Object Recognition Datasets and Challenges: A Review
-
ArXiv URL: http://arxiv.org/abs/2507.22361v1
-
Author:
-
Publishing Organization: University of British Columbia
TL;DR
This article provides a comprehensive review and analysis of object recognition datasets and challenges through statistics and descriptions of more than 160 datasets, with a focus on the key role datasets play in driving algorithm development, the evolution of major datasets, and changes in evaluation benchmarks.
Key Definitions
This article mainly follows and organizes the core concepts already established in the computer vision field, and does not propose any new definitions. The key concepts are as follows:
- Object Recognition: A general term covering a series of related computer vision tasks, including image classification, object localization, object detection, instance segmentation, and semantic segmentation.
- Image Classification: Assigning a category label to an entire image.
- Object Detection: Locating objects of interest in an image and assigning category labels to them, usually via bounding boxes.
- Semantic Segmentation: Assigning a category label to each pixel in an image (category-aware), without distinguishing different instances of the same class.
- Instance Segmentation: Identifying object boundaries at the pixel level and distinguishing different instances of the same category (instance-aware).
- Panoptic Segmentation: Combining semantic segmentation and instance segmentation to segment all pixels in an image, recognizing both instances of “things” (countable objects) and segmenting “stuff” (background regions).
Related Work
Object recognition is one of the foundational tasks in computer vision. As research has advanced, especially with the rise of deep learning, algorithm performance has become increasingly dependent on large-scale, high-quality training data. At every stage of algorithm development, corresponding datasets have been built to match the capabilities of the state-of-the-art algorithms of the time.
However, although the existing literature contains many reviews of algorithmic progress and applications, there is a lack of a review that specifically and deeply analyzes the object recognition field from the perspective of dataset development. This article aims to fill that gap by examining in detail the evolution, challenges, and trends of mainstream object recognition datasets over the past two decades, providing researchers with a comprehensive understanding of the role data plays in object recognition and pointing the way for future dataset construction.
Background
Overview of Object Recognition Tasks
Object recognition is a general term that covers multiple specific tasks. These tasks differ in granularity and objectives, forming a hierarchical understanding framework.
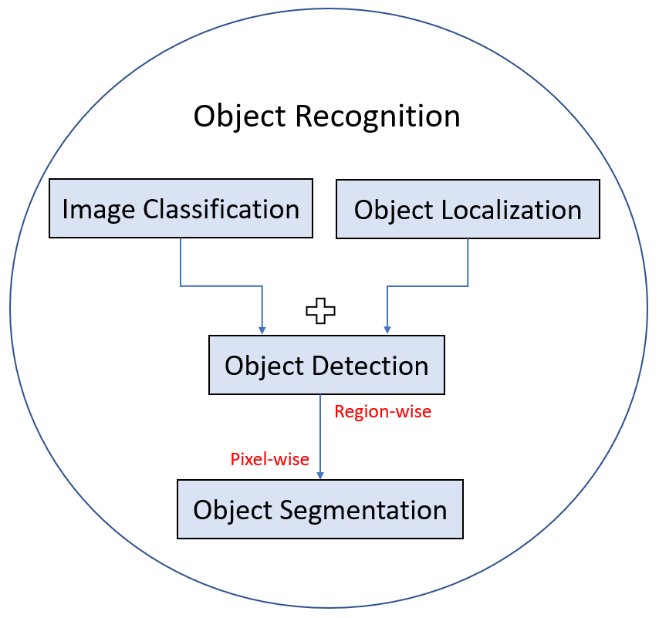
- Image Classification: Determining which category the entire image belongs to.
- Object Localization: Marking the position of one or more objects in an image with bounding boxes.
- Object Detection: Combining localization and classification to find all objects of interest and assign them categories.
- Image Segmentation: Partitioning at the pixel level.
- Semantic Segmentation: Labeling the category to which each pixel belongs (e.g., all pixels labeled as “car”).
- Instance Segmentation: Not only labeling the category, but also distinguishing different individuals of the same category (e.g., “car 1,” “car 2”).
Milestones in the History of Object Recognition
The development of object recognition algorithms and datasets is closely tied to technological progress and can roughly be divided into two stages: before and after the rise of deep learning.
Pre-deep-learning era (before 2012): Early algorithms mainly relied on sophisticated hand-crafted features designed for specific applications, such as SIFT (Scale-Invariant Feature Transform) and HOG (Histogram of Oriented Gradients). Datasets were also mostly created for specific applications, such as FERET for face recognition and MNIST for handwritten digit recognition. These datasets typically had low resolution, simple scenes, and controlled object poses. The introduction of the PASCAL VOC challenge series provided a standard benchmark platform for algorithms at the time and drove the field forward.
Deep learning era (2012 to present): In 2012, AlexNet achieved a breakthrough success in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), marking the arrival of the deep learning era. This demonstrated the importance of large-scale, high-quality annotated datasets in unleashing the potential of deep neural networks (DCNNs). Since then, both algorithms and datasets have become much more complex.
- Algorithm evolution: A series of classic deep learning models emerged, such as the R-CNN family (R-CNN, Fast R-CNN, Faster R-CNN), SSD, the YOLO family, Mask R-CNN for instance segmentation, and the DeepLab family and U-Net for semantic segmentation.
- Dataset evolution: Datasets have moved toward larger scale, finer-grained annotations (from bounding boxes to pixel-level masks), and more natural scenes (rather than iconic views).
The figure below shows the key milestones in the development of object recognition algorithms and datasets. 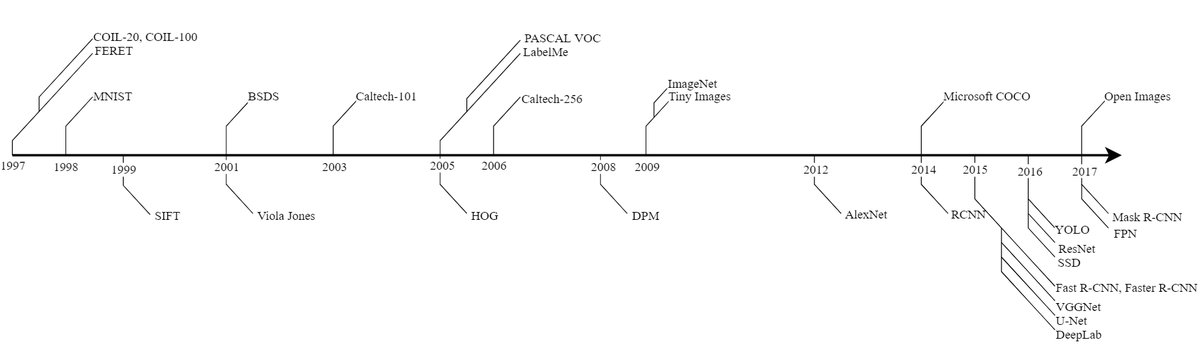
Evaluation Metrics
To quantitatively evaluate algorithm performance, this article introduces several core metrics. These metrics are based on the following four basic concepts:
- True Positive (TP): Correctly predicted as positive.
- False Positive (FP): Incorrectly predicted as positive.
- True Negative (TN): Correctly predicted as negative.
- False Negative (FN): Incorrectly predicted as negative.
Main Evaluation Metrics
-
Precision: Among the samples predicted as positive, how many are truly positive.
\[Precision=\frac{TP}{TP+FP}\] -
Recall: Among all true positive samples, how many are successfully predicted.
\[Recall=\frac{TP}{TP+FN}\] -
Accuracy: The proportion of all samples that are correctly predicted.
\[Accuracy=\frac{TP+TN}{TP+TN+FP+FN}\] -
$F_1$ Score: The harmonic mean of precision and recall, used to jointly consider both.
\[F_1=2\frac{precision\times recall}{precision+recall}\] -
Intersection over Union (IoU): The area of intersection between the predicted region and the ground-truth region divided by the area of their union; a commonly used metric for measuring the accuracy of predicted regions in detection and segmentation tasks.
\[IoU=\frac{Area of Overlap}{Area of Union}=\frac{TP}{TP+FN+FP}\] - Average Precision (AP): The average precision at different recall levels, often used to evaluate detection or segmentation performance for a single class. By averaging AP across all classes, we obtain mean Average Precision (mAP).
-
Panoptic Quality (PQ): Used to evaluate panoptic segmentation tasks, measuring both segmentation quality and detection quality.
\[PQ=\frac{\sum_{(p,q)\in TP}IoU(p,g)}{ \mid TP \mid +\frac{1}{2} \mid FP \mid +\frac{1}{2} \mid FN \mid }\]
Here, the first term is the mean IoU of matched segments (segmentation quality), and the second term is the class $F_1$ score (detection quality).
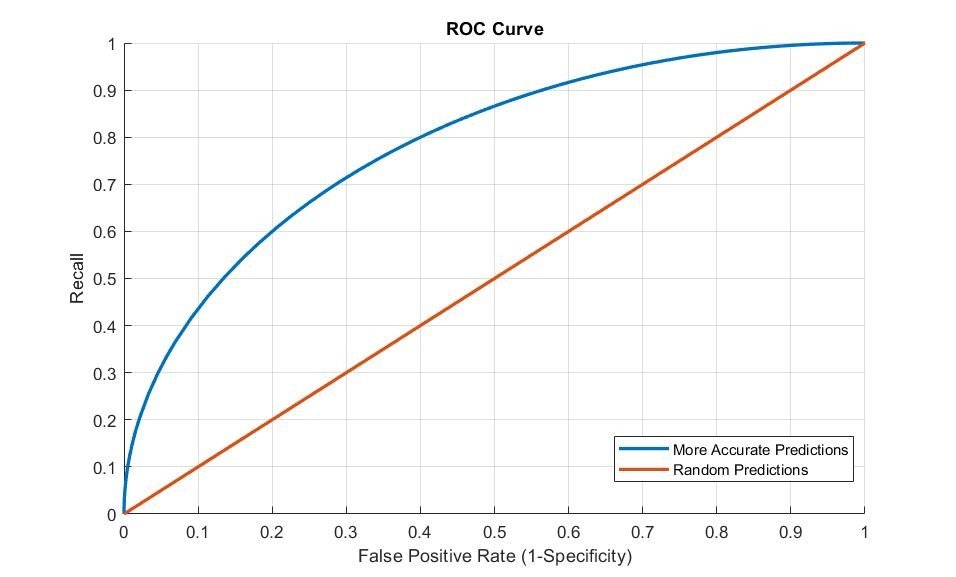 Figure 3: ROC Curve
Figure 3: ROC Curve
- Receiver Operative Characteristic (ROC) Curve: Evaluates classifier performance by plotting the relationship between the true positive rate (recall) and the false positive rate (1-specificity). The larger the area under the curve (AUC), the better the performance.
General Object Recognition Datasets
In recent years, the number of publicly available annotated datasets has surged. This section reviews general object recognition datasets and their related challenges.
Major Large-Scale Datasets
There are four widely recognized major large-scale object recognition datasets that have greatly driven the development of the field.
| Dataset | Number of Classes | Number of Images | Average Objects per Image | First Released | | :— | :— | :— | :— | :— | | PASCAL VOC | 20 | 22,591 | 2.3 | 2005 | | ImageNet | 21,841 | 14,197,122 | 3 | 2009 | | Microsoft COCO | 91 | 328,000 | 7.7 | 2014 | | Open Images | 600 | 9,178,275 | 8.1 | 2017 | Table 1: Dataset statistics for PASCAL VOC, ImageNet, MS COCO, and Open Images
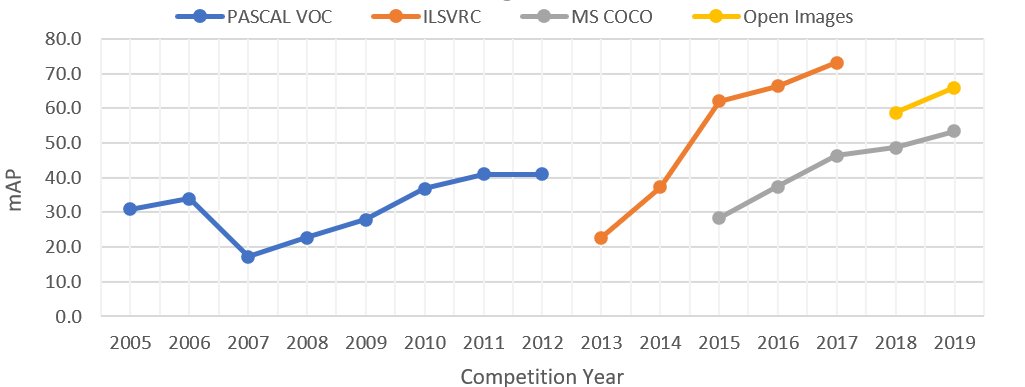 Figure 4: Accuracy improvements of winning algorithms in the object detection tracks of major challenges. The drop in PASCAL VOC 2007 accuracy is due to the number of classes increasing from 4 to 20.
Figure 4: Accuracy improvements of winning algorithms in the object detection tracks of major challenges. The drop in PASCAL VOC 2007 accuracy is due to the number of classes increasing from 4 to 20.
Dataset Overview
- PASCAL VOC: The earliest large-scale challenge dataset, released in 2005. It laid the foundation for object recognition evaluation metrics. Although relatively small in scale, it is still used as a convenient benchmark for new algorithms.
- ImageNet: Launched in 2010, it contains tens of millions of images and tens of thousands of fine-grained classes. Its hierarchical structure is based on WordNet. The ILSVRC challenge (2010-2017) greatly accelerated the development of deep learning. ImageNet remains the standard dataset for pretraining complex models, but its single-object-per-image annotations and lack of rich context have also driven the creation of more complex datasets.
- Microsoft COCO: Created to address the shortcomings of ImageNet, it has fewer images but much richer annotations. It emphasizes objects in natural contexts and provides pixel-level instance segmentation masks. COCO also focuses on balancing instance counts across categories and released the supplementary COCO-Stuff dataset for background region segmentation.
- Open Images: The latest generation of large-scale datasets, containing over nine million images, bounding boxes for 600 object categories, and partial segmentation masks. Its distinctive features include visual relationship annotations (such as “person riding bicycle”) and negative labels (explicitly indicating objects absent from the image) to enhance a model’s classification ability.
Challenge Tasks
The four major challenges cover tasks ranging from simple to complex, and their evaluation criteria have evolved accordingly.
| Challenge | Task | Number of Classes | Images | Annotated Objects | Active Years | Task Description | Evaluation Metric | | :— | :— | :— | :— | :— | :— | :— | :— | | PASCAL VOC | Image classification | 20 | 11,540 | 27,450 | 2005 - 2012 | Predict whether at least one instance of each category exists in each image | AP | | | Detection | 20 | 11,540 | 27,450 | 2005 - 2012 | Predict bounding boxes for all instances of the challenge categories in the image | AP (IoU > 0.5) | | | Segmentation | 20 | 2,913 | 6,929 | 2007 - 2012 | Perform semantic segmentation of object categories | IoU | | ILSVRC | Image classification | 1000 | 1,331,167 | 1,331,167 | 2010 - 2014 | Classify one annotated category in each image | Top-5 prediction binary classification error rate | | | Object detection | 200 | 476,688 | 534,309 | 2013 - 2017 | Predict bounding boxes for all instances in each image | AP (IoU threshold proportional to box size) | | MS COCO | Detection | 80 | 123,000+ | 500,000+ | 2015 - present | Perform instance segmentation for object categories (things) | AP at IoU in [0.5:0.05:0.95] | | | Keypoints | 17 | 123,000+ | 250,000+ | 2017 - present | Perform object detection and keypoint localization simultaneously | OKS-based AP | | | Stuff | 91 | 123,000+ | - | 2017 - present | Perform pixel-level segmentation of background categories | mIoU | | | Panoptic | 171 | 123,000+ | 500,000+ | 2018 - present | Perform full image segmentation (stuff and things) | Panoptic Quality (PQ) | | Open Images | Object detection | 500 | 1,743,042 | 12,421,955 | 2018 - present | Hierarchy-based bounding box detection | mAP | | | Instance segmentation | 300 | 848,000 | 2,148,896 | 2018 - present | Perform instance segmentation for object categories; includes negative labels to improve training | mAP (IoU > 0.5) | | | Visual relationship detection | 57 | 1,743,042 | 380,000 relationship triplets | 2018 - present | Annotate images with relationship triplets | Weighted sum of mAP and recall | Table 2: Challenge descriptions for PASCAL VOC, ILSVRC, MS COCO, and Open Images
- Classification: Mainly appears in PASCAL VOC and ILSVRC, with the latter using Top-5 error rate as the standard.
- Detection: All four major challenges include this task, but the evaluation criteria have evolved from a fixed IoU threshold (PASCAL VOC, Open Images) to more complex dynamic thresholds (ILSVRC) and multi-threshold averaging (MS COCO).
- Segmentation: From semantic segmentation in PASCAL VOC to the more comprehensive instance segmentation, Stuff segmentation, and panoptic segmentation in MS COCO, the evaluation metric has also evolved from simple IoU to the more comprehensive PQ.
- Specific tasks: Each challenge also introduced application-specific tasks, such as human part layout in PASCAL VOC, human keypoint detection in MS COCO, and visual relationship detection in Open Images, driving development in more specialized areas.
Other Object Recognition Datasets
In addition to the four major mainstream datasets above, there are many other valuable datasets.
Object Detection Datasets
Although the trend is toward segmentation masks, bounding box annotations are still used in many datasets because they are cheaper and more consistent.
| Dataset | Number of Images | Number of Classes | Number of Bounding Boxes | Year | | :— | :— | :— | :— | :— | | Caltech 101 [75] | 9,144 | 102 | 9,144 | 2003 | | MIT CSAIL [234] | 2,500 | 21 | 2,500 | 2004 | | Caltech 256 [92] | 30,307 | 257 | 30,307 | 2006 | | Visual Genome [126] | 108,000 | 76,340 | 4,102,818 | 2016 | | YouTube BB [197] | 5.6 m | 23 | 5.6 m | 2017 | | Objects 365 [211] | 638,000 | 365 | 10.1 m | 2019 | Table 3: General object detection datasets (excluding those already introduced in Section 3.1)
Object Segmentation Datasets
These datasets provide instance-level or semantic-level segmentation masks. In recent years, Video Object Segmentation (Video Object Segmentation, VOS) has become a hot topic, and DAVIS and YouTube-VOS are the main benchmarks in this field.
| Dataset | # Images | # Classes | # Objects | Year | Challenge | Description | | :— | :— | :— | :— | :— | :— | :— | | SUN [256] | 130,519 | 3819 | 313,884 | 2010 | No | Mainly used for scene recognition, but also provides instance-level segmentation masks | | SBD [95] | 10,000 | 20 | 20,000 | 2011 | No | Object contours on PASCAL VOC training/validation images | | Pascal Part [46] | 11,540 | 191 | 27,450 | 2014 | No | Object part segmentation for 20 categories in the PASCAL VOC dataset | | DAVIS [30] | 150 (videos) | 4 | 449 | 2016 | Yes | A video object segmentation dataset and challenge focused on semi-supervised and unsupervised segmentation tasks | | YouTube-VOS [260] | 4,453 | 94 | 7,755 | 2018 | Yes | A video object segmentation dataset collected from short video clips (3-6 seconds) | | LVIS [94] | 164,000 | 1000 | 2 m | 2019 | Yes | Instance segmentation annotations for long-tail categories with few samples | | LabelMe[207] | 62,197 | 182 | 250,250 | 2005 | No | Instance-level segmentation; some background categories are also annotated | Table 4: Object segmentation datasets
Object Recognition in Scene Understanding Datasets
A comprehensive understanding of an image requires not only recognizing objects, but also understanding the scene. Pure object recognition may provide some contextual clues, but it can also be misleading. Background attributes (Stuff), such as grass and sky, are often ignored in traditional object recognition datasets, yet they are crucial for providing geometric relationships and contextual reasoning. Therefore, many scene-centric datasets have been proposed to enable deeper visual understanding.