MAPEX: A Multi-Agent Pipeline for Keyphrase Extraction
-
ArXiv URL: http://arxiv.org/abs/2509.18813v2
-
Authors: Qicheng Li; Shiwan Zhao; Aobo Kong
-
Publishing Organization: Nankai University
TL;DR
This paper proposes MAPEX, a multi-agent collaborative framework for keyphrase extraction. By designing a dynamic dual-path strategy for documents of different lengths—knowledge-driven and topic-guided—it significantly improves the zero-shot keyphrase extraction performance of large language models (LLMs).
Key Definitions
This paper introduces or adopts the following key concepts:
- Multi-Agent Collaboration: A system design paradigm in which multiple independent Agents work together to complete complex tasks. In this paper, the framework is jointly operated by three Agents: an expert recruiter, a candidate extractor, and a domain expert.
- Dual-Path Pipeline Strategy: The core mechanism that applies different processing flows to documents of different lengths.
- Knowledge-driven extraction: The path designed for short texts. It enhances the semantic understanding of candidate keyphrases by retrieving information from external knowledge bases such as Wikipedia.
- Topic-guided extraction: The path designed for long texts. It first identifies the document’s core topics to guide the subsequent keyphrase reranking and selection process, addressing semantic dilution in long documents.
- Expert Recruitment: A specific module in the framework, handled by the “expert recruiter” Agent. This Agent analyzes the document content and dynamically assigns an appropriate expert role to the “domain expert” Agent (for example, “computer graphics expert”), making the extraction process more domain-specific.
Related Work
Current unsupervised keyphrase extraction techniques are mainly divided into traditional methods (statistics, graph, embedding) and language-model-based prompt-based methods. With the rise of large language models (LLMs), prompt-based methods have become mainstream. However, existing methods generally suffer from a key bottleneck: most of them adopt a single, fixed inference flow and prompt strategy, without distinguishing between document length or the underlying LLM model. This one-size-fits-all design cannot fully exploit the reasoning and generation potential of LLMs in diverse scenarios, limiting their generalization ability on keyphrase extraction tasks.
This paper aims to address the above problem: how to design a more flexible and powerful framework that fully leverages the capabilities of LLMs, especially in handling the challenges posed by documents of different lengths, thereby improving the accuracy and robustness of zero-shot keyphrase extraction.
Method
This paper proposes MAPEX (Multi-Agent Pipeline for Keyphrase Extraction), a multi-agent pipeline framework. The framework works through three Agents and a dual-path strategy dynamically selected according to document length.
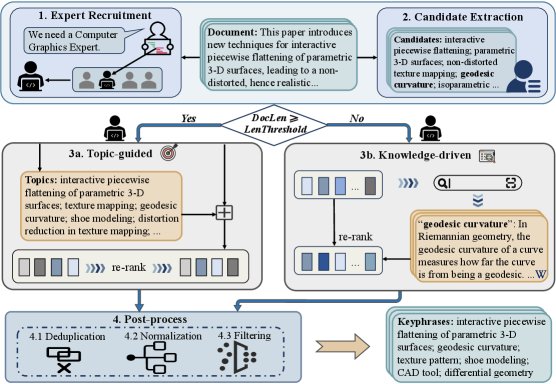
Agent Roles and Responsibilities
The MAPEX framework includes three Agents that work collaboratively, with their behavior guided by carefully designed prompts.
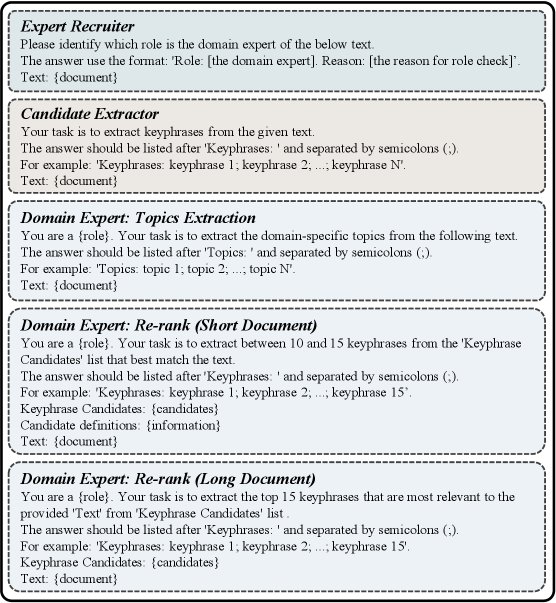
- Expert Recruiter: This Agent first analyzes the document content to determine its professional domain. It then assigns an appropriate expert role to the “domain expert” Agent (for example, “software engineer”) and provides the rationale for the assignment. This makes the subsequent extraction process more professionally informed.
- Candidate Extractor: This Agent is responsible for generating a broad pool of candidate keyphrases from the original document. It is not assigned any specific role, with the goal of ensuring diversity in the initial candidate set and avoiding the omission of important lexical variants due to the limitations of a specific expert role.
Core Innovation: Dual-Path Strategy
To effectively handle documents of different lengths, MAPEX introduces a length threshold \(ℓ\) and dispatches documents to two different processing paths based on this threshold. The core motivation behind this design is that external knowledge provides significant semantic supplementation for short texts, but its advantage weakens for long texts due to context window limitations and semantic dilution.
-
Long-text path (topic-guided): This path is activated when the document length $$ d_i ≥ ℓ$$. - Domain Expert first identifies and generates a series of prominent topics that represent the document’s core ideas.
- These topics are merged with the candidate keyphrases generated by the “Candidate Extractor”.
- Finally, the domain expert reranks and filters this enhanced candidate list to produce an initial keyphrase list.
-
Short-text path (knowledge-driven): This path is activated when the document length $$ d_i < ℓ$$. - To compensate for the lack of contextual information in short texts, the “domain expert” invokes an external knowledge retrieval tool (such as \(WikiQuery\)) for each candidate keyphrase $c_{ij}$ to obtain its definition and background information.
-
The external knowledge for all candidate terms is aggregated into a knowledge dictionary:
\[W_i = \bigcup_{c \in C_i} \mathrm{WikiQuery}(c)\]
- Based on this enhanced knowledge, the “domain expert” reranks the candidate terms and outputs an initial keyphrase list.
Post-processing
After the “domain expert” generates the initial results, the framework performs a post-processing step to improve the quality of the final output. This step includes three subtasks:
- Remove redundancy: Delete duplicate phrases.
- Standardization: Unify abbreviations and their full forms.
- Filter hallucinations: Remove phrases that do not appear in the original text, ensuring that all keyphrases are derived from the document.
Advantages
- Adaptability: The dual-path strategy allows the model to automatically choose the optimal processing method based on document length, addressing the limitations of one-size-fits-all approaches.
- Professionalism: The expert recruitment mechanism introduces a domain perspective, making keyphrase extraction better aligned with the text’s professional background.
- Robustness: By combining general candidate extraction with expert filtering, the framework expands the candidate space while ensuring final quality.
- High fidelity: The post-processing step effectively suppresses LLM hallucinations, ensuring the accuracy and source reliability of the keyphrases.
Experimental Results
Overall Performance
Experiments were conducted on six benchmark datasets, including Inspec and SemEval-2010, using three different LLMs such as Mistral-7B and Qwen2-7B as the underlying models.
| Method | Model | Inspec | SemEval-10 | SemEval-17 | DUC-2001 | NUS | Krapivin | Average |
|---|---|---|---|---|---|---|---|---|
| Traditional Unsupervised | ||||||||
| SIFRank | - | 35.15 | 29.56 | 38.38 | 26.68 | 27.69 | 22.09 | 30.03 |
| MDERank | - | 36.31 | 30.13 | 42.17 | 27.35 | 29.80 | 25.12 | 31.81 |
| PromptRank | BART | 39.56 | 32.55 | 45.34 | 31.33 | 30.65 | 27.48 | 34.49 |
| LLM Baselines | ||||||||
| Base | Mistral-7B | 37.98 | 29.59 | 42.16 | 28.52 | 27.91 | 25.26 | 31.90 |
| Hybrid | Mistral-7B | 38.45 | 30.11 | 42.94 | 29.07 | 28.98 | 26.17 | 32.62 |
| MAPEX (this paper) | Mistral-7B | 40.31 | 32.88 | 45.92 | 30.64 | 33.34 | 28.75 | 35.31 |
| (Other LLM results) | … | … | … | … | … | … | … | … |
- Beyond SOTA: The results show that MAPEX significantly outperforms baseline methods across all LLMs and datasets. Using Qwen2.5-7B as the backbone, its average F1@5 score reaches 24.30%, which is 2.44% higher than the previous state-of-the-art unsupervised method, PromptRank (22.81%).
- Improved LLM Performance: Compared with the standard LLM baseline (Base), MAPEX brings significant gains to all underlying LLMs. For example, it raises the average F1@5 score of Mistral-7B from 18.23% to 22.24%, an increase of 4.01%.
- Long-Text Advantage: MAPEX performs especially well on long-document datasets such as NUS, with an absolute F1@5 improvement of up to 5.22%, demonstrating the effectiveness of the topic-guided strategy.
Ablation Study
To verify the contribution of each module, this paper conducted an ablation study on the Mistral-7B model.
- All modules are effective: Starting from the most basic “candidate word extraction,” the model progressively adds “expert roles,” “topic/knowledge branches,” and “post-processing,” with each step bringing performance improvements. This shows that every component in the MAPEX framework plays a positive role.
- The expert role brings more obvious improvements on long-document datasets; the topic and knowledge branches contribute significant performance gains in all cases; post-processing further improves result accuracy.
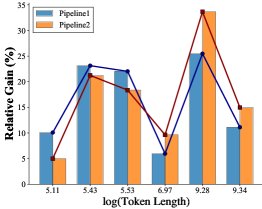 (a) Performance gains relative to the baseline
(a) Performance gains relative to the baseline
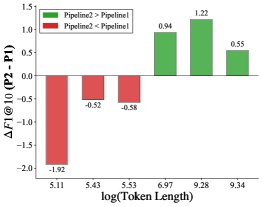 (b) Performance differences between the knowledge-driven and topic-guided paths
(b) Performance differences between the knowledge-driven and topic-guided paths
- Rationality of the path-selection threshold: By analyzing the performance of the two paths on texts of different lengths, the experiment found a clear performance crossover region (Figure b above). The knowledge-driven path has a relatively greater advantage on short texts (the blue line in Figure a above), while the topic-guided path performs better on long texts. The length threshold chosen in this paper, \(ℓ = 512\) tokens (approximately \(ln(length) ≈ 6.24\)), is right in the center of this crossover region and has been verified as a reasonable choice.
Final Conclusion
The MAPEX framework proposed in this paper successfully addresses the “one-size-fits-all” problem of traditional LLM methods in keyword extraction tasks by introducing multi-agent collaboration and a dynamic dual-path strategy. Experiments demonstrate that the framework has strong generalization ability and versatility, achieving performance that surpasses existing SOTA methods across multiple LLMs, especially when handling complex and long documents.