Not All Parameters Are Created Equal: Smart Isolation Boosts Fine-Tuning Performance
-
ArXiv URL: http://arxiv.org/abs/2508.21741v1
-
Authors: Minlong Peng; Yao Wang; Di Liang
-
Publishing Institutions: ByteDance Inc.; Fudan University; University of New South Wales
TL;DR
This paper proposes a new framework called “Core Parameter Isolation Fine-Tuning” (CPI-FT). By identifying and isolating each task’s core parameter region, grouping tasks according to the degree of overlap between these regions, and combining parameter fusion with a dynamic freezing strategy for multi-stage fine-tuning, it effectively alleviates task conflicts and catastrophic forgetting in multi-task supervised fine-tuning.
Key Definitions
The paper introduces several core concepts to build its fine-tuning framework:
- Parameter Heterogeneity: The paper’s central assumption, namely that different capabilities of large language models (LLMs) depend on specific and potentially overlapping subsets of parameters. Different tasks rely on different parts of the model’s parameters, so uniformly updating all parameters is suboptimal.
- Core Parameter Region ($C_i$): Refers to the subset of parameters most critical to a specific task $T_i$. The paper identifies these regions by independently fine-tuning the model and measuring how much each parameter changes from its pre-trained state. The top $p\%$ of parameters with the largest changes are defined as that task’s core parameter region.
- Core Parameter Isolation Fine-Tuning (CPI-FT): The new fine-tuning framework proposed in this paper. It addresses the “seesaw effect” and catastrophic forgetting in multi-task learning through a series of staged operations: identifying core regions, task grouping, parameter fusion, and multi-stage re-fine-tuning.
- SLERP-based Parameter Fusion: A technique for merging parameters from different task models. For non-core parameter regions, the paper uses Spherical Linear Interpolation (SLERP) for smooth fusion to avoid abrupt parameter changes and conflicts, while preserving overall model consistency.
Related Work
At present, Supervised fine-tuning (SFT) is a key method for adapting large language models (LLMs) to downstream tasks. However, when dealing with scenarios that include multiple heterogeneous tasks (such as mathematical reasoning, coding, creative writing, etc.), SFT faces significant challenges.
The main bottleneck of existing methods is the “seesaw effect,” where progress on one task often comes at the expense of performance on others. Traditional joint multi-task fine-tuning or multi-stage fine-tuning methods typically update all model parameters indiscriminately, failing to account for differences in how tasks depend on parameters. This uniform update strategy exacerbates gradient conflicts and catastrophic forgetting between tasks, hindering improvements in model generalization.
The core problem this paper aims to solve is: how to systematically mitigate negative interference and catastrophic forgetting among tasks in multi-task supervised fine-tuning. The authors argue that the root cause is “parameter heterogeneity,” meaning that different tasks depend on different subsets of parameters in the model. Therefore, the goal of this paper is to propose a fine-tuning paradigm that can identify and protect these task-specific parameter regions, enabling more fine-grained control over the fine-tuning process.
Method
This paper proposes the Core Parameter Isolation Fine-Tuning (CPI-FT) framework, which aims to solve interference and forgetting in multi-task fine-tuning by systematically identifying, isolating, and protecting task-specific parameter regions. The framework consists of the following four core stages:
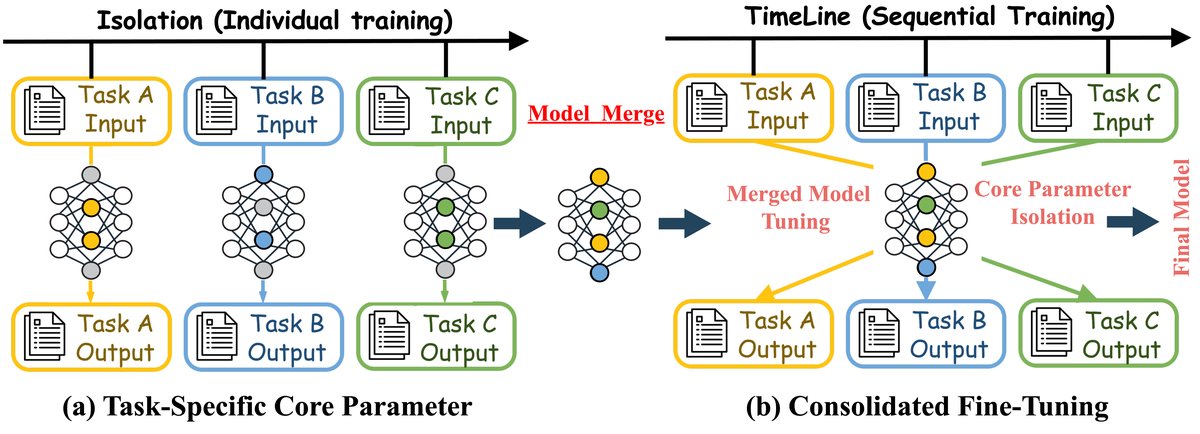 Figure 1: This figure illustrates (a) the task-specific core parameter isolation method and (b) the integrated fine-tuning method. In the isolation method, each task is trained separately and then the models are merged. In the timeline method, tasks are processed sequentially, then merged and fine-tuned, ultimately producing a unified model.
Figure 1: This figure illustrates (a) the task-specific core parameter isolation method and (b) the integrated fine-tuning method. In the isolation method, each task is trained separately and then the models are merged. In the timeline method, tasks are processed sequentially, then merged and fine-tuned, ultimately producing a unified model.
Stage 1: Identifying Task-Specific Core Parameter Regions
The goal of this stage is to identify each task’s dedicated “core parameter region.”
- Independent Fine-Tuning Probe: For each of the $N$ tasks $T_1, …, T_N$, starting from the same pre-trained model checkpoint $\theta^{(0)}$, perform a separate, short fine-tuning run using only that task’s data $\mathcal{D}_i$ to obtain task-specific model parameters $\theta^{(i)}$.
-
Compute Update Magnitude: Quantify the importance of each parameter $j$ by computing the absolute difference before and after fine-tuning:
\[\Delta \mid \theta^{(i)}_{j} \mid = \mid \theta^{(i)}_{j}-\theta^{(0)}_{j} \mid\]
The authors argue that the update magnitude directly reflects how far a parameter has deviated from its initial state to adapt to a specific task, and is more stable and computationally efficient than metrics such as gradient magnitude.
-
Define the Core Region: For each task $T_i$, its core parameter region $C_i$ is defined as the set of the top $p\%$ parameters with the largest update magnitudes.
\[C_{i}=\text{arg topk}_{j\in\{1..D\}}(\Delta \mid \theta^{(i)}_{j} \mid ,\lfloor p\cdot D/100\rfloor)\]
Here, $p$ is a hyperparameter that controls the size of the core region.
Stage 2: Task Grouping and Ordering Based on Core Region Similarity
To reduce direct conflicts between similar tasks, the paper groups tasks according to the degree of overlap between their core parameter regions.
-
Compute Similarity: Use the Jaccard Index to measure the similarity between the core regions $C_i$ and $C_j$ of any two tasks $T_i$ and $T_j$:
\[S(C_{i},C_{j})=\frac{ \mid C_{i}\cap C_{j} \mid }{ \mid C_{i}\cup C_{j} \mid }\] - Task Grouping: Based on a similarity threshold $\tau$, if $S(C_i, C_j) \geq \tau$, then tasks $T_i$ and $T_j$ are considered related. Finally, by computing the connected components in the task similarity graph, all tasks are partitioned into different groups $G_1, …, G_K$.
- Determine Stage Order: Arrange the task groups into a sequence $(G_1, G_2, …, G_K)$ for subsequent multi-stage fine-tuning. The paper mainly evaluates random ordering.
Stage 3: Cross-Task Parameter Fusion
This innovative stage aims to integrate knowledge learned from each task into a unified model.
- Select the Base Model: Use the model parameters $\theta_{\text{base}}$ obtained from the final fine-tuning stage as the starting point for fusion.
-
Core Parameter Overwrite: For each task $T_i$, directly “transfer” the values of its core parameters $\theta^{(i)}$ identified during independent fine-tuning into the corresponding positions in the base model $\theta_{\text{base}}$. This ensures that each task’s key capabilities are preserved without loss.
\[\theta_{\text{fused},j}=\begin{cases}\theta^{(i)}_{j}&j\in C_{i}\\ \theta_{\text{base},j}&j\notin C_{i}\end{cases}\] -
Non-Core Parameter Fusion: For parameters that do not belong to any core region, to avoid conflicts and ensure a smooth transition, Spherical Linear Interpolation (SLERP) is used for fusion. This method can smoothly blend knowledge from different tasks in a geometry-aware manner.
\[\theta_{\text{fused},j}=\begin{cases}\omega\theta^{(i)}_{j}+(1-\omega)\theta_{\text{base},j},&\angle(\theta_{\text{base},j},\theta^{(i)}_{j})<\epsilon\\ \text{SLERP}(\theta_{\text{base},j},\theta^{(i)}_{j},\omega),&\text{otherwise}\end{cases}\]
Here, $\omega$ is the interpolation factor, and $\epsilon$ is the threshold for determining whether vectors are collinear.
Stage 4: Integrated Fine-Tuning via Multi-Stage Training
Finally, the fused model undergoes a brief multi-stage fine-tuning process to consolidate its generalization ability.
-
Dynamic Freezing Mechanism: During fine-tuning, all core parameter regions identified in previous stages are frozen. Specifically, when training the $k$-th task group $G_k$, all core parameters from the first $k-1$ task groups become non-updatable. This is implemented through a binary mask $M_k$.
\[\Delta\theta_{t+1}=\theta_{t}+\Delta\theta_{t}\odot M_{k}\] - Sampled Data Calibration: This stage does not use the full dataset; instead, a small portion of data is sampled from each task to form a balanced mixed training set, improving efficiency and preventing overfitting.
- Multi-Stage Training Procedure: Following the order determined in Stage 2, fine-tuning is performed sequentially on the sampled data of each task group $G_k$, while applying the dynamic freezing mechanism. The final model $\theta_{\text{final}}$ integrates knowledge from all tasks while effectively avoiding mutual interference.
Experimental Conclusions
Through extensive experiments on multiple benchmarks and models, the paper validates the effectiveness of the CPI-FT framework.
Main Performance Comparison
The experimental results show that CPI-FT significantly outperforms the standard joint multi-task fine-tuning (Full SFT) and multi-stage fine-tuning baselines across all tested base models (LLaMA-2-7B, Mistral-8B, Qwen1.5-7B, Gemma-9B) and tasks (GSM8K, CodeAlpaca, LogiQA, Alpaca, UltraChat). This demonstrates the broad effectiveness of CPI-FT in mitigating task conflicts.
| Base Model | Method | GSM8K | CodeAlpaca | LogiQA | Alpaca | UltraChat | Average Normalized Score |
|---|---|---|---|---|---|---|---|
| LLaMA-2-7B | Full SFT (Multi-task) | 48.2 | 25.1 | 55.3 | 7.1 | 7.5 | 6.58 |
| Multi-Stage (Random, K=3) | 49.5 | 24.8 | 56.0 | 7.3 | 7.6 | 6.70 | |
| Multi-Stage (Heuristic) | 50.1 | 25.5 | 56.8 | 7.0 | 7.4 | 6.75 | |
| CPI-FT (this method, p=1%, $\tau$=0.1) | 53.5 | 27.2 | 59.1 | 7.6 | 7.8 | 7.21 | |
| Mistral-8B | Full SFT (Multi-task) | 46.5 | 24.0 | 53.8 | 6.9 | 7.3 | 6.37 |
| Multi-Stage (Random, K=3) | 47.8 | 23.7 | 54.5 | 7.1 | 7.4 | 6.49 | |
| Multi-Stage (Heuristic) | 48.3 | 24.3 | 55.2 | 6.8 | 7.2 | 6.53 | |
| CPI-FT (this method, p=1%, $\tau$=0.1) | 51.6 | 25.9 | 57.4 | 7.5 | 7.7 | 6.98 | |
| Qwen1.5-7B | Full SFT (Multi-task) | 49.8 | 26.0 | 56.5 | 7.3 | 7.7 | 6.79 |
| Multi-Stage (Random, K=3) | 51.0 | 25.7 | 57.3 | 7.5 | 7.8 | 6.92 | |
| Multi-Stage (Heuristic) | 51.7 | 26.4 | 58.0 | 7.2 | 7.6 | 6.98 | |
| CPI-FT (this method, p=1%, $\tau$=0.1) | 55.3 | 28.1 | 60.6 | 7.8 | 8.1 | 7.45 | |
| Gemma-9B | Full SFT (Multi-task) | 51.5 | 27.2 | 58.0 | 7.6 | 8.0 | 7.05 |
| Multi-Stage (Random, K=3) | 52.8 | 26.9 | 58.9 | 7.8 | 8.1 | 7.19 | |
| Multi-Stage (Heuristic) | 53.5 | 27.6 | 59.7 | 7.5 | 7.9 | 7.26 | |
| CPI-FT (this method, p=1%, $\tau$=0.1) | 57.2 | 29.4 | 62.5 | 8.1 | 8.4 | 7.73 |
Table 1: Main performance comparison of different methods across SFT tasks.
Catastrophic Forgetting Analysis
In the sequential fine-tuning setting (training task A first, then task B), CPI-FT (referred to as DPI in the table) demonstrates excellent anti-forgetting capability. Compared with the 24.5-point performance drop of Full SFT, CPI-FT drops by only 5.7 points, reducing forgetting by more than 65% while still learning the new task well.
| Method | A$\rightarrow$B | B$\rightarrow$A | ||
|---|---|---|---|---|
| $\Delta$A ($\downarrow$) | $\Delta$B ($\uparrow$) | $\Delta$B ($\downarrow$) | $\Delta$A ($\uparrow$) | |
| Full SFT | -24.5 | +13.4 | -16.7 | +20.2 |
| Multi-Stage SFT | -16.2 | +12.6 | -12.3 | +17.5 |
| CPI-FT (this method) | -5.7 | +12.2 | -4.8 | +18.8 |
Table 2: Catastrophic forgetting analysis of sequential fine-tuning on LLaMA-2-7B.
Other Analyses and Conclusions
- Multi-stage vs. single-stage: The experiments show that the proposed multi-stage integrated fine-tuning (Stage 4) performs better than simple single-stage mixed training, especially on tasks that are prone to interference, validating the necessity of its design.
- Robustness to resource imbalance: In scenarios where some tasks have far less data than others, CPI-FT (referred to as DPI in the table) still performs strongly, effectively protecting low-resource task performance without harming high-resource tasks, demonstrating its robustness in real-world applications.
- Impact of similarity threshold $\tau$: Experiments found that grouping tasks based on core parameter overlap ($\tau>0$) consistently outperforms no grouping ($\tau=0$). Performance peaks around $\tau=0.1$, indicating that moderate task isolation is the best strategy.
Final Conclusion: The proposed CPI-FT framework successfully mitigates the “seesaw effect” and catastrophic forgetting in multi-task SFT by identifying and isolating the core parameter regions of tasks. It provides a scalable and effective approach for robust model fine-tuning in heterogeneous task settings.