MARS: Optimizing Dual-System Deep Research via Multi-Agent Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.04935v1
-
Authors: Yong Jiang; Xuanzhong Chen; Hao Sun; Wayne Xin Zhao; Minpeng Liao; Donglei Yu; Wenqing Wang; Fei Huang; Kai Fan; Zile Qiao; and 12 others
-
Publishing Organization: Alibaba Group; Renmin University of China
TL;DR
This paper proposes a dual-system multi-agent reinforcement learning framework called MARS. By simulating the human cognitive dual-system model—System 1’s fast intuition and System 2’s deliberate reasoning—the framework enables two intelligent agents to collaborate on complex reasoning tasks that require external knowledge, significantly improving the model’s deep research and reasoning capabilities in dynamic information environments.
Key Definitions
The core of this paper is the construction of a framework that simulates the human cognitive dual system, mainly inheriting and extending the following concepts:
- Dual-System Framework: Inspired by the dual-process theory of human cognition, this paper splits the functions of large language models (LLMs) into two cooperating systems.
- System 1: Responsible for fast, intuitive thinking. In the MARS framework, it is specifically used to efficiently process and summarize the large amount of potentially noisy information returned by external tools (such as search engines), distilling it into concise key points.
- System 2: Responsible for slow, deliberate reasoning. In the MARS framework, it leads the entire reasoning process, performs planning, generates complex reasoning steps, and decides when and how to call external tools to obtain information or perform computation.
- Multi-Agent Reinforcement Learning (MARL): This paper treats System 1 and System 2 as two independent intelligent agents, activated on the same base LLM through different prompts. A multi-agent reinforcement learning method is used to jointly optimize these two agents to maximize the final reward for completing the task together.
Related Work
At present, Large Reasoning Models (LRMs) perform well on complex problems, but they often tend to “overthink” simple ones, leading to unnecessary token consumption. At the same time, all large language models are constrained by the cutoff date of their pretraining data, making it difficult to adapt to rapidly changing environments and acquire the latest knowledge.
Although Retrieval-Augmented Generation (RAG) technology alleviates the problem of outdated knowledge by introducing external knowledge sources, existing RAG systems face two major bottlenecks: 1) when processing multiple long documents (such as full web pages or research papers), they are prone to “information overload”; 2) when compressing information to avoid overload, they may lose critical details.
This paper aims to address the above issues, namely how to efficiently leverage massive, dynamic external information to enhance complex reasoning ability without sacrificing reasoning depth or causing information overload.
Method
This paper proposes a deep research multi-agent system called MARS (Multi-Agent System for Deep Research). Its core is an innovative dual-system collaboration framework, which is end-to-end optimized through a dedicated multi-agent reinforcement learning strategy.
Dual-System Collaboration Framework
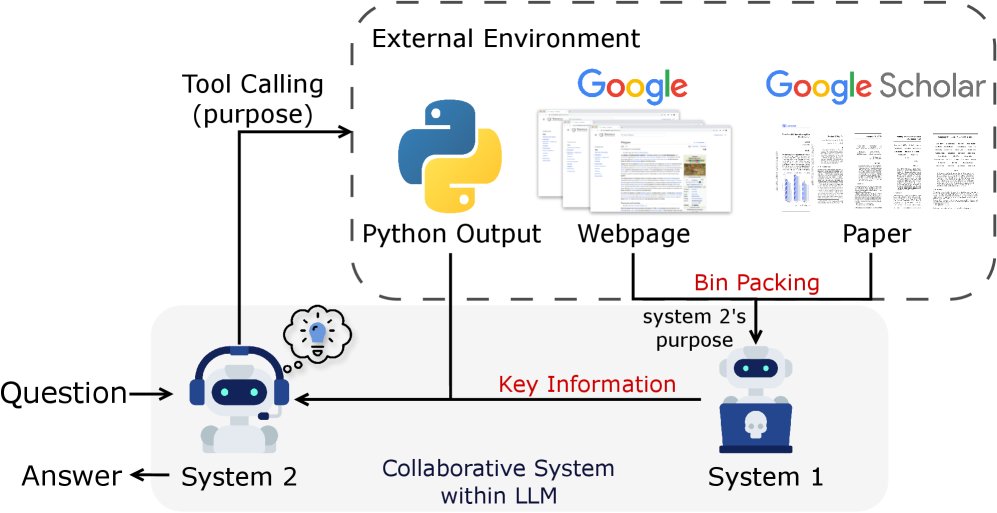
The MARS framework integrates System 1’s intuitive processing ability and System 2’s deliberate reasoning ability into the same LLM, activating them through different prompts. The two work together through a clearly defined collaboration process to solve complex problems.
This collaboration process can be formalized as multi-round interaction:
-
System 2 performs reasoning and planning: In round $i$, System 2 ($\pi_{\text{sys}_2}$) generates reasoning steps $s_i$ based on the current context $c_i$ (which includes the initial question and information from previous rounds), and may also generate a tool call request (including tool parameters $t_i$ and the call purpose $p_i$).
\[s_i, (t_i, p_i) = \pi_{\text{sys}_2}(c_i)\] - External tool execution: If $t_i$ exists, the external environment (such as Google Search) executes the call and returns the raw output $o_{t_i}$.
-
System 1 processes information: System 1 ($\pi_{\text{sys}_1}$) uses the “purpose” $p_i$ provided by System 2 to process the massive raw output $o_{t_i}$ and distill it into concise, useful information $\tilde{o}_{t_i}$.
\[\tilde{o}_{t_i} = \pi_{\text{sys}_1}(\text{Bin-Packing}(o_{t_i}^{(1)}, \dots, o_{t_i}^{(n_{t_i})}), p_i)\] -
Context update: The reasoning, tool call, and distilled information from this round are integrated to update the context and prepare for the next round.
\[c_{i+1} = c_i \oplus \{s_i, t_i, p_i, \tilde{o}_{t_i}\}\]
This process iterates until System 2 determines that a final answer can be generated.
Innovations
The main innovation of this method lies in the clear division of labor and joint optimization:
- Specialized division of labor: System 2 focuses on high-level, global reasoning and strategy planning, while offloading the tedious, time-consuming task of large-scale information processing to System 1. This prevents System 2’s context window from being overwhelmed by raw information, allowing it to handle more comprehensive and deeper information and improving both the breadth and depth of reasoning.
- Synergistic gain: Through the bridge of “purpose” $(p_i)$, System 1 can precisely understand System 2’s needs and perform targeted information distillation. This design allows the two systems to each do what they do best, forming an efficient and robust closed loop for problem solving.
Dual-System Optimization Strategy
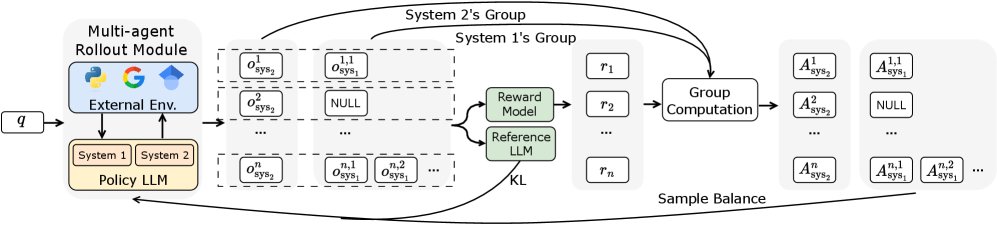
To enable end-to-end training, this paper proposes an optimization strategy based on multi-agent reinforcement learning, extending the GRPO (Group Relative Policy Optimization) algorithm.
Efficient Content Handling with Bin Packing
When System 1 processes large amounts of variable-length text returned by tools, to improve parallel processing efficiency, this paper adopts a bin-packing strategy based on the First Fit Decreasing (FFD) algorithm. This strategy efficiently organizes variable-length text blocks into optimally sized batches, reducing the total number of times System 1 needs to generate summaries.
Advantage Precomputation and Balanced Sampling Mechanism
During training, one reasoning trajectory produces 1 System 2 sample and multiple System 1 samples (depending on the number of tool calls), leading to a severe sample imbalance. To address this, the paper proposes:
-
Advantage precomputation: First, for all System 1 and System 2 samples generated in a batch, reward normalization is performed within their respective groups, and the advantage function (Advantage) is computed.
\[A_{\text{sys}_2}^{k} = \frac{r_{\text{sys}_2}^{k}-\text{mean}(\mathbf{r}_{\text{sys}_2})}{\text{std}(\mathbf{r}_{\text{sys}_2})}, \quad A_{\text{sys}_1}^{k,j} = \frac{r_{\text{sys}_1}^{k,j}-\text{mean}(\mathbf{r}_{\text{sys}_1})}{\text{std}(\mathbf{r}_{\text{sys}_1})}\] -
Balanced sampling: After computing the advantages for all samples, the excessive System 1 samples are randomly downsampled (or upsampled if insufficient) so that their number matches the number of System 2 samples. This “compute first, sample later” approach ensures the statistical integrity of the advantage distribution.
Multi-Agent Training Objective
After balanced sampling, System 1 and System 2 are jointly optimized using the extended GRPO framework. The total loss is the sum of the losses of the two systems:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{sys}_2} + \mathcal{L}_{\text{sys}_1}\]The loss for each system follows the GRPO objective, which includes a policy loss term and a KL-divergence regularization term to ensure that the model learns new policies without drifting too far from the original model.
Experimental Results
This paper conducted extensive experiments on the highly challenging HLE (Humanity’s Last Exam) benchmark and 7 knowledge-intensive question answering tasks.
Main Results
- HLE benchmark performance: On HLE, MARS outperformed all other open-source models, including WebThinker and C-3PO based on larger-parameter models, achieving a significant 3.86% improvement. This demonstrates that the dual-system paradigm can effectively enhance complex reasoning ability even when using only 7B/8B-scale models, significantly narrowing the gap with top-tier closed-source models.
| Model | Overall (%) | Math | Physics | Chemistry | Biology/Medicine | CS/AI | Humanities & Social Sciences | Other |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7B-Instruct | 2.51 | 3.51 | 1.97 | 1.83 | 2.89 | 3.12 | 1.70 | 2.65 |
| Qwen3-8B | 3.15 | 4.60 | 3.61 | 2.33 | 3.32 | 3.84 | 1.98 | 2.66 |
| MARS (Qwen2.5-7B) | 6.51 | 10.22 | 4.94 | 5.00 | 6.40 | 6.25 | 3.97 | 5.92 |
| MARS (Qwen3-8B) | 7.38 | 9.92 | 6.25 | 5.50 | 5.94 | 6.25 | 3.72 | 7.51 |
- Performance on knowledge-intensive tasks: Across 7 knowledge-intensive tasks, MARS achieved an average performance improvement of 8.9% over the previous SOTA method C-3PO. The advantage is especially pronounced on multi-hop tasks that require multi-step reasoning, with an average gain of 12.2%. This shows that MARS’s framework greatly enhances the model’s ability to integrate multi-source information for complex reasoning chains.
| Model | NQ | TriviaQA | PopQA | HotpotQA | 2Wiki | Musique | Bamboogle | Average |
|---|---|---|---|---|---|---|---|---|
| C-3PO | 78.4 | 82.5 | 60.1 | 63.8 | 66.8 | 49.3 | 59.4 | 65.76 |
| MARS | 84.5 | 89.8 | 65.3 | 74.1 | 78.2 | 62.7 | 68.8 | 74.77 |
| Gain | +6.1 | +7.3 | +5.2 | +10.3 | +11.4 | +13.4 | +9.4 | +8.9 |
Process Analysis and Ablation Study
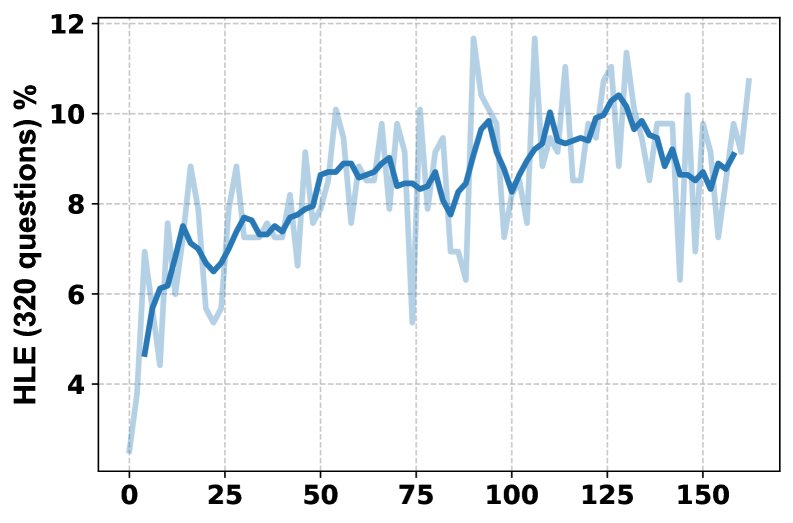
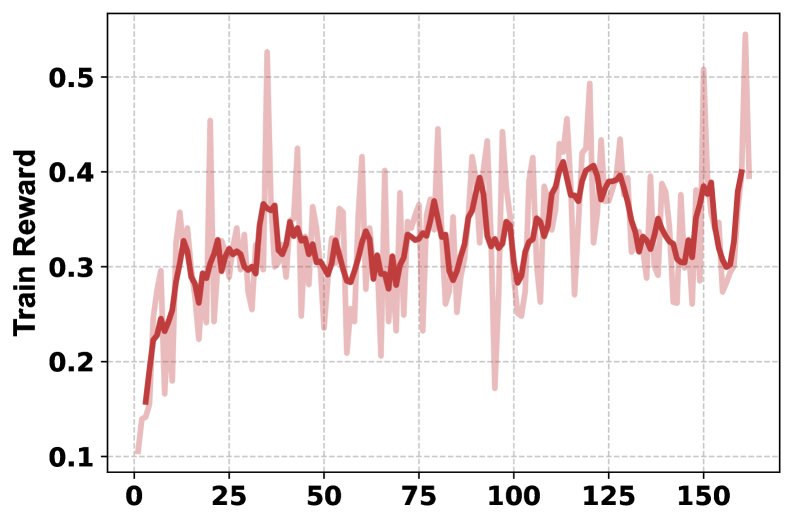
- Training process analysis: The training curves show that, as training progresses, the HLE score steadily improves, the model learns to use multiple tools more frequently (from once per question to more than twice), and the response lengths generated by System 1 and System 2 also increase accordingly, indicating that both systems are learning to produce more detailed outputs.
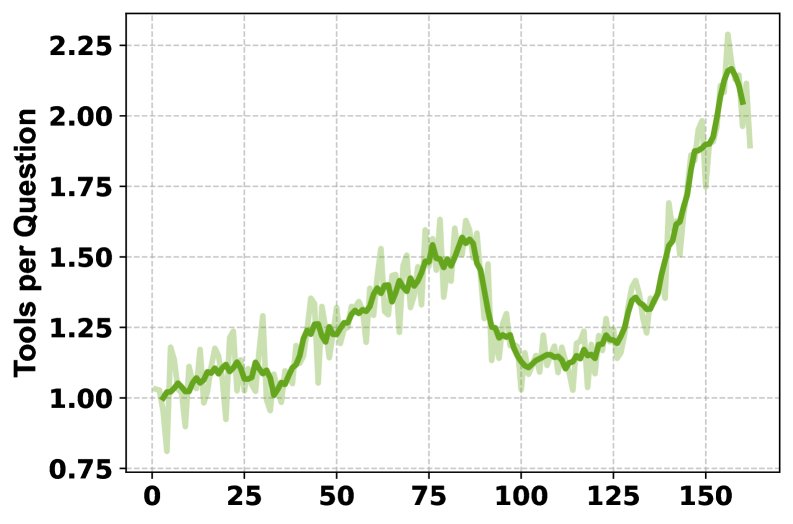
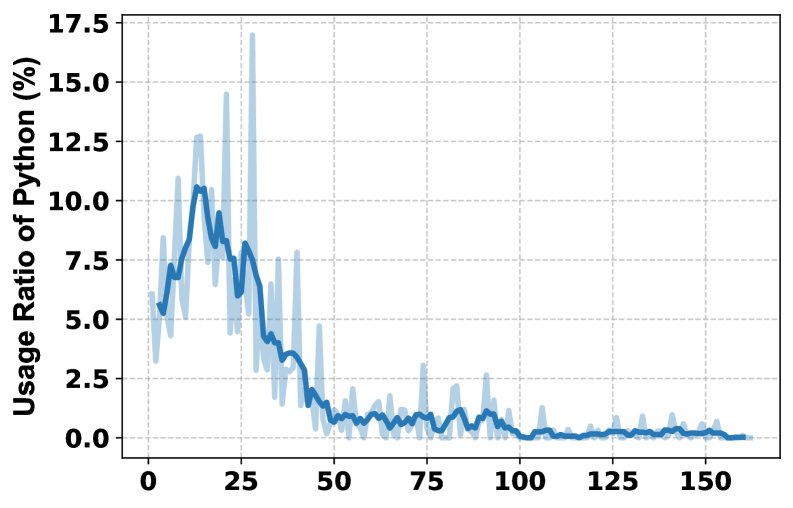
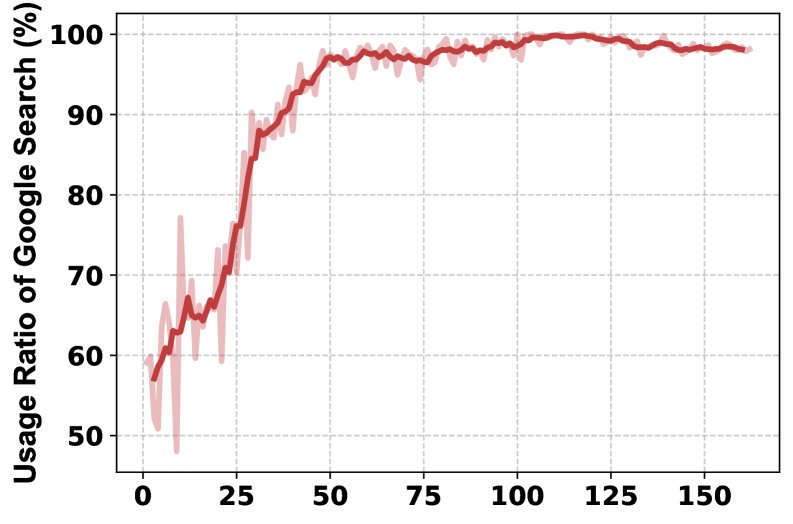
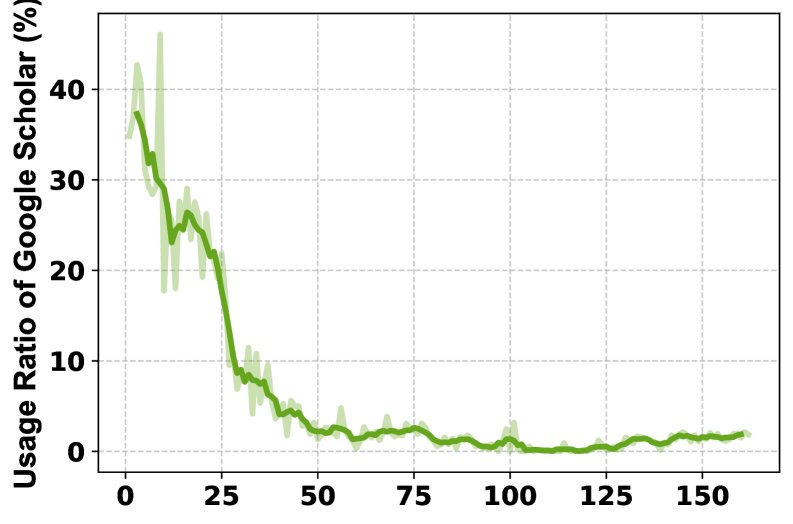

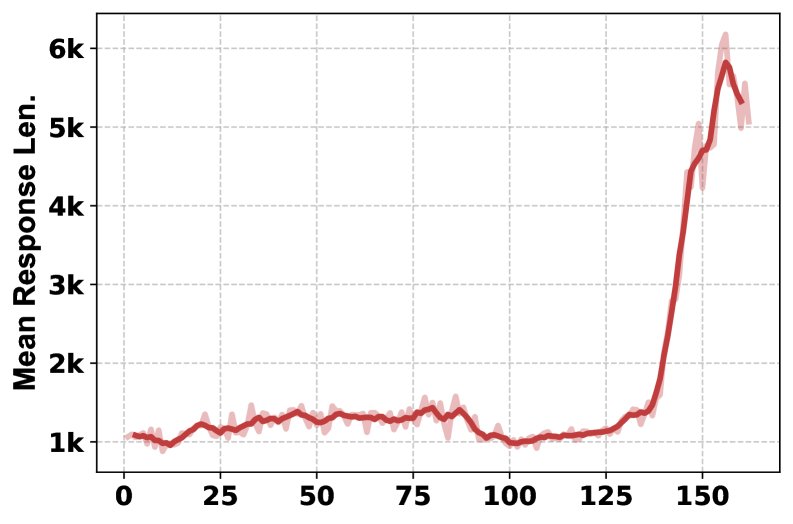
- Ablation study: The ablation study on tools shows that different tools contribute uniquely to different subject areas. Removing the Python interpreter has the greatest impact on math and physics, while removing Google Scholar has the greatest impact on computer science. The full-featured MARS (with all tools) achieves the best overall performance, demonstrating the complementarity and necessity of a multi-tool combination.
| Tool | Overall (%) | Math | Physics | Chemistry | Biology/Medicine | CS/AI | Humanities & Social Sciences | Other |
|---|---|---|---|---|---|---|---|---|
| All | 7.38 | 9.92 | 6.25 | 5.50 | 5.94 | 6.25 | 3.72 | 7.51 |
| w/o Python | 6.47 | 8.38 | 5.27 | 7.50 | 6.40 | 6.25 | 3.21 | 5.81 |
| w/o Google | 6.00 | 9.07 | 3.30 | 5.50 | 5.48 | 6.25 | 4.22 | 5.81 |
| w/o Scholar | 7.15 | 10.22 | 5.92 | 5.50 | 5.48 | 3.12 | 3.97 | 9.09 |
Final Conclusion
The experimental results strongly demonstrate that the proposed MARS framework, by simulating dual-system cognition and optimizing with multi-agent reinforcement learning, can efficiently leverage massive external information and significantly improve model performance on various complex reasoning tasks without sacrificing computational efficiency. This method provides an effective paradigm for building more powerful and more efficient AI research and reasoning systems.