On GRPO Collapse in Search-R1: The Lazy Likelihood-Displacement Death Spiral
Cracking the “Death Spiral” in AI Agent Training: LLDS Boosts Qwen2.5 Performance by 37.8%

When AI agent (Agent) learn to use external tools such as search engines, their ability to solve complex problems undergoes a qualitative leap. However, a shortcut-like training method—Group Relative Policy Optimization (GRPO)—hides a fatal flaw: during training, models often “suddenly die” without warning, and performance plummets.
ArXiv URL:http://arxiv.org/abs/2512.04220v1
Why does this happen? Recently, researchers from top institutions such as UBC and UC Berkeley finally identified the culprit behind this “tragedy” and proposed an extremely simple yet effective “antidote.” It not only stabilized training, but also sent Qwen2.5 series model performance soaring across multiple question-answering tasks, with gains of up to 37.8%!
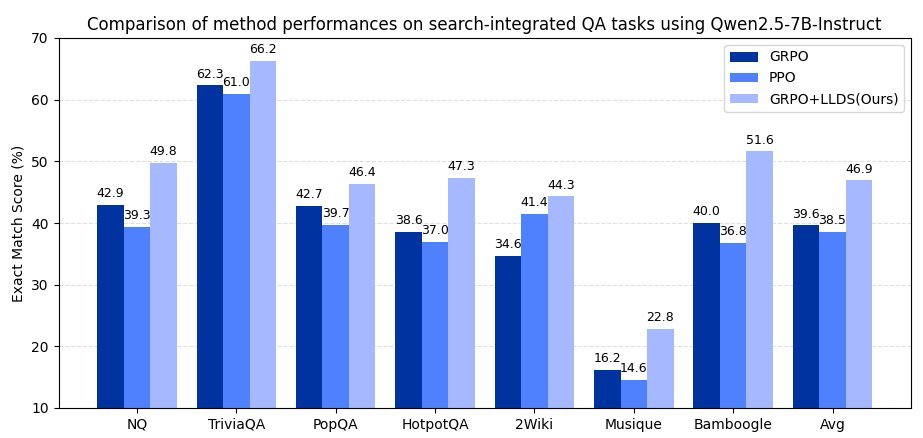
The “Achilles’ Heel” of AI agent: GRPO and Training Collapse
For large models to learn to use tools, reinforcement learning (RL) is a necessary path.
GRPO is favored in the field of Tool-Integrated Reinforcement Learning (TIRL) for its fast convergence and lack of a value function requirement; the well-known work Search-R1 adopted this method.
However, beneath the appealing surface lies a harsh reality.
Researchers found that AI agent trained with GRPO, especially on complex tasks requiring multi-turn tool interactions, often suffer catastrophic training collapse.
The model’s reward value can suddenly drop off a cliff, as if it had forgotten all its skills overnight.
Although this phenomenon has long been observed, the underlying root cause has remained a mystery.
Uncovering the Truth: Lazy Likelihood Displacement and the “Death Spiral”
This study is the first to systematically point to the root of the problem: Lazy Likelihood Displacement (LLD).
It is a concept that sounds a bit awkward, but the phenomenon itself is very intuitive.
Simply put, during GRPO optimization, the model’s “confidence” in both correct and incorrect answers—that is, the likelihood of generating them—becomes stagnant or even declines systematically.
The whole process can be divided into three alarming stages:
-
Early stagnation: In the early stage of training, although task rewards are rising, the likelihood of the correct answer remains stuck in place.
-
Stable decay: As training continues, the likelihood begins to decline monotonically, and warning signs have already appeared.
-
Accelerated collapse: The likelihood drops sharply, causing gradient explosion and ultimately triggering a reward avalanche.
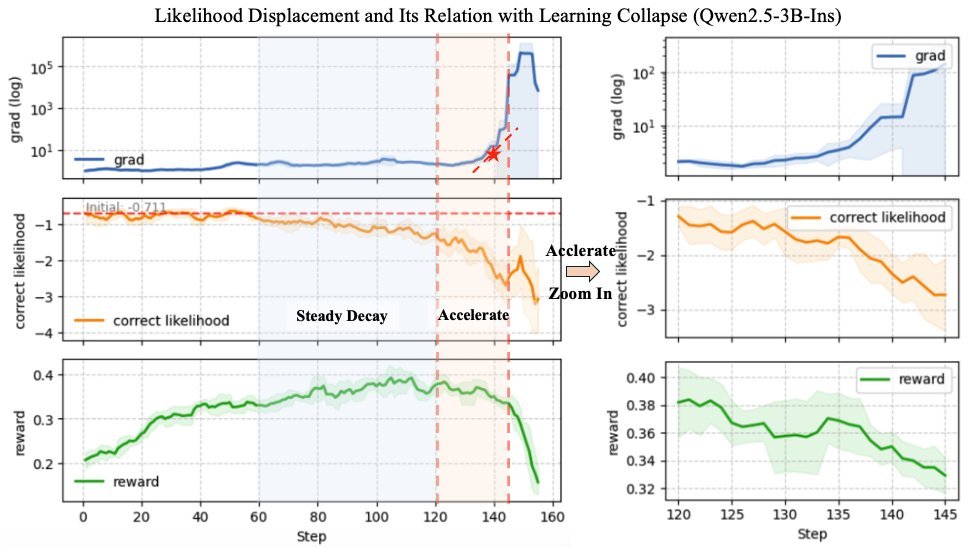
The researchers named this self-reinforcing vicious cycle the LLD Death Spiral:
Likelihood drops ➡️ the model lacks confidence ➡️ negative gradients from low-likelihood wrong answers are amplified ➡️ the likelihood of the correct answer is further suppressed ➡️ gradient explosion ➡️ total collapse!
As shown in the figure below, on the eve of collapse, the model’s entropy (uncertainty) surges sharply, which is a clear signal that the LLD problem is worsening.
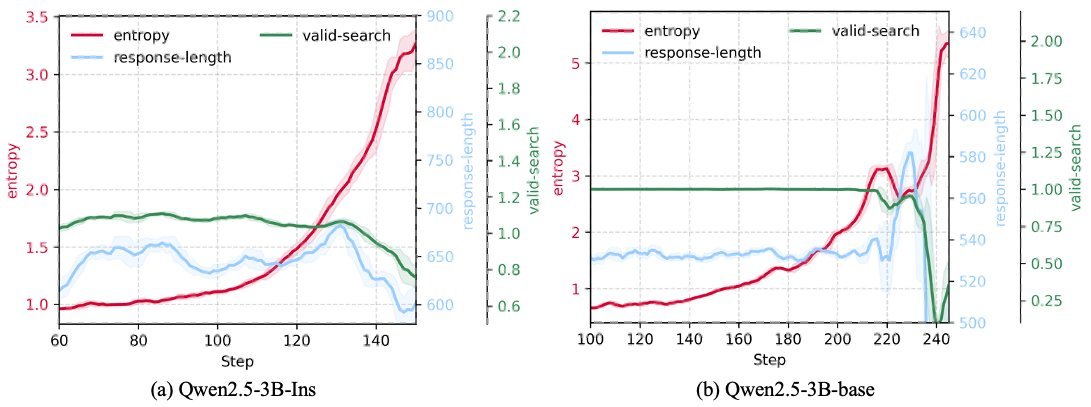
Precise “Surgery”: The Lightweight Regularization Method LLDS
Having identified the cause, how should it be treated? The researchers proposed a lightweight likelihood-preserving regularization method called LLDS (Likelihood-Preserving Regularization).
The design of LLDS is remarkably precise and elegant, like “surgical” intervention.
It intervenes only when necessary and only on the necessary parts, with its core built on two clever selection mechanisms:
-
Response-level gating: The regularization term is activated only when the overall likelihood of a trajectory (response) declines.
-
Token-level selectivity: Once activated, it penalizes only the specific tokens that cause the likelihood to drop.
Its core idea can be expressed by the following formula:
\[L\_{\rm LLDS} = \mathbf{1}\!\left[\Delta\_{\text{total}} > 0\right] \cdot \sum\_{y\_{i}\in\mathbf{y}} \max\left(0, \Delta\_{y_i}\right)\]Here, $ \mathbf{1}[\cdot] $ is the response-level gate, which takes effect only when the likelihood of the entire response decreases ($\Delta_{\text{total}} > 0$). Meanwhile, $ \max(0, \cdot) $ ensures that only tokens with declining likelihood ($\Delta_{y_i} > 0$) are penalized.
This “just enough” design can effectively prevent the likelihood from falling for no reason while minimizing interference with normal GRPO optimization.
Stunning Results: Full Stability and a Leap in Performance
The effects of LLDS were immediate.
The researchers conducted experiments on the Base and Instruct versions of Qwen2.5-3B and 7B. The results showed that native GRPO training collapsed within 300 steps in every case.
After adding LLDS, however, training for all models became exceptionally stable, rewards kept rising, and the models successfully escaped the fate of the “death spiral.”
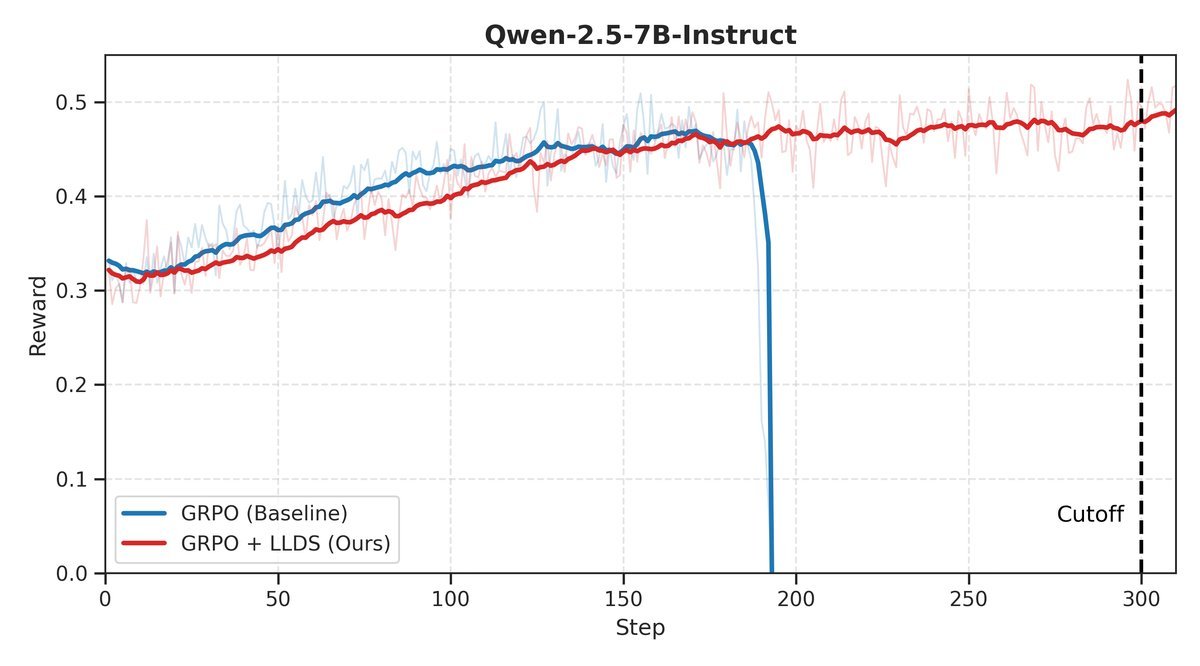
More importantly, stable training brought tangible performance gains.
Across 7 benchmarks covering general question answering and multi-hop question answering, LLDS achieved an across-the-board victory.
-
On the Qwen2.5-3B model, performance improved by an average of +37.8%.
-
On the Qwen2.5-7B model, performance improved by an average of +32.0%.
These results eloquently demonstrate that LLDS is not only GRPO’s “savior,” but also the “catalyst” that unlocks its potential.
Conclusion
This study not only reveals the deep reason why GRPO frequently collapses in tool-integrated scenarios—Lazy Likelihood Displacement (LLD)—but also provides a plug-and-play solution with remarkable results: LLDS.
It also offers an important lesson for all AI researchers and engineers: when training AI agent, don’t just stare at the reward curve!
The dynamic changes in likelihood are a earlier and more reliable “health barometer.” By monitoring and maintaining stable likelihood values, we can build more powerful and more reliable AI agent, enabling them to move steadily and far on the road toward artificial general intelligence.