Memorization Dynamics in Knowledge Distillation for Language Models
Distillation as Forgetting? Large Model Memorization Rate Plummets by 50%, Uncovering the “Privacy Dividend” of Knowledge Distillation

In today’s LLM era, Knowledge Distillation (KD) has become a standard way to “cut costs and boost efficiency.” Whether it is the distilled series of DeepSeek-R1 or the small on-device models released by major vendors, the essence is to transfer the capabilities of a trillion-parameter giant to a lighter-weight model.
ArXiv URL:http://arxiv.org/abs/2601.15394v1
We usually think distillation is only about making a small model “stronger.” But have you ever considered that the distillation process itself may also be an excellent “privacy firewall”?
The latest research from CMU, Meta, and Northeastern University reveals a counterintuitive phenomenon: compared with standard fine-tuning, knowledge distillation can reduce the memorization rate of training data by more than 50%. This means the distilled model is not only smarter, but also less likely to leak private information from the training data.
This article will take you through the paper Memorization Dynamics in Knowledge Distillation for Language Models and show how distillation, while preserving capability, quietly “forgets” those dangerous verbatim memories.
Key Finding: Distillation Makes the Model “More Tight-Lipped”
The research team conducted extensive experiments on three model families: Pythia, OLMo-2, and Qwen-3, comparing the “teacher” model, the “student” model, and the “baseline” model (i.e., a model of the same size trained with standard fine-tuning).
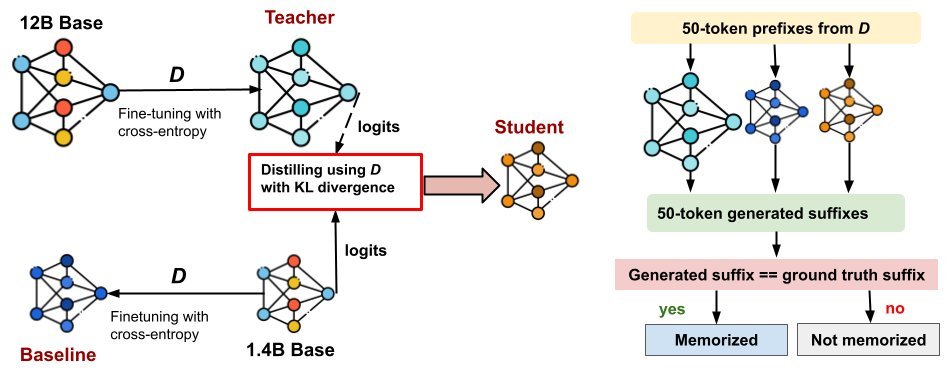
The most important conclusion is very straightforward: the memorization rate of distilled models is significantly lower than that of standard fine-tuned models.
On datasets such as FineWeb and Wikitext, the student model’s memorization rate was reduced by 2.4x or more compared with the baseline model. More importantly, this reduction in memorization did not come at the cost of capability. On the contrary, the student model performed better than the baseline model in perplexity and validation loss.
This is an ideal “win-win” situation: the model learns the teacher’s generalization ability, while rejecting the teacher’s rote memorization of specific samples.
The table below shows the memorization rate comparison across different model families, and it is clear that $M_{student}$ is far lower than $M_{baseline}$:
Which Data Is Easy to “Remember”?
If distillation can reduce memorization, then what exactly does it remember? The study found that memorization is not random, but highly deterministic.
The researchers introduced a concept: “easy-to-memorize” samples.
-
Hierarchy effect: Larger models usually contain the memories of smaller models. For example, the 12B teacher model remembered 80% of what the 1.4B baseline model remembered.
-
Distillation filtering: The student model almost only remembers the samples that are “easiest to remember.” The data show that among the samples memorized by the student model, 95.7% are the “common” ones that both the teacher and baseline models can remember.
-
Refusal to inherit: For those “exclusive memories” remembered only by the teacher model (often overfitted or difficult samples), the student model inherits very little of them (only about 0.9%).
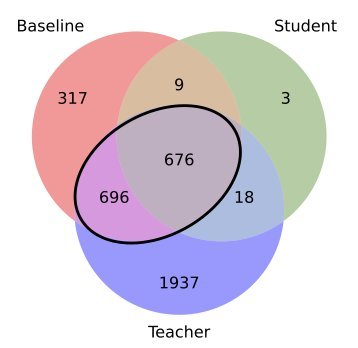
The figure above clearly shows this overlap: the bold black box in the middle represents those “easy-to-memorize” samples, and the student model’s memorization almost entirely falls within this area.
Predicting Leakage Risk Before Training
If memorization follows patterns, can we predict which data will be leaked before training even begins?
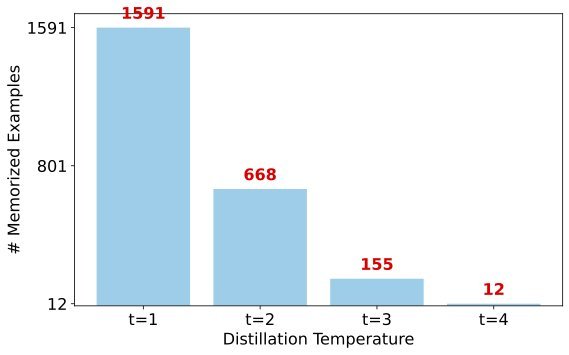
The answer is yes. The study shows that features such as zlib entropy (compression ratio), KL divergence, and perplexity can be used to train a simple classifier to predict which samples the student model will memorize.
This has huge engineering value: you do not need to wait until training is finished to audit the model; instead, you can identify high-risk samples during data preprocessing. Experiments show that if these samples predicted to be “memorized” are removed before distillation, the final model’s memorized samples can drop from 1698 to 4, reducing the risk by 99.8%.
Deep Dive: Why Can Distillation Suppress Memorization?
Why does standard cross-entropy training lead to memorization, while KL-divergence-based distillation suppresses it?
The paper provides an elegant explanation through Shannon Entropy and Log-Probability:
-
Standard fine-tuning (baseline model): When facing high-entropy (i.e., highly uncertain, hard-to-learn) samples, the model is forced to memorize them in order to minimize loss, resulting in “high entropy but high confidence,” which is forced memorization.
-
Knowledge distillation (student model): When the teacher model faces difficult samples, the output distribution itself is smooth (high entropy). By imitating the teacher through KL divergence, the student learns to “remain uncertain about this sample” rather than “memorize this word by rote.”
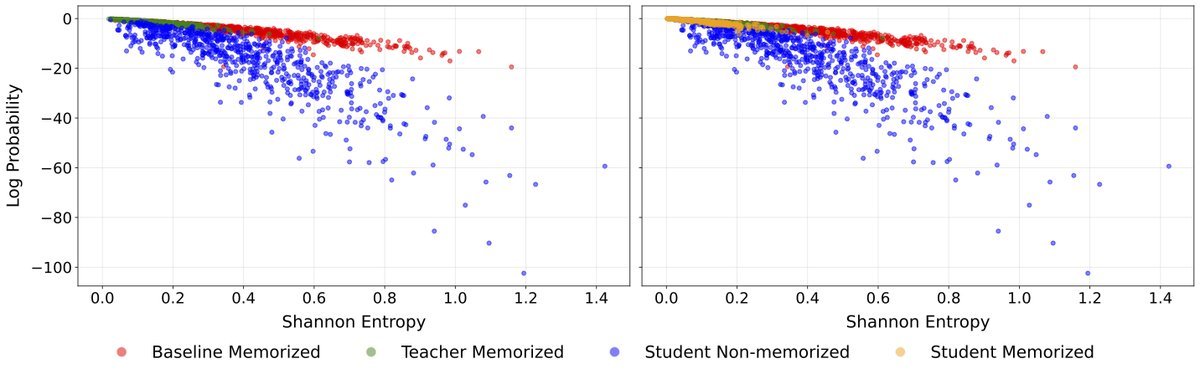
As shown in the figure above, the red points (baseline model) contain many high-entropy samples assigned extremely high probabilities (forced memorization), while the blue points (student model) honestly maintain lower confidence.
Soft Distillation vs. Hard Distillation: Which Is Safer?
In practice, we sometimes cannot obtain the teacher model’s full probability distribution (Logits) and can only get the text it generates. This is sequence-level distillation (Sequence-level KD, or hard distillation).
This raises a key question: Is hard distillation safe?
The study found that although soft distillation (logit-level) and hard distillation have roughly the same overall memorization rate (both are very low), hard distillation carries greater risk.
-
Soft distillation: Transfers knowledge through probability distributions, blurring specific details.
-
Hard distillation: Directly learns the text generated by the teacher. The results show that hard distillation inherited 2.7x as much “teacher-specific memory” as soft distillation.
This means that if you use data generated by GPT-4 to train a small model (hard distillation), your small model is more likely to leak private fragments from GPT-4’s training data.
Conclusion
This paper gives us a completely new perspective on knowledge distillation. It is not only a powerful way to improve small-model performance, but also a natural privacy defense mechanism.
-
Distillation as forgetting: Compared with fine-tuning, distillation can greatly reduce rote memorization of training data.
-
Targeted effect: The model tends to remember “simple” samples while filtering out complex long-tail samples.
-
Prevention first: We can predict and remove high-risk data before training using simple metrics.
-
Be cautious with hard distillation: If privacy matters, try to use soft distillation with Logits, because hard distillation is more likely to inherit the teacher model’s “private stash.”
In today’s push to deploy large models, making good use of this property of distillation may help us find a better balance between performance and security.