Online Process Reward Leanring for Agentic Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2509.19199v2
-
Authors: Jianbin Jiao; Ke Wang; Fei Huang; Xiaoqian Liu; Yongbin Li; Junge Zhang; Yuchuan Wu
-
Publishing Institutions: Chinese Academy of Sciences; Tongyi Lab; University of Chinese Academy of Sciences
TL;DR
This paper proposes an agent reinforcement learning credit assignment strategy called Online Process Reward Learning (OPRL). By alternately optimizing a process reward model and the agent policy online, it seamlessly converts trajectory-level preferences into dense step-level rewards, enabling efficient and stable training of long-horizon large language model (LLM) agents without relying on extra data or step labels.
Key Definitions
The core of this paper is built around implicitly learned step rewards from online learning. The key definitions are as follows:
- Online Process Reward Learning (OPRL): A general credit assignment strategy for agent reinforcement learning (RL). It integrates seamlessly with standard online (on-policy) RL algorithms and trains a process reward model (PRM) online to convert trajectory-level preference signals into dense step-level rewards for policy updates.
- Process Reward Model (PRM): A language model that is alternately optimized with the agent policy. In OPRL, this is an implicit model that does not directly predict a score, but instead expresses reward through its probability distribution over actions. This PRM learns from trajectory-pair preferences via a Direct Preference Optimization (DPO)-based objective.
-
Implicit Step Rewards: The core output of OPRL. For the action $a_t$ at time $t$, its implicit step reward is defined as:
\[r_{\phi}(o_{1:t}, a_{t}) = \beta \log \frac{\pi_{\phi}(a_{t} \mid o_{1:t}, x)}{\pi_{\theta_{\text{old}}}(a_{t} \mid o_{1:t}, x)}\]
where $\pi_{\phi}$ is the currently updated PRM, and $\pi_{\theta_{\text{old}}}$ is the snapshot of the policy model from the previous round. This reward measures how much the current action improves over the old policy from the PRM’s perspective, thereby providing dense guidance signals for policy learning.
Related Work
At present, training large language model (LLM) agents in dynamic, interactive environments faces major challenges, with the main bottlenecks including:
- Sparse rewards and credit assignment: Environment rewards are usually only given at the end of a task, making it difficult to determine the contribution of intermediate steps, i.e., the temporal credit assignment problem.
- High-variance learning: Agent trajectories are long and complex, and assigning rewards at the token level introduces substantial noise, leading to high variance in policy learning and unstable training.
- Complexity of open environments: In open-ended environments such as dialogue, the state space is huge and rarely overlaps, and reward signals are often difficult to verify, causing many traditional RL methods to fail.
Existing process supervision methods each have their own limitations:
- Manual annotation or heuristic rules: Expensive, biased, and easily exploitable by agents through reward hacking.
- Generative reward models (GRMs): For example, using an LLM as a judge; the step-level feedback it provides may be noisy and inconsistent across domains.
- Token-level PRM: Although effective in single-turn tasks, for long-trajectory agent tasks its reward signal is too fine-grained, amplifying variance and hurting training stability.
- State grouping methods: These rely on exactly the same state appearing across different trajectories, which is almost impossible in language environments with huge state spaces.
This paper aims to address the above problems by proposing a general, label-free, efficient, and stable credit assignment strategy that can adapt to long-horizon agent tasks with sparse, delayed, or even unverifiable rewards.
Method
The proposed Online Process Reward Learning (OPRL) framework learns a process reward model (PRM) online, converting sparse trajectory-level outcome preferences into dense step-level reward signals to guide fine-grained policy updates.
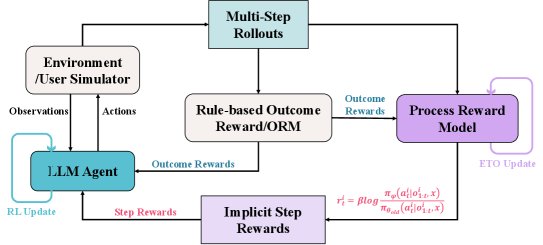
The figure above shows the overall training flow of OPRL: the agent interacts with the environment to generate trajectories, and an outcome reward model (ORM) evaluates the entire trajectory and provides an outcome reward. These trajectories with outcome labels are used to update the PRM, which then generates implicit process rewards for each step in the trajectory. Finally, the agent policy is updated using both the outcome reward and the implicit step rewards.
Core Procedure
The training process of OPRL is a self-improving loop in which the policy model $\pi_{\theta}$ and the process reward model $\pi_{\phi}$ are alternately optimized:
- Data sampling: Use the current policy $\pi_{\theta}$ to interact with the environment and generate a batch of trajectories.
-
PRM optimization: Based on the trajectories’ outcome rewards (provided by a verifier or ORM), construct preference pairs (e.g., a “successful” trajectory $\tau^{+}$ vs. a “failed” trajectory $\tau^{-}$). Then, update the PRM $\pi_{\phi}$ using a DPO-like objective:
\[\mathcal{J}_{\text{PRM}}(\phi)=-\mathbb{E}_{(\tau^{+},\tau^{-})\sim\pi_{\theta_{\text{old}}}}\left[\log\sigma\left(\beta\log\frac{\pi_{\phi}(\tau^{+} \mid x)}{\pi_{\theta_{\text{old}}}(\tau^{+} \mid x)}-\beta\log\frac{\pi_{\phi}(\tau^{-} \mid x)}{\pi_{\theta_{\text{old}}}(\tau^{-} \mid x)}\right)\right]\]
This process teaches the PRM to prefer trajectories that lead to better outcomes.
- Policy optimization: Use the updated PRM to compute the implicit step reward $r_{\phi}$ for each action. Then, combine two types of advantage functions to update the policy $\pi_{\theta}$:
-
Episode-level Advantage $A^{E}$: Computed from the final outcome reward $r_{o}(\tau)$, reflecting the global performance of the entire trajectory.
\[A^{E}(\tau_{i})=\big(r_{o}(\tau_{i})-mean(R_{o})\big)/std(R_{o})\]
-
-
Step-level Advantage $A^{S}$: Computed from the implicit step reward $r_{\phi}(a_t)$, reflecting the local contribution of a single action.
$$ A^{S}(a_{t}^{i})=\left(r_{\phi}(a_{t}^{i})-mean(R_{s})\right)/std(R_{s}) $$ -
Combined Advantage: The two advantages are weighted and combined to provide a more comprehensive signal for policy updates.
$$ A(a_{t}^{i})=A^{E}(\tau_{i})+\alpha{A^{S}(a_{t}^{i})} $$
Finally, the policy is updated using the surrogate objective of standard RL algorithms such as PPO.
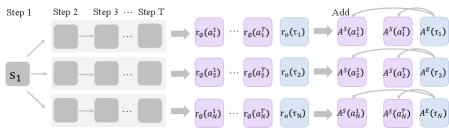
As shown above, when OPRL updates the policy, the final advantage function is a combination of the episode-level advantage $A^{E}(\tau)$ and the step-level advantage $A^{S}(a)$.
Innovations
- Label-free fine-grained credit assignment: OPRL cleverly converts sparse, trajectory-level outcome preferences into dense, step-level reward signals through a DPO-style objective, without requiring expensive and biased manual step labels.
- Low variance and training stability: By computing rewards at the step (turn) level rather than the token level, OPRL effectively controls reward granularity and avoids the high-variance problems caused by overly fine-grained signals. Theoretical analysis shows that the learned implicit step reward is a potential-based reward shaping reward, which preserves the optimal policy and provides bounded gradients, thereby stabilizing multi-turn RL training.
- Generality and scalability: This method relies only on trajectory-level preferences, which can come from rule-based verifiers (such as task success signals) or from unverifiable ORMs such as LLM judges, making it applicable across a wide range of environments, including open-ended dialogue. At the same time, OPRL can be plugged in with mainstream online RL algorithms such as PPO, GRPO, and RLOO.
Theoretical Analysis
This paper theoretically proves the effectiveness and stability of OPRL:
- Preference consistency: Under the Bradley-Terry preference model assumption, minimizing the PRM loss is equivalent to learning a scoring function consistent with the latent true utility function $R^{\star}$.
- Potential-based reward shaping: It is proven that the accumulated implicit step rewards $\sum r_{\phi}$ constitute a form of potential-based reward shaping for the true trajectory utility $R^{\star}$, and this shaping does not change the optimal policy set of the original task.
- Bounded gradients: It is proven that the reward term $ \mid r_{\phi} \mid $ in the policy gradient update is bounded, which ensures the stability of stochastic gradient optimization and makes the alternating update process between the PRM and the policy more robust.
Experimental Conclusions
Experiments were conducted on three challenging agent benchmarks: WebShop (web shopping), VisualSokoban (visual Sokoban), and SOTOPIA (open-ended social interaction).
Main Performance
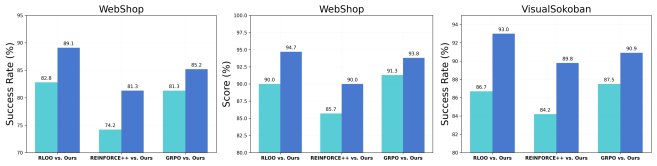
- Comprehensively surpassing the baselines: On the WebShop and VisualSokoban tasks, OPRL significantly outperforms frontier closed-source models including GPT-5 and Gemini-2.5-Pro, as well as strong RL baselines such as PPO, GRPO, PRIME, and GiGPO. For example, on VisualSokoban, the success rate reaches 91.7%, far exceeding other methods.
| Method | WebShop (Qwen2.5-7B) | VisualSokoban (Qwen2.5-VL-7B) | |
|---|---|---|---|
| Success Rate | Score | Success Rate | |
| GPT-5 | 37.5 | 66.1 | 16.6 |
| Gemini-2.5-Pro | 30.5 | 38.4 | 16.0 |
| Base Model (ReAct) | 21.5 | 47.3 | 14.1 |
| + RLOO | 77.4 ± 1.1 | 87.6 ± 4.7 | 86.3 ± 0.6 |
| + PRIME | 81.5 ± 1.8 | 91.3 ± 0.6 | - |
| + GiGPO | 84.1 ± 3.9 | 91.2 ± 1.5 | 85.9 ± 2.6 |
| OPRL (this paper) | 86.5 ± 2.8 | 93.6 ± 1.0 | 91.7 ± 1.2 |
- Excelling in open environments: In the SOTOPIA environment, where the state space is open and rewards are unverifiable, OPRL also performs strongly. Compared with the baselines, in difficult scenarios OPRL improves goal completion by 14% in Self-Chat mode and by as much as 48% when playing against GPT-4o.
| Model / Method | Self-Chat | Against GPT-4o | ||
|---|---|---|---|---|
| Goal (Hard) | Goal (All) | Goal (Hard) | Goal (All) | |
| Qwen2.5-7B | ||||
| + GRPO | 6.97 | 8.31 | 6.42 | 7.84 |
| + OPRL (this paper) | 7.11 | 8.42 | 6.76 | 8.36 |
| Llama3.1-8B | ||||
| + GRPO | 7.92 | 9.12 | 6.68 | 8.14 |
| + OPRL (this paper) | 8.06 | 9.20 | 7.16 | 8.45 |
- General applicability across different RL algorithms: Experiments show that OPRL can consistently improve the performance of a variety of RL algorithms, including RLOO, REINFORCE++, and GRPO, demonstrating its strong generality and robustness.
Sample Efficiency and Training Stability
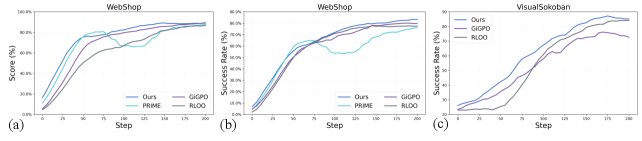
- OPRL demonstrates excellent sample efficiency and training stability. As shown in the figure above, compared with the baselines, OPRL converges to a higher performance level more quickly, and the performance curves during training are smoother with smaller fluctuations. For example, on WebShop, OPRL reaches the final performance of the baseline RLOO method in only 105 steps, improving training efficiency by about 2x. This verifies that its step-level reward signal can effectively reduce gradient variance and enable more stable policy updates.
Exploration Efficiency Analysis

- OPRL enables more efficient exploration. As shown in the figure above, during the early stage of training, the implicit step reward rises rapidly first, and then drives the growth of episode reward. This indicates that the agent first learns effective local action heuristics and then combines them into complete high-reward trajectories. Meanwhile, as training progresses, the average number of steps required for the agent to complete the task decreases significantly, proving that OPRL can guide the agent to reduce unnecessary actions and improve exploration efficiency.
Ablation Study
The ablation study validates the key design choices of OPRL:
- Fusion at the advantage level is crucial: Directly adding step rewards and outcome rewards together (w/ merged rewards) performs far worse than OPRL, which fuses them at the advantage level. This shows that the final outcome must be used to adjust the credit assigned to intermediate steps, preventing the agent from engaging in reward-hacking behavior.
- Step-level rewards are better than token-level rewards: Using token-level process rewards (w/ token-level PR) performs suboptimally on long-horizon tasks, indicating that overly fine-grained rewards introduce noise and make policy learning harder.
- Learned rewards are better than environment-provided rewards: Compared with using the true step penalties provided by the VisualSokoban environment (w/ ground-truth PR), the implicit rewards learned by OPRL bring larger performance gains, proving the superiority of its reward signal.
| Method Ablation | WebShop | VisualSokoban | |
|---|---|---|---|
| Success Rate | Score | Success Rate | |
| RLOO (baseline) | 76.6 | 84.2 | 85.9 |
| w/ ground-truth PR | - | - | 87.5 |
| w/ merged rewards | 81.3 | 90.7 | 88.3 |
| w/ token-level PR | 82.0 | 90.0 | 89.1 |
| OPRL | 86.5 | 93.6 | 91.7 |
In summary, OPRL is an efficient, stable, and general credit assignment strategy that significantly improves the performance of LLM agents across a variety of interactive environments.