Mixture of Contexts for Long Video Generation
-
ArXiv URL: http://arxiv.org/abs/2508.21058v1
-
Authors: Junfei Xiao; Alan Yuille; Maneesh Agrawala; Zhenheng Yang; Yinghao Xu; Lu Jiang; Yuwei Guo; Gordon Wetzstein; Ziyan Yang; Lvmin Zhang; and 3 others
-
Publishing Institutions: ByteDance; Johns Hopkins University; Stanford University; The Chinese University of Hong Kong
TL;DR
This paper proposes a learnable sparse attention routing module called Mixture of Contexts (MoC), which reformulates long-video generation as an internal information retrieval task, thereby achieving long-term memory and consistency for minute-level videos while greatly reducing computational cost.
Key Definitions
The paper introduces or uses the following core concepts that are crucial for understanding it:
- Mixture of Contexts (MoC): The core module proposed in this paper. It is an adaptive sparse attention routing mechanism that replaces the dense self-attention in traditional Transformers. For each query, MoC dynamically selects a small number of the most relevant context “chunks” from a set of context blocks for attention computation, thereby changing the computational cost from quadratic in the total sequence length to near-linear in the number of selected blocks.
- Content-aligned Chunking: An intelligent sequence segmentation strategy. Unlike splitting a token sequence into fixed-length chunks, this method segments along the natural boundaries of video content, such as frames, shots, and text segments. This makes each chunk more semantically homogeneous, improving the accuracy and effectiveness of routing selection.
- Mandatory Anchors: Fixed attention connections that are enforced in addition to dynamic routing to ensure basic generation quality and stability. The paper sets two types of anchors: 1) cross-modal links, meaning all visual tokens must attend to all text tokens to ensure the generated content stays closely aligned with the text prompt; 2) intra-shot links, meaning each token must attend to all other tokens within its shot to maintain local coherence.
- Causal Routing: A constraint applied during the routing selection stage that forbids any token chunk from attending to chunks that are later in the temporal sequence or the same as itself. This ensures one-way information flow (from past to future), structuring the attention graph as a directed acyclic graph (DAG) and fundamentally preventing the “feedback loop” problem that can cause generated content to stall or repeat.
Related Work
At present, Transformer-based diffusion models have made significant progress in video generation, but when scaling to long videos of minutes or even hours, they face two core bottlenecks:
- Computational cost: Standard self-attention has a computational complexity of $O(L^2)$, where $L$ is the sequence length. For long videos, where the number of tokens can reach hundreds of thousands, this quadratic cost becomes infeasible in both computation and memory.
- Long-term memory: The model must maintain content consistency over extremely long time spans, such as character identity and scene layout, while avoiding content drift, collapse, or information loss.
Existing methods try to address these issues in two main ways: one is to compress historical information into compact representations, such as keyframes or latent states, but this leads to loss of detail; the other is to reduce computation through fixed sparse attention patterns, but such static patterns cannot adaptively focus on truly important historical events. The core problem this paper aims to solve is: how to break through the quadratic computational bottleneck of self-attention without sacrificing generation quality and long-term coherence, and achieve efficient, high-quality long-video generation.
Method
This paper proposes an adaptive sparse attention layer called Mixture of Contexts (MoC) to replace the dense self-attention module in the traditional diffusion Transformer (DiT), thereby reformulating long-video generation as an efficient internal information retrieval problem.
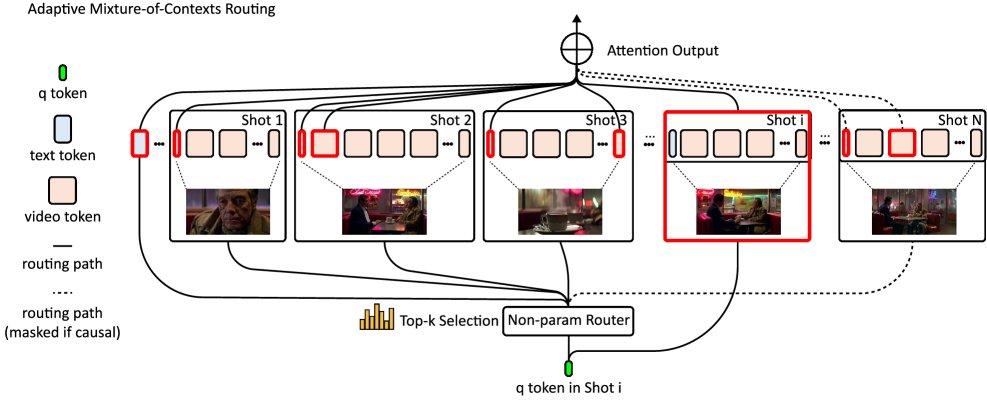 Figure 1: Overview of the adaptive Mixture of Contexts (MoC) proposed in this paper. Given a long multimodal token stream, it is first split into content-aligned chunks according to natural boundaries (frames, shots, text segments). Then, the keys of each chunk are mean-pooled to obtain a representative vector. For each query token $q$, its dot product with each pooled key is computed, and the top-k most relevant chunks are selected, together with mandatory links (global text and intra-shot connections). Finally, only the selected chunks are sent to Flash-Attention for computation, while all other tokens are skipped, enabling computation and memory to scale near-linearly with the number of selected chunks rather than quadratically with the total sequence length.
Figure 1: Overview of the adaptive Mixture of Contexts (MoC) proposed in this paper. Given a long multimodal token stream, it is first split into content-aligned chunks according to natural boundaries (frames, shots, text segments). Then, the keys of each chunk are mean-pooled to obtain a representative vector. For each query token $q$, its dot product with each pooled key is computed, and the top-k most relevant chunks are selected, together with mandatory links (global text and intra-shot connections). Finally, only the selected chunks are sent to Flash-Attention for computation, while all other tokens are skipped, enabling computation and memory to scale near-linearly with the number of selected chunks rather than quadratically with the total sequence length.
Innovation: Dynamic Routing and Top-k Selection
Unlike previous methods that rely on fixed sparse patterns or compressed history, the core of MoC is a dynamic routing mechanism. The basic idea is that for each query token $q_i$ in the sequence, instead of computing against all keys in the sequence, it interacts only with a small number of the most relevant context blocks.
The standard attention formula is:
\[\mathrm{Attn}\!\left({\mathbf{Q},\mathbf{K},\mathbf{V}}\right)=\mathrm{Softmax}\!\left(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d}}\right)\cdot{\mathbf{V}},\]MoC modifies it to:
\[\mathrm{Attn}\!\left({\mathbf{q}_{i},\mathbf{K},\mathbf{V}}\right)=\mathrm{Softmax}\!\left(\frac{\mathbf{q}_{i}\mathbf{K}_{\Omega(\mathbf{q}_{i})}^{\top}}{\sqrt{d}}\right)\cdot{\mathbf{V}_{\Omega(\mathbf{q}_{i})}},\]where $\Omega(\mathbf{q}_i)$ is the set of context indices dynamically selected for query $q_i$. This set is determined through the following top-k selection process:
- Chunking and pooling: First, the entire token sequence (including text and video tokens) is split into multiple chunks according to content (frames, shots). All keys $\mathbf{K}_\omega$ within each chunk are mean-pooled to obtain a single descriptor vector $\phi(\mathbf{K}_\omega)$ that represents the semantics of that chunk.
- Similarity computation and selection: For each query $q_i$, its dot-product similarity with all chunk descriptors is computed, and the top $k$ highest-scoring chunks are selected.
In this way, attention computation is restricted to a very small but highly relevant subset. Although the top-k selection itself is non-differentiable, the overall framework is end-to-end trainable. Through backpropagation, the model adjusts the projection matrices for queries and keys, learning to produce more discriminative representations to optimize routing decisions. To improve robustness, the training process also introduces two regularization techniques, Context Drop-off and Context Drop-in, to simulate imperfect routing decisions.
Innovation: Structure-aware Routing Strategy
The efficiency of MoC comes not only from sparsification, but also from its structure-aware design.
-
Content-aligned chunking: Unlike simple fixed-length chunking, the chunking strategy in this paper follows the natural structure of video (frames, shots, modalities). This ensures that each chunk is semantically and temporally coherent internally, making the mean-pooled descriptor more representative and the routing decisions more accurate.
- Fixed connections (mandatory anchors): To ensure basic generation quality, MoC enforces two types of connections:
- Cross-modal connections: Every visual token must attend to all text tokens. This ensures that the video content always remains consistent with the text prompt and prevents “instruction drift.”
- Intra-shot connections: Every token must attend to all other tokens within its shot. This preserves local spatiotemporal coherence, allowing dynamic routing to focus on establishing truly long-range dependencies.
- Causal routing: To prevent the model from falling into a “feedback loop” (for example, shot A attends to shot B, while shot B also attends to shot A), MoC applies a causal mask before routing selection. This mask forbids any chunk from attending to chunks that come after it in time or are the same as itself, ensuring that information always flows forward and forming a directed acyclic graph (DAG), thereby improving stability in long-sequence generation.
 Figure 2: The cyclic closure problem caused by the lack of causal constraints. Left: consecutive frames generated by an ablation model without a causal mask. The story should have switched from the café scene (top row) to a shot of the same woman looking at her phone by the riverbank (bottom row). However, because shot 9 strongly routes to shot 11, and shot 11 simultaneously routes back to shot 9, the model falls into a two-node feedback loop, limiting communication between shots 9 and 11 and the earlier shots, as shown in the routing count map on the right.
Figure 2: The cyclic closure problem caused by the lack of causal constraints. Left: consecutive frames generated by an ablation model without a causal mask. The story should have switched from the café scene (top row) to a shot of the same woman looking at her phone by the riverbank (bottom row). However, because shot 9 strongly routes to shot 11, and shot 11 simultaneously routes back to shot 9, the model falls into a two-node feedback loop, limiting communication between shots 9 and 11 and the earlier shots, as shown in the routing count map on the right.
Advantage: High computational efficiency
MoC significantly reduces computation by replacing quadratic dense attention with near-linear sparse attention. Its theoretical FLOPs cost is approximately:
\[\text{FLOPs}_{\mathrm{MoC}}\;\approx\;Ld+2LCd+4Lk\bar{m}d.\]Compared with the FLOPs of dense attention ($4L^2d$), the speedup is approximately:
\[\frac{\text{FLOPs}_{\text{dense}}}{\text{FLOPs}_{\text{MoC}}}\;\approx\;\frac{2L}{Cd+2k\bar{m}},\]where $L$ is the sequence length, $C$ is the number of blocks, $k$ is the number of selected blocks, $\bar{m}$ is the average block length, and $d$ is the head dimension. This ratio grows linearly with sequence length $L$. For example, for a 1-minute 480p video (about 180k tokens), MoC can reduce attention computation FLOPs by more than 7x. At the same time, by cleverly integrating with the Flash-Attention kernel, the method efficiently handles variable-length blocks and improves end-to-end generation speed by 2.2x.
Experimental conclusions
This paper validates MoC on single-shot and multi-shot (scene-level) text-to-video generation tasks, and compares it with baseline models that use dense attention.
Quantitative results
The experiments were evaluated using the VBench benchmark, supplemented by computational efficiency metrics.
Single-shot video (short sequence, about 6.3k tokens): As shown in Table 1, although MoC achieves sparsity as high as 83%, its performance on all VBench quality metrics is comparable to or even better than the dense-attention baseline. This demonstrates that concentrating computational resources on key information is effective. However, for short sequences, the extra overhead from routing and indexing operations outweighs the computational savings, resulting in slightly slower end-to-end speed.
| Method | Subject Consistency $\uparrow$ | Background Consistency $\uparrow$ | Motion Smoothness $\uparrow$ | Dynamic Degree $\uparrow$ | Aesthetic Quality $\uparrow$ | Image Quality $\uparrow$ | Sparsity $\uparrow$ | FLOPs $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| Baseline model | 0.9380 | 0.9623 | 0.9816 | 0.6875 | 0.5200 | 0.6345 | 0% | $1.9\times 10^{10}$ |
| Proposed method | 0.9398 | 0.9670 | 0.9851 | 0.7500 | 0.5547 | 0.6396 | 83% | $\mathbf{4.1\times 10^{9}}$ |
Table 1: Quantitative comparison for single-shot video generation.
Multi-shot video (long sequence, about 180k tokens): In long-sequence scenarios, the advantages of MoC become extremely pronounced. As shown in Table 2, at 85% sparsity, MoC reduces FLOPs by more than 7x and delivers a 2.2x real inference speedup. More importantly, it significantly improves model performance, especially in motion diversity (dynamic degree rising from 0.46 to 0.56), while maintaining a high level of motion smoothness and consistency.
| Method | Subject Consistency $\uparrow$ | Background Consistency $\uparrow$ | Motion Smoothness $\uparrow$ | Dynamic Degree $\uparrow$ | Aesthetic Quality $\uparrow$ | Image Quality $\uparrow$ | Sparsity $\uparrow$ | FLOPs $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| LCT [14] | 0.9378 | 0.9526 | 0.9859 | 0.4583 | 0.5436 | 0.5140 | 0% | $1.7\times 10^{13}$ |
| Proposed method | 0.9421 | 0.9535 | 0.9920 | 0.5625 | 0.5454 | 0.5003 | $\mathbf{85\%}$ | $\mathbf{2.3\times 10^{12}}$ |
Table 2: Quantitative comparison for multi-shot video generation.
Qualitative results and efficiency benchmarks
The qualitative results (shown below) indicate that, for both single-shot and multi-shot tasks, videos generated by MoC are visually on par with, or even better than, dense-attention models, despite reducing computation by more than three quarters.
 Figure 3: Qualitative comparison for single-shot video generation. Despite aggressive sparsification, the proposed method’s results are comparable to, or even better than, the baseline model.
Figure 3: Qualitative comparison for single-shot video generation. Despite aggressive sparsification, the proposed method’s results are comparable to, or even better than, the baseline model.
 Figure 4: Qualitative comparison for multi-shot video generation. Despite pruning more than three quarters of the attention computation, the proposed method’s results are visually almost indistinguishable from LCT [14].
Figure 4: Qualitative comparison for multi-shot video generation. Despite pruning more than three quarters of the attention computation, the proposed method’s results are visually almost indistinguishable from LCT [14].
The efficiency benchmark (shown below) further confirms that MoC’s computational latency grows nearly linearly with sequence length (i.e., the number of shots), whereas dense attention grows quadratically, demonstrating its great potential for handling longer videos.
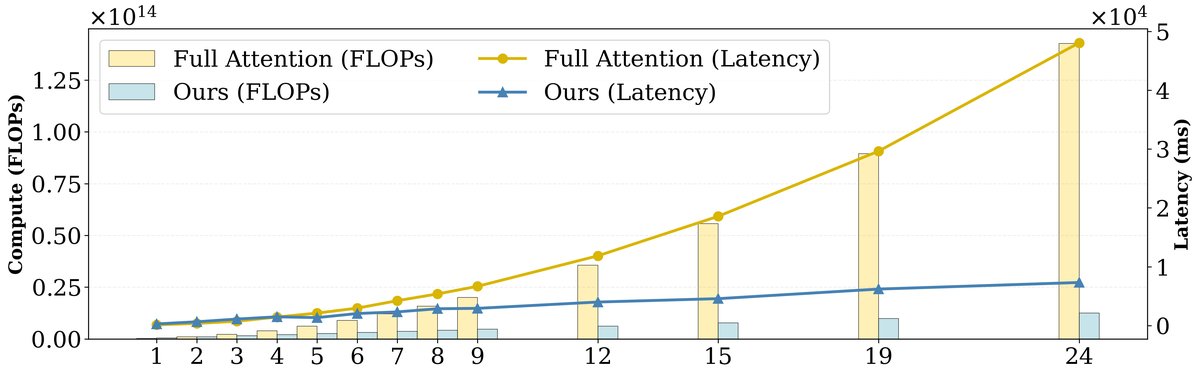 Figure 5: Performance benchmark comparing the MoC implementation aligned with this paper and full attention (using Flash Attention 2). The latency of the proposed method grows nearly linearly with the number of shots (i.e., sequence length L).
Figure 5: Performance benchmark comparing the MoC implementation aligned with this paper and full attention (using Flash Attention 2). The latency of the proposed method grows nearly linearly with the number of shots (i.e., sequence length L).
Summary
The adaptive context mixture (MoC) method proposed in this paper successfully validates a core claim: through learnable, structure-aware sparse attention, the model can reallocate computational resources from redundant information to key visual events. This not only brings significant efficiency gains (more than 7x fewer FLOPs and a 2.2x speedup), but also improves the model’s long-term memory and content diversity in long video generation without sacrificing perceptual quality. MoC provides an effective blueprint for building scalable, controllable next-generation long-video generation models, showing that solving the quadratic attention bottleneck is a key path to unlocking emergent long-term memory capabilities in models.
Limitations: The current model has only been tested on minute-level videos, and its potential on even longer sequences remains to be explored. In addition, the current implementation still has room for optimization; for example, software-hardware co-design through customized CUDA/Triton kernels could further improve runtime speed.