MUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
Don’t just look at the last sentence! DeepMind’s new MUSIC: synthetic data tackles the challenge of multi-turn dialogue evaluation

Large language models (LLMs) can now write beautiful poems or code snippets, but have you noticed that once you chat with them for a few more turns, their logic starts to “fall apart”?
ArXiv URL:http://arxiv.org/abs/2512.24693v1
The core pain point behind this is: it is very hard to teach a model what “good multi-turn dialogue” is. Most existing evaluation data only focuses on the “last sentence” of a conversation, like judging a movie by its final five minutes and completely ignoring whether the plot in between is coherent.
To solve this problem, a research team from Google DeepMind and Princeton University jointly introduced a new technique called MUSIC (MUlti-Step Instruction Contrast). This technique does not require expensive human annotation; instead, it can synthesize data in an unsupervised way to train a sharp-eyed multi-turn Reward Model (Reward Model), enabling the model to learn how to assess dialogue quality from the whole picture.
Why are today’s reward models so short-sighted?
In the RLHF (Reinforcement Learning from Human Feedback) pipeline, the reward model (RM) plays the role of the judge. However, the dataset used to train this judge (such as Skywork, UltraFeedback, etc.) has a major flaw: preference pairs usually differ only in the final turn.
Typical data looks like this:
-
Good answer: [User: Hello] -> [AI: Hello] -> [User: Write a poem] -> [AI: wrote a good poem]
-
Bad answer: [User: Hello] -> [AI: Hello] -> [User: Write a poem] -> [AI: wrote a bad poem]
The first few turns are exactly the same, and only the last one differs. As a result, the trained RM becomes “lazy,” focusing only on the last sentence and ignoring the crucial coherence and consistency in multi-turn dialogue.
MUSIC: adding some “ingredients” to the conversation
To help the RM learn to see the full picture, the research team proposed MUSIC. This is an unsupervised data augmentation strategy whose core idea is: create quality differences that persist across multiple turns of a conversation.
MUSIC’s workflow is quite clever. It uses an LLM to simulate the user and assistant, generating two sets of dialogue trajectories:
-
Seed Context: randomly take a segment of an existing dataset as the starting point.
-
Simulation: let the LLM play the roles of user and assistant and continue the conversation.
-
Creating the Contrast:
-
Chosen: the assistant follows the instruction normally and generates a high-quality response.
-
Rejected: this is the essence of MUSIC. At some intermediate step, the system quietly modifies the user’s instruction (Instruction Contrast),inducing the assistant to answer a “related but wrong” question.
For example, if the user originally asks “How do I make braised pork belly?”, in the Rejected branch the system secretly changes the instruction to “How do I make twice-cooked pork?”, and although the assistant writes a perfect twice-cooked pork recipe, for the user’s original “braised pork belly” request, this is a serious instruction-following error. This error is preserved as the conversation continues, thereby creating a quality difference that runs through multiple turns.
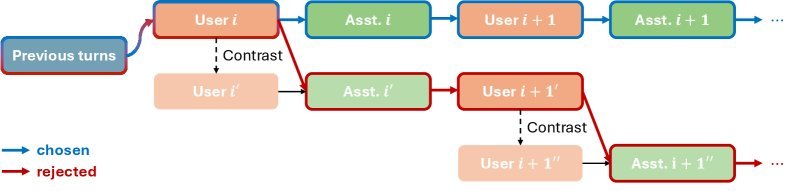
Figure 1: Overview of the MUSIC data augmentation pipeline. By introducing a Contrastive Instruction Prompt, quality degradation is induced in the Rejected branch, thereby generating preference pairs with multi-turn differences.
Core methodology
From a mathematical perspective, MUSIC aims to optimize the objective function of the Bradley-Terry (BT) model. Suppose we have a multi-turn dialogue preference dataset ${\mathcal{D}}$ containing the chosen dialogue $C_{\text{chosen}}$ and the rejected dialogue $C_{\text{rejected}}$; the training objective is to minimize the negative log-likelihood loss:
\[{\mathcal{L}}(\theta,{\mathcal{D}})=\mathbb{E}_{C_{\text{chosen}},C_{\text{rejected}}\sim{\mathcal{D}}}\log\sigma\left(R_{\theta}(C_{\text{chosen}})-R_{\theta}(C_{\text{rejected}})\right)\]MUSIC’s contribution is to construct a more challenging ${\mathcal{D}}_{\text{MUSIC}}$ and mix it with the original data to form the augmented dataset ${\mathcal{D}}_{\text{aug}}={\mathcal{D}}\cup{\mathcal{D}}_{\text{MUSIC}}$.
When generating Rejected samples, the researchers used a special Prompt that asks the assistant to produce a response that is “a good answer to the modified instruction, but a bad answer to the original user question.” This fine-grained control ensures that the model must understand the context to judge quality, rather than cheating by relying only on response fluency.
Experimental results: multi-turn ability jumps significantly, and single-turn performance does not drop
The research team conducted experiments based on the Gemma-2-9B-Instruct model using the Skywork dataset. They compared a Baseline RM trained only on the original data with an RM enhanced by MUSIC.
1. Multi-turn dialogue evaluation ability improves significantly
In the Best-of-N (BoN) inference task, the MUSIC-enhanced RM was able to select higher-quality dialogues. Evaluated by Gemini 1.5 Pro, the dialogues guided by MUSIC outperformed the Baseline on both the Anthropic HH and UltraInteract datasets.
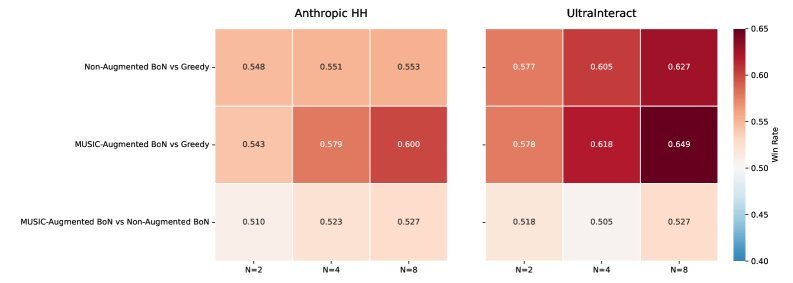
Figure 2: Win-rate comparison between the MUSIC-enhanced RM and the Baseline RM under the Best-of-N ($N\in{2,4,8}$) setting. As $N$ increases, MUSIC’s ability to leverage the candidate pool becomes stronger.
2. A pleasant surprise: improved reasoning ability
A common question is: if a model is optimized for multi-turn dialogue, will it degrade on traditional single-turn tasks?
The experimental results were encouraging. In the standard RewardBench test, the MUSIC-enhanced RM not only did not regress, but actually achieved a 3.9% improvement in the Reasoning category.
| Model | Chat | Chat Hard | Safety | Reasoning | Average |
|---|---|---|---|---|---|
| Skywork (Baseline) | 96.9 | 73.0 | 90.9 | 83.1 | 86.0 |
| Skywork + MUSIC | 96.4 | 72.4 | 90.8 | 87.0 | 86.6 |
This suggests that exposure to logically coherent multi-turn dialogue data may implicitly enhance the model’s ability to handle complex reasoning steps.
Conclusion and outlook
The emergence of MUSIC reveals an important lesson: during the Alignment stage, the “structure” of data matters more than its “quantity.”
By synthesizing contrastive data with multi-turn differences, DeepMind successfully taught the reward model to “keep the big picture in mind.” This human-annotation-free approach is highly scalable. In the future, as dialogue systems evolve toward longer and more complex Agent tasks, evaluation methods like MUSIC that focus on long-horizon dependency will become a key piece in building more intelligent AI.