MobileLLM-Pro Technical Report
Meta MobileLLM-Pro: A 1B-Parameter Mobile Model Takes the Crown, with Four Major Innovations Surpassing Gemma and Llama 3.2
While powerful AI models are still orchestrating everything from cloud servers, a transformation is quietly taking place on the devices in our hands. Yet making AI run smoothly on phones has always faced a tricky challenge: large models are too bulky, while small models are not smart enough.
Paper Title: MobileLLM-Pro Technical Report ArXiv URL: http://arxiv.org/abs/2511.06719v1
Meta Reality Labs’ latest research result, MobileLLM-Pro, is designed to break this deadlock. It is a lightweight language model with only 1 billion parameters, yet it significantly outperforms Google’s Gemma 3-1B and Meta’s own Llama 3.2-1B across 11 standard benchmark tests.
Even more impressive, it supports a context window of up to 128K, and after 4-bit quantization, its performance barely degrades. How was this achieved? The answer lies in the four core innovations of MobileLLM-Pro.
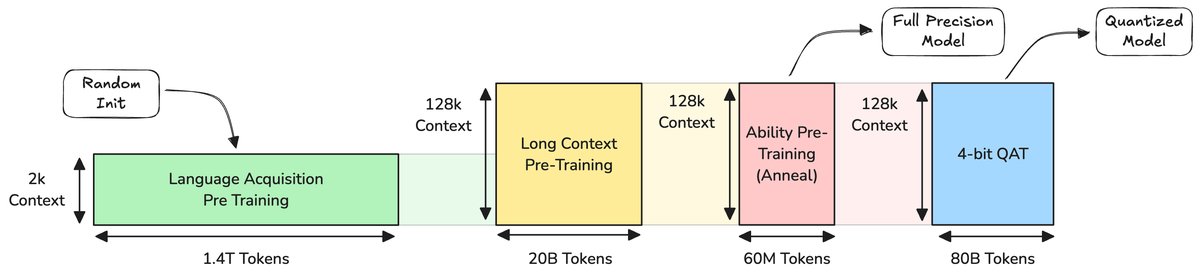
Core Architecture: Small Size, Big Capacity
MobileLLM-Pro’s “skeleton” is based on the mature Transformer architecture and draws on the design essence of the Llama family. Although it has only 1 billion parameters, it uses the same 202,048-token vocabulary as frontier models such as Llama 4, saving about 260 million parameters through embedding sharing.
To efficiently handle 128K-long text on edge devices, the study adopts a Local-Global Attention mechanism. Most layers use local attention with a sliding window of 512 token, while global attention is used only in a few key layers (every 3 layers), striking an excellent balance between computational efficiency and long-context capability.
Innovation 1: Implicit Positional Distillation, Learning Long Text the Smart Way
Traditional models usually need to be “fed”a large amount of long-sequence data to learn how to handle long text. But this is not only computationally expensive, it can also cause the model to forget existing knowledge while learning new positional information.
MobileLLM-Pro proposes a new technique called implicit positional distillation.
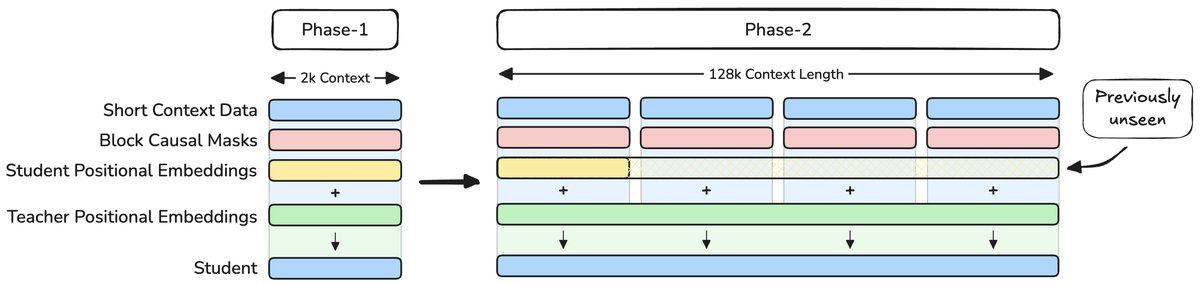
Its core idea is to let a powerful teacher model that has seen 128K-long text (Llama 4-Scout) distill long-range dependencies and positional understanding, and then pass them on to the student model (MobileLLM-Pro). Throughout the process, the student model never needs to see the full long-text data.
This is like an experienced mentor who does not need a student to read a massive tome from start to finish; by explaining the connections between key chapters, the student can grasp the structure of the entire book. This method cleverly expands the model’s context capability while avoiding the distribution shift problem that arises when training moves from short text to long text.
Innovation 2: Specialist Model Merging, Stronger Without Adding Parameters
To make small models more “well-rounded,” researchers usually mix code, reasoning, knowledge, and other domain content in the training data. But this can cause different capabilities to “compete” and interfere with one another during training.
MobileLLM-Pro adopts a Specialist Model Merging strategy. In the final stage of pretraining, they train multiple “domain experts” in parallel based on the same model checkpoint, such as a coding expert and a reasoning expert.
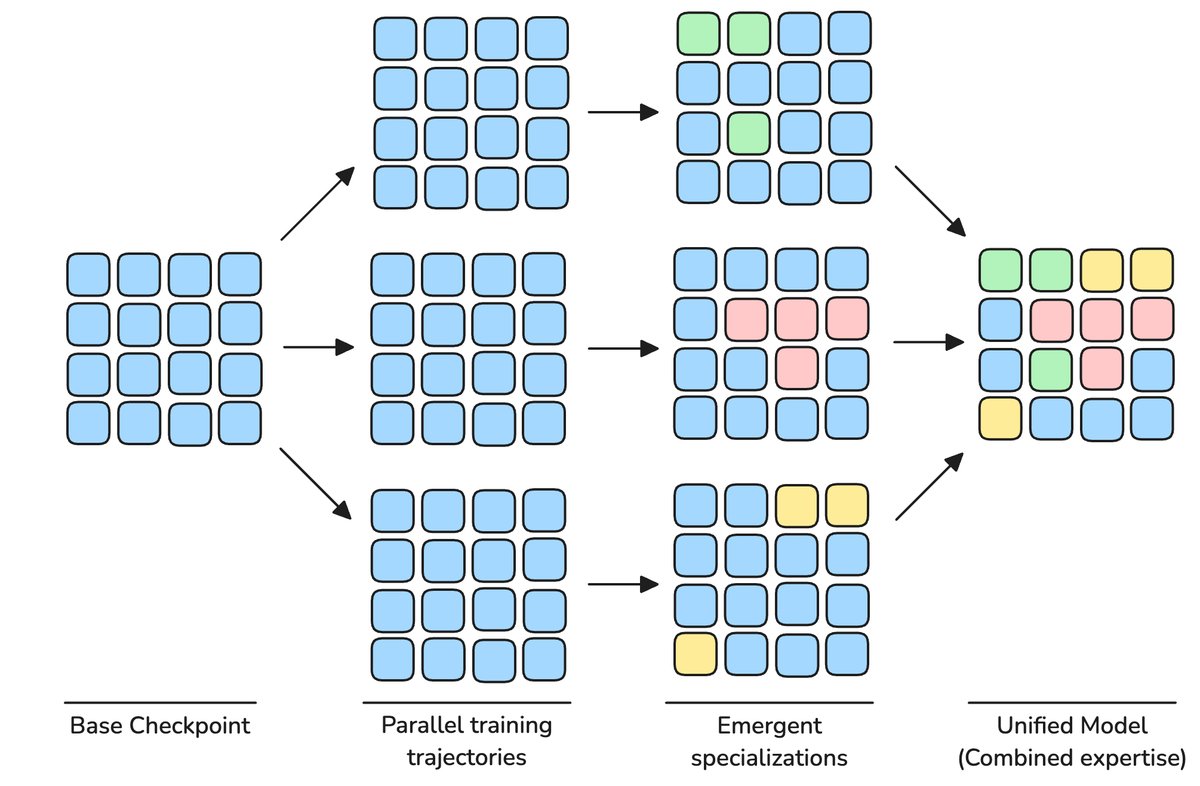
Finally, using non-uniform weight averaging, they merge the “wisdom” (model weights) of these experts into a single model. This approach adds no parameters, yet creates an “all-rounder” that outperforms any single expert across capabilities.
Innovation 3: Simulation-Driven Data Mixing
Small models are extremely sensitive to the quality and mix of training data. A slight mistake in the proportions of different domain data, such as code, math, and general knowledge, can lead to performance drops.
This study adopts the Scalable Data Mixer (SDM) framework. Through a single simulated training run, it automatically estimates the contribution of different data domains to model performance, thereby finding an optimal data-mixing scheme for formal training. This ensures that at every stage of training, the model gets the most scientific and nutritious “data meal.”
Ablation experiments show that, compared with uniformly mixed data, this method improves pretraining performance by more than 10% in absolute terms.
Innovation 4: Quantization-Aware Training, No Drop in 4-bit Deployment
To deploy a model on a phone, quantization is unavoidable: compressing model weights from 32-bit floating-point numbers to 4-bit integers (INT4). However, directly applying Post-Training Quantization (PTQ) to a trained model causes MobileLLM-Pro’s performance to drop sharply.
To address this, the research team adopted Quantization-Aware Training (QAT). During training, quantization operations are introduced into the computation graph, allowing the model to “anticipate” that it will be quantized in the future and learn to maintain high performance under this constraint.
In addition, they combined this with self-distillation, using the full-precision model as the teacher to guide the quantized model’s learning, preserving the model’s reasoning and long-context capabilities to the greatest extent. In the end, the 4-bit quantized model saw only a slight performance drop of about 1%, which is almost negligible in practical applications.
Performance: Comprehensive Outperformance of Peer Models
Whether in pretraining or instruction fine-tuning, MobileLLM-Pro’s performance is truly impressive.
During pretraining, it outperformed Gemma 3-1B and Llama 3.2-1B in the average scores across 11 benchmarks including MMLU and GSM8K.
After instruction fine-tuning, it also led the competition on multiple “assistant-style” tasks such as code generation (MBPP, HumanEval), function calling (BFCLv2), and text rewriting (OpenRewrite), demonstrating huge potential as an on-device AI assistant.
Conclusion
MobileLLM-Pro is not simply a downsized version of an existing model; rather, through a series of carefully designed innovations, it systematically addresses the core challenges faced by edge models: how to achieve strong general capabilities, long-context understanding, and efficient deployment under limited resources.
By open-sourcing the model weights, Meta not only provides the industry with a powerful edge model that can be used directly, but more importantly, it offers a valuable “Pro”-level blueprint for how to build more efficient and smarter on-device AI systems in the future.