On the Theoretical Limitations of Embedding-Based Retrieval
-
ArXiv URL: http://arxiv.org/abs/2508.21038v1
-
Authors: Jinhyuk Lee; Orion Weller; Iftekhar Naim; Michael Boratko
-
Publisher: Google DeepMind; Johns Hopkins University
TL;DR
This paper connects learning theory with embedded retrieval, and both theoretically and empirically shows that single-vector embedding models, due to their dimensionality limits, cannot represent all possible combinations of relevant documents. It also constructs a simple dataset called LIMIT, revealing that even state-of-the-art models today have this fundamental limitation.
Key Definitions
The core argument of this paper is built on a mathematical formalization of the retrieval problem and vector representation capacity. The key definitions are as follows:
- row-wise order-preserving rank (\($\operatorname{rank}\_{\text{rop}} A\)$): For a given $m \times n$ relevance matrix $A$, this rank is the minimum embedding dimension $d$ that can produce an $m \times n$ score matrix $B$ (i.e., the rank of $B$) such that the order of elements in each row of $B$ is consistent with the order in the corresponding row of $A$. In short, it is the minimum embedding dimension needed to correctly rank relevant and irrelevant documents for all queries.
- row-wise thresholdable rank (\($\operatorname{rank}\_{\text{rt}} A\)$): The minimum embedding dimension $d$ such that there exists a score matrix $B$ of rank $d$, and for each row (each query) there exists a threshold $\tau_i$ that can completely separate the scores of relevant documents from those of irrelevant documents.
- globally thresholdable rank (\($\operatorname{rank}\_{\text{gt}} A\)$): The minimum embedding dimension $d$ such that there exists a score matrix $B$ of rank $d$, and there exists a single global threshold $\tau$ that can completely separate the scores of relevant documents from those of irrelevant documents across all queries.
- Sign Rank (\($\operatorname{rank}\_{\pm} M\)$): A concept from communication complexity theory. For a matrix $M$ whose entries are -1 or 1, its sign rank is the minimum possible rank of any real-valued matrix $B$ that has the same sign pattern as $M$. This paper establishes a direct connection between the representational capacity of retrieval models and sign rank.
Related Work
Current neural-network-based embedding models (i.e., dense retrieval) are being used to tackle increasingly complex retrieval tasks, such as instruction-following and multimodal retrieval. A common trend in the community is to push models toward handling “any query” and “any definition of relevance,” implicitly assuming that embedding models have unlimited representational capacity.
However, existing academic benchmarks (such as MTEB and QUEST) usually contain only a limited number of queries due to annotation costs and other reasons. These queries cover only a tiny fraction of all possible combinations of relevant documents, thereby masking the potential representational bottlenecks of embedding models. Although some studies have empirically explored the effect of dimensionality, there has been no solid theoretical foundation to explain the fundamental limitation.
This paper aims to fill this gap, specifically asking: do single-vector embedding models have a fundamental, theoretical limitation in representing all possible top-k combinations of relevant documents? How is this limitation related to the embedding dimension $d$? And can this theoretical limitation appear in practice in a simple form?
Method
Theoretical Foundation and Formalization
The paper first formalizes the retrieval problem mathematically. Given $m$ queries and $n$ documents, their relevance can be represented by a binary matrix $A \in {0, 1}^{m \times n}$ (called qrels in information retrieval). An embedding model maps query $i$ to a vector $u_i \in \mathbb{R}^d$ and document $j$ to a vector $v_j \in \mathbb{R}^d$. Retrieval scores are computed by the dot product $u_i^T v_j$. All scores form a score matrix $B = U^T V$, whose rank is at most $d$.
The paper’s main theoretical contribution is to connect the requirement of “being able to retrieve correctly” with matrix rank, and to introduce the concepts of \(rop-rank\) and \(rt-rank\) defined above. Through a series of proofs, it derives the following key relationship:
\[\operatorname{rank}_{\pm}(2A-\mathbf{1}_{m\times n})-1 \leq \operatorname{rank}_{\text{rop}}A = \operatorname{rank}_{\text{rt}}A \leq \operatorname{rank}_{\text{gt}}A \leq \operatorname{rank}_{\pm}(2A-\mathbf{1}_{m\times n})\]This chain of inequalities tightly binds the minimum embedding dimension $d$ required by the model (i.e., \(rop-rank\)) to the sign rank of the relevance matrix $A$ (\($sign-rank\)).
Innovations
The essential innovation of this paper is that it does not propose a new model, but instead reveals the ceiling of the existing paradigm at the theoretical level. Its core ideas are:
- Connecting theory and practice: For the first time, the concept of “sign rank” from communication complexity theory is introduced into modern neural information retrieval, providing a solid mathematical tool for analyzing the representational capacity of embedding models.
- Proving a fundamental limitation: It proves that for any given embedding dimension $d$, there always exist some combinations of relevant documents (i.e., a qrel matrix $A$) that cannot be perfectly represented by a $d$-dimensional embedding model. This is because the sign rank of qrel matrices can be arbitrarily high, while the model’s representational capacity is constrained by the dimension $d$.
Theory-Based Empiricism and Dataset Construction
To validate the theory and demonstrate its real-world impact, the paper designs a two-layer empirical study.
Optimization Experiments in the Best Case
To eliminate confounding factors such as natural language modeling, the paper designs a “free embedding” optimization experiment. In this experiment, the vectors of queries and documents themselves are directly optimizable parameters, with the goal of directly fitting a given qrel matrix. This represents the upper bound of what any embedding model can achieve.
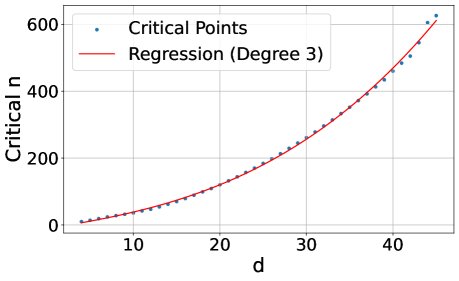
- Experimental setup: For a given embedding dimension $d$ and top-k value $k$ (this paper sets $k=2$), the number of documents $n$ is gradually increased until the model can no longer represent all $\binom{n}{k}$ combinations of relevant documents with 100% accuracy. This critical point is called critical-n.
- Results: The experiment finds a cubic polynomial relationship between critical-n and the dimension $d$. Extrapolating from this relationship, even a 4096-dimensional embedding could, in the ideal case, handle all top-2 combinations for only about 250 million documents, which is far from sufficient for web-scale corpora.
The LIMIT Dataset
To reproduce the above theoretical limitation in a real natural-language setting, the paper constructs a new dataset called LIMIT (Limitations of Instructions & Meaning In Text).
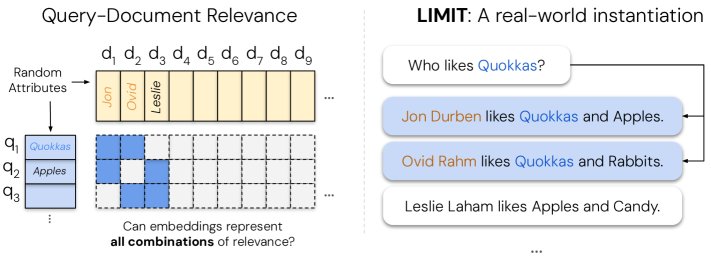
- Construction idea: Create a task that is extremely simple semantically and lexically, but extremely complex combinatorially. This can effectively isolate the bottleneck of the model’s representational capacity rather than its language understanding ability.
- Construction process:
- Choose a difficult qrel pattern: The theory suggests that when a qrel matrix contains as many document combinations as possible, its sign rank is highest and it is most challenging for the model. Therefore, a qrel matrix covering all top-2 combinations of 46 documents was chosen (a total of $\binom{46}{2} = 1035$ queries).
- Instantiate it in natural language: Map this abstract qrel matrix to a simple “attribute preference” task. The queries are “Who likes X?” (e.g., “Who likes apples?”), and the documents are in the form “Jon likes apples, bananas…” and so on.
- Increase the difficulty: Embed these 46 “core” documents into a corpus containing 50,000 documents, with the remaining documents serving as distractors. A “small” version containing only the 46 core documents is also provided.
- Advantages: The cleverness of the LIMIT dataset is that it is very easy for high-dimensional sparse models like BM25 (because it relies on lexical matching), but it poses a huge challenge for embedding models that rely on low-dimensional dense vector representations of semantics.
Experimental Conclusions
The paper evaluates LIMIT on a range of SOTA embedding models and conducts an in-depth analysis.
Key Findings
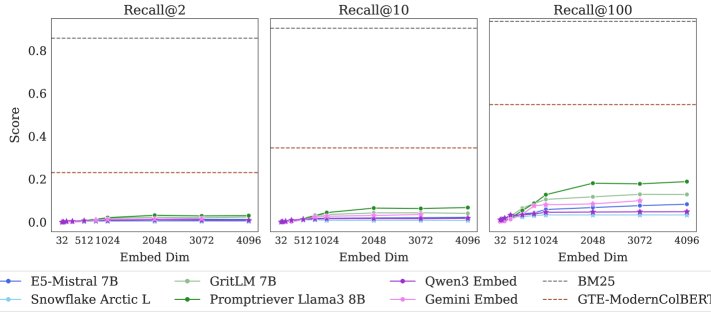
- SOTA models fail badly: On the LIMIT dataset, all single-vector embedding models perform extremely poorly. On the full 50,000-document version, even the best model achieves less than 20% Recall@100. On the small version with only 46 documents, the models still cannot fully solve the task (Recall@20 does not reach 100%). This shows that the theoretical limits do exist in practice and have a major impact.
- Dimension is the key factor: Model performance is significantly and positively correlated with embedding dimension $d$. The higher the dimension, the better the performance, but it still remains far from solving the task. This is fully consistent with theoretical predictions.
- Alternative architectures perform better:
- Sparse models: BM25, by virtue of being equivalent to an extremely high-dimensional vector space, almost perfectly solves the task.
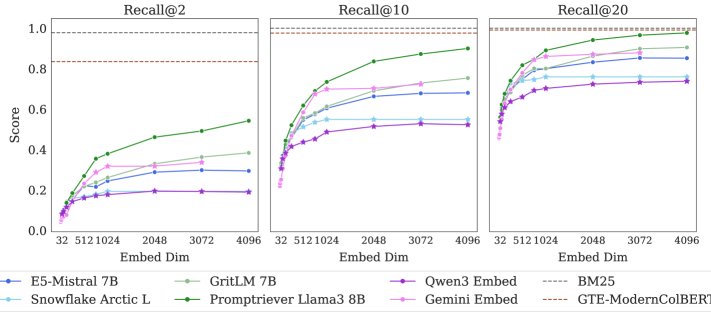
- Multi-vector models: Models such as ColBERT perform significantly better than all single-vector models, demonstrating stronger representational capacity.
- Rerankers: Long-context reranking models, such as Gemini 2.5 Pro, can process all documents and queries at once and complete the task with 100% accuracy, showing that the task itself is not logically difficult; the bottleneck lies in the representation used by first-stage retrieval.
Further Analysis
-
Not domain shift: Experiments show that fine-tuning on a LIMIT-style training set brings only a minimal performance gain. However, if the model is trained directly on the test set (i.e., overfits), it can learn the task. This indicates that the poor performance is due to the task’s inherent combinatorial difficulty, not because the model is poorly adapted to the data domain.
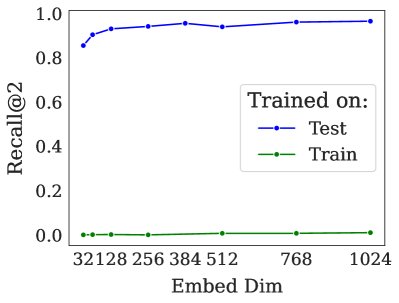
-
The importance of qrel patterns: By constructing LIMIT variants with different qrel patterns (such as random, cyclic, and disjoint) for comparison, the experiments found that the “dense” combinatorial pattern used in this paper—i.e., including all $\binom{n}{k}$ combinations—is indeed much harder than the others, validating the dataset design’s core assumption.
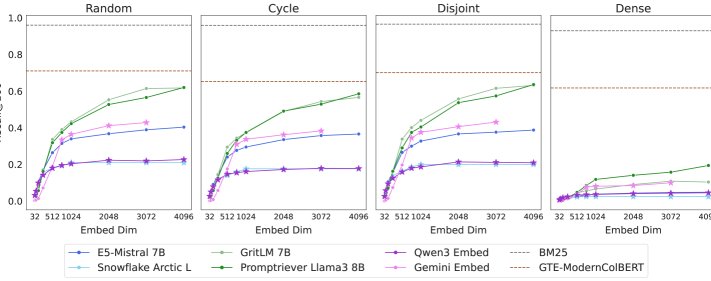
-
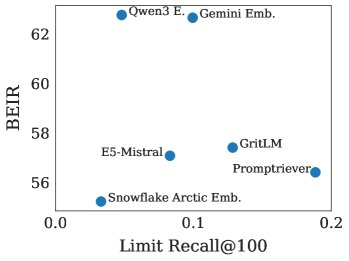
No correlation with mainstream benchmarks: Model performance on LIMIT shows no obvious correlation with performance on BEIR (the core of MTEB-v1), suggesting that existing mainstream benchmarks may not adequately test models’ combinatorial representation ability, and that models may already be overfitting to these benchmarks.
Summary
The experimental results in this paper strongly confirm its theoretical predictions: single-vector embedding models have a fundamental representational ceiling determined by their dimensionality. As retrieval tasks—especially instruction-following tasks—become increasingly complex and require models to distinguish and combine document sets never seen before, this theoretical limit will become a serious practical bottleneck. Therefore, the community should be fully aware of this limitation when evaluating and designing next-generation retrieval systems, and should actively explore more expressive architectures such as multi-vector, sparse representations, or hybrid models.