among multiple correct solutions generated by the model for the same problem, SLPO gives higher reward to the shortest one.
Its reward function is designed as follows:
\[R\_{\text{SLPO}}(y\_{\text{curr}})=\begin{cases}1,&\text{if } \mid \mathcal{C}(x\_{i}) \mid =1\ \text{or }\big( \mid \mathcal{C}(x\_{i}) \mid >1\ \text{\& }L\_{\min}=L\_{\max}\big),\[6.0pt] R\_{\text{correctness}}+\alpha\cdot\dfrac{L\_{\max}-L\_{\text{curr}}}{L\_{\max}-L\_{\min}},&\text{if } \mid \mathcal{C}(x\_{i}) \mid >1\ \text{and }L\_{\min}\neq L\_{\max},\[10.0pt] 0,&\text{if } \mid \mathcal{C}(x\_{i}) \mid =0,\end{cases}\]In simple terms, if all correct answers are the same length, or if there is only one correct answer, they all receive full reward. Only when there are multiple correct answers of different lengths does SLPO prefer the shorter one. This adaptive reward mechanism encourages conciseness while still allowing the model to engage in the deeper thinking needed for hard problems.
By aligning with Mentalese through SFT and then applying reinforcement learning with SLPO, the ORION model successfully preserved conciseness while recovering most of the performance lost earlier.

Stunning Experimental Results: Efficiency and Performance at the Same Time
How good is ORION? The data says it all.
The researchers conducted extensive tests on several challenging math reasoning benchmarks, including AIME, MinervaMath, and OlympiadBench.
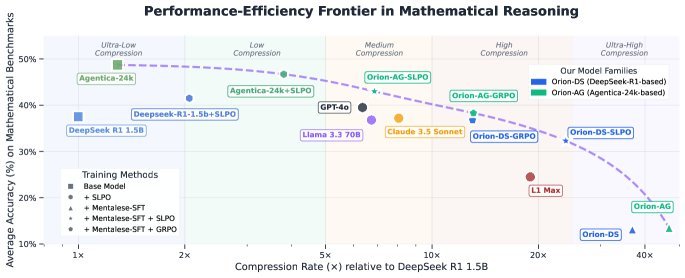
The figure above shows the trade-off between accuracy and compression rate across different models. The ORION series models (the orange and green points in the figure) consistently lie on the Pareto frontier, meaning that at the same compression rate, they achieve the highest accuracy; and at the same accuracy, they achieve the highest compression rate.
Specifically:
-
Extreme compression: Compared with baseline models, ORION shortens reasoning paths by 4-16x.
-
Outstanding performance: On multiple math benchmarks, the ORION 1.5B model outperforms GPT-4o and Claude 3.5 Sonnet by 5% in accuracy, while using only half as many reasoning tokens.
-
Sharp cost reduction: Thanks to the dramatic reduction in token count, inference latency drops by up to 5x, and training costs are 7-9x lower than with traditional RL methods.
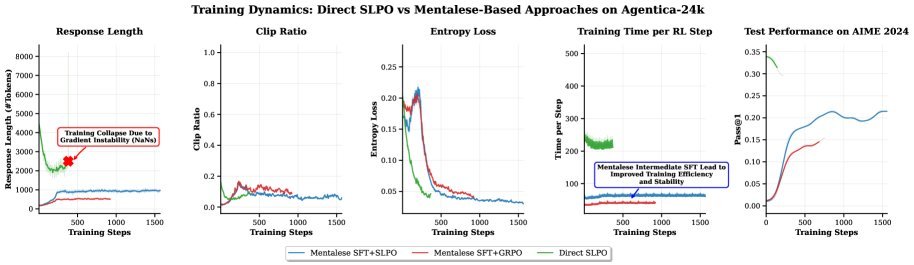
Even more interestingly, the study found that Mentalese alignment not only improves reasoning efficiency, but also significantly enhances training stability during the reinforcement learning stage, avoiding the “collapse” phenomenon caused by the model exploring overly long reasoning paths.
Conclusion and Outlook
The ORION framework strongly demonstrates that reasoning does not necessarily require verbose language. By reconstructing the model’s thought process into a human-like, compact symbolic language, and combining it with an intelligent SLPO optimization strategy, we can achieve a huge leap in reasoning efficiency without sacrificing accuracy—and even improving it.
This work opens up a new path for deploying high-efficiency, low-cost reasoning models, especially for application scenarios such as Agentic AI systems that are extremely sensitive to real-time performance and cost. It brings us one step closer to general artificial intelligence that can think as efficiently and precisely as humans.