MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
The Third Dimension of AI Agents: MiroThinker Makes 600 Tool Calls in a Single Task, with Performance Rivalling GPT-5

While the entire AI field is still frantically “scaling” model parameters and context length, a new dimension of performance improvement has quietly emerged. If an AI Agent can interact with external tools up to 600 times while completing a single task, how terrifyingly powerful would its research and reasoning abilities become?
Paper Title: MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
ArXiv URL:http://arxiv.org/abs/2511.11793v2
This is the answer revealed by the latest open-source research Agent—MiroThinker. It is not just a larger model or a longer context window; it is a pioneering proposal of Interaction Scaling as the “third dimension” of performance improvement, surpassing all existing open-source Agents on multiple benchmarks and coming close to top closed-source models such as GPT-5.
What Is Interaction Scaling?
In the past, we mainly improved AI capabilities in two ways:
-
Model scaling: making the model larger (for example, from 7B to 70B).
-
Context scaling: allowing the model to “see” more (for example, from 4K to 2 million Chinese characters).
But MiroThinker’s research found that this is still not enough. Especially for “research” tasks that require complex reasoning and information gathering, the Agent needs to continuously interact with the external environment (such as search engines and code executors), forming a “think-act-observe” loop.
Interaction scaling means systematically training the model so it can handle deeper and more frequent Agent-environment interactions.
This is completely different from simply telling the model to “think a few more steps” at test time. In the latter case, without external feedback, the longer the reasoning chain, the greater the risk of error accumulation. Interaction scaling, by contrast, uses environmental feedback and external information to correct errors and optimize the path in real time, making the Agent’s thinking deeper and more resilient.
Inside MiroThinker’s Architecture
MiroThinker is built on the classic ReAct (Reasoning and Acting) paradigm, but to support ultra-high-frequency interactions, it incorporates a carefully designed architecture.
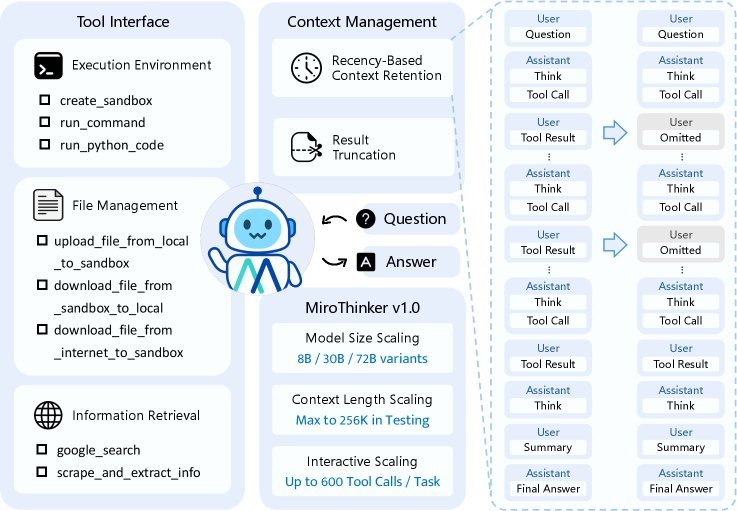
Its core components include:
-
Modular tool interfaces: It provides a powerful toolbox, including a Linux sandbox for safe code execution, a file management system, and efficient information retrieval tools.
-
Intelligent information retrieval: Its web scraping tool does not simply copy and paste full text; instead, it has a built-in lightweight LLM (such as Qwen3-14B) that intelligently extracts the most relevant information based on task requirements. This greatly improves information acquisition efficiency.
-
Efficient context management: To fit 600 tool calls into a 256K window, context management is crucial. MiroThinker adopts two clever strategies:
-
Recency-Based Context Retention: Research found that the Agent’s next action mainly depends on the most recent few observations. Therefore, MiroThinker keeps only the full text of the latest few tool outputs in the context, while earlier outputs are omitted, freeing up space for longer interactions.
-
Result truncation: For overly long code execution or command outputs, the system automatically truncates them and appends the \([Result truncated]\) tag to prevent context overflow.
Massive, High-Quality Training Data: MiroVerse v1.0
To train a model with deep interactive capabilities, the research team built a large-scale synthetic dataset called MiroVerse v1.0.
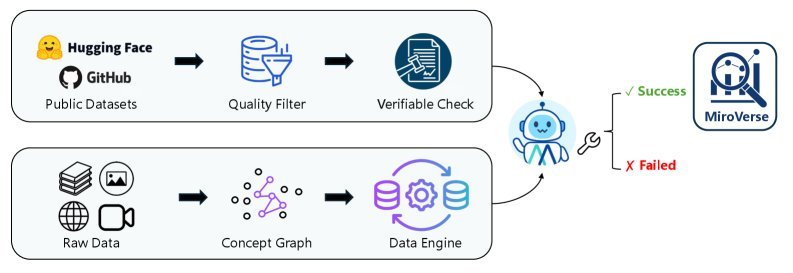
The dataset generation process is extremely complex. First, knowledge graph techniques are used to construct complex multi-document question-answer pairs (MultiDocQA) from sources such as Wikipedia and web pages. Then, a powerful Agent trajectory synthesis framework converts these question-answer pairs into high-quality “think-act-observe” trajectory data.
In this way, MiroThinker learned during training how to handle complex tasks that require multi-step reasoning and cross-document information integration.
Three-Stage Training: From Imitation to Creation
MiroThinker’s training pipeline is divided into three carefully designed stages, allowing it to grow from an imitator into a creator.
-
Supervised fine-tuning (SFT): The model first learns to imitate expert trajectories and masters basic tool use and reasoning patterns.
-
Preference optimization (DPO): Next, the model learns to distinguish “good” solutions from “bad” ones, making its decisions better aligned with task objectives.
-
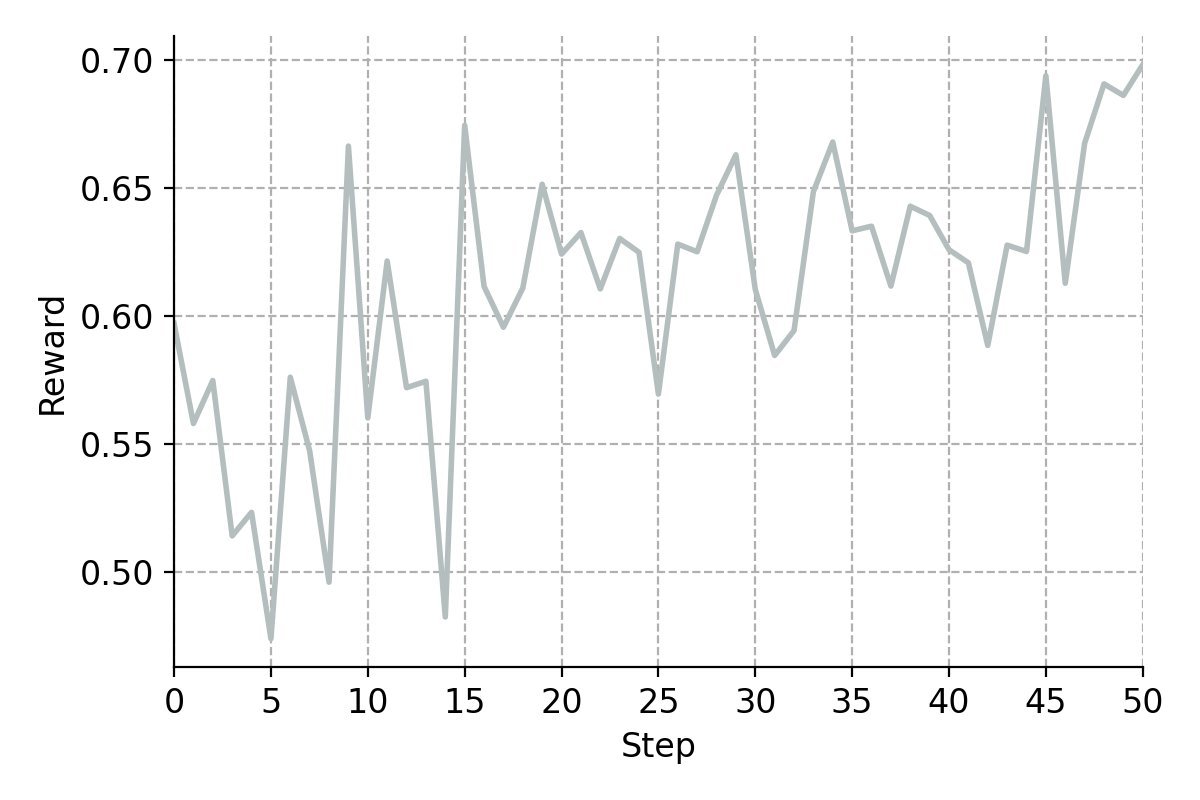
Reinforcement learning (RL): Finally, and most importantly, the research team used the GRPO (Group Relative Policy Optimization) algorithm, allowing the Agent to learn through online exploration and trial and error in real environments. It was in this stage that the model truly learned how to perform deep interaction and discover innovative solution paths.
Stunning Performance
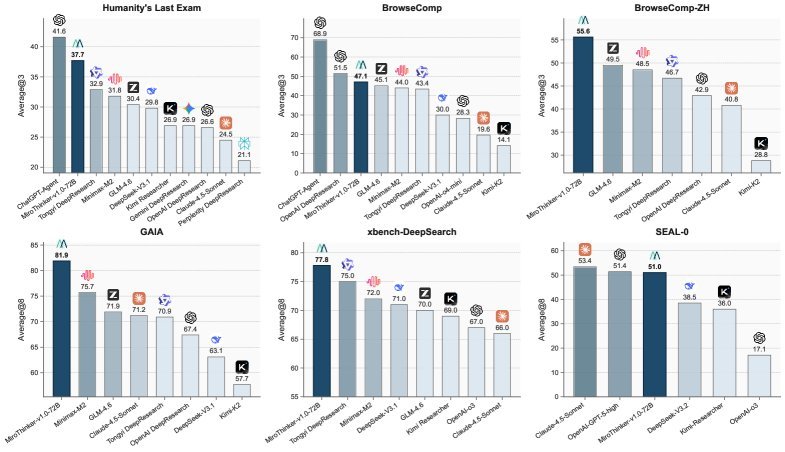
MiroThinker’s performance did not disappoint. On multiple authoritative Agent evaluation benchmarks such as GAIA, HLE, and BrowseComp, its 72B version achieved SOTA (State-of-the-Art) results.
-
On the GAIA benchmark, it reached an accuracy of 81.9%, 6.2 percentage points higher than the strongest open-source competitor.
-
On the HLE (Humanity’s Last Exam) benchmark, it scored 37.7%.
-
On the BrowseComp (web browsing comprehension) benchmark, it reached an accuracy of 47.1%, surpassing models such as MiniMax-M2.
These results consistently show that as interaction depth increases, MiroThinker’s performance also improves predictably. This confirms that interaction depth, like model size and context length, has a clear scaling effect (Scaling Law).
Conclusion
The emergence of MiroThinker points AI Agent development in a new direction. It eloquently proves that to build the next generation of powerful research Agents, we must not only focus on the size and memory of the model itself, but also on its ability to “interact” with the world.
Interaction scaling, as the bridge connecting model intelligence and the real world, has officially become the third key dimension in the evolution of AI Agents. With MiroThinker open-sourced, we have reason to believe that a new Agent era—driven by the community and marked by greater transparency and innovation—is on the way.