LIMI: Less is More for Agency
-
ArXiv URL: http://arxiv.org/abs/2509.17567v1
-
Authors: Xiaojie Cai; Liming Liu; Jie Sun; Mohan Jiang; Jifan Lin; Wenjie Li; Dequan Wang; Jinlong Hou; Shijie Xia; Yang Xiao; and 17 others
-
Publishing Organization: GAIR; PolyU; SII; Shanghai Jiao Tong University; USTC
TL;DR
This paper proposes the LIMI method and shows that by using only a very small number of carefully curated, high-quality training samples—just 78 in total—it is possible to train powerful AIagent that outperform models trained on massive amounts of data in intelligent agent tasks, thereby establishing the “less is more” principle for intelligent agent development.
Key Definitions
The paper introduces or adopts the following concepts, which are essential for understanding its core contributions:
-
Agency: In this paper, this is defined as the emergent ability of an AI system to operate as an autonomous intelligent agent—proactively discovering problems, forming hypotheses, and executing solutions through self-directed interaction with the environment and tools. This marks a paradigm shift in AI from a passive assistant to an active intelligent agent.
-
Query ($q_i$): Refers to the initial instruction initiated by the user, describing the task objective in natural language. It is the starting point of the entire intelligent agent interaction process and sets the goals and success criteria for the subsequent collaborative workflow.
-
Trajectory ($\tau_i$): Refers to the complete, multi-turn interaction sequence generated in response to query $q_i$, formalized as $\tau_i={a_{i,1},\ldots,a_{i,n_i}}$. It includes all steps such as the model’s reasoning process ($m_{i,j}$), tool calls ($t_{i,j}$), and environment feedback ($o_{i,j}$), fully recording the entire collaborative workflow from task understanding to successful resolution.
-
Agency Efficiency Principle: The core conclusion drawn experimentally in this paper: machine autonomy does not come from massive amounts of data, but from the strategic distillation of high-quality examples of intelligent agent behavior.
Related Work
At present, research on Agentic Language Models has evolved from early methods such as Toolformer and ReAct to advanced foundation models like GLM-4.5 and Kimi-K2, which are specifically designed for agency capabilities. These models demonstrate strong reasoning, coding, and tool-use abilities.
However, mainstream approaches still largely follow traditional Scaling Laws, assuming that “more data equals stronger agency.” This has led to increasingly complex and resource-intensive training pipelines. Although studies such as LIMA and LIMO have demonstrated the effectiveness of small-scale, high-quality data in model alignment and mathematical reasoning, this “less is more” idea has not yet been validated in the more complex agency domain.
The core question this paper aims to address is: Can AI agency be developed more efficiently, rather than relying on large-scale data? The authors challenge the widespread dependence on data scale in current intelligent agent development and explore whether strategic data distillation is more important than data volume itself.
Method
The core methodology of LIMI (Less is More for Intelligent Agency) shows that strong agency can be efficiently cultivated by focusing on a small number of high-quality examples that reflect complex intelligent agent behavior. Its innovations are mainly reflected in the following aspects:
Innovations
-
A novel method for synthesizing intelligent agent user queries: To ensure the authenticity and representativeness of the training data, the paper designs a dual-track query collection strategy. On the one hand, it collects real-world task queries from professional developers and researchers through human-AI collaboration; on the other hand, it uses an advanced LLM (GPT-5) to systematically synthesize queries from high-quality GitHub Pull Requests, ensuring that the training tasks are both realistic and sufficiently diverse.
-
A systematic trajectory collection protocol: For each selected query, the paper develops a strict trajectory collection process. This process is carried out in the \(SII CLI\) environment, which supports complex tool interactions, and tasks are completed through collaboration between human experts and the AI intelligent agent (GPT-5). The entire process—from task understanding, model reasoning, and tool use to environment feedback and successful task completion—is recorded as a complete multi-turn interaction sequence, forming high-quality examples of intelligent agent behavior.
-
Revealing the efficiency principle of intelligent agent development: Through experiments, the paper demonstrates that the emergence of agency follows the “less is more” principle. The key lies in the “quality” of the data rather than the “quantity.” By strategically focusing on two core knowledge-work domains—Vibe Coding and Research Workflows—the paper shows that an extremely small number of demonstrations (only 78), yet containing complex collaboration, planning, and execution processes, is sufficient to cultivate an intelligent agent that outperforms one trained on large-scale data.
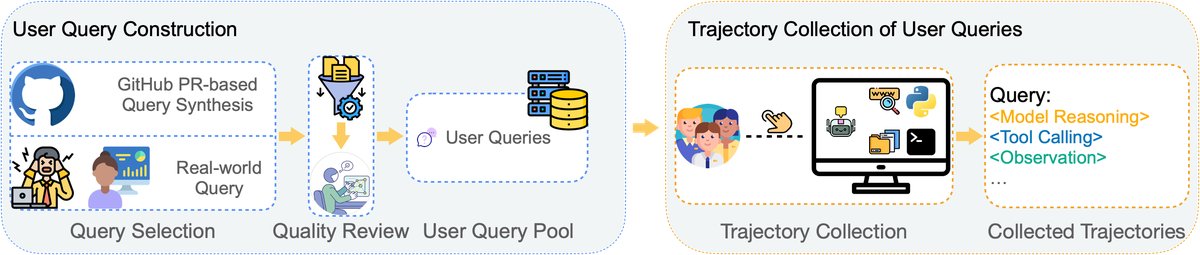
Dataset Construction Process
The foundation of LIMI lies in its strategic dataset construction process, which aims to capture the essence of agency with minimal data.
Query Pool Construction
The paper first builds a query pool containing 78 high-quality queries, $\mathcal{Q}={q_1, q_2, \ldots, q_{78}}$. These queries come from two sources:
- Collection of real-world queries: 60 real tasks from the daily work of developers and researchers were collected, ensuring task complexity and ecological validity.
- GitHub PR synthesis: To broaden coverage, the paper designs a process that uses GPT-5 to synthesize new queries from PRs in top GitHub projects (with more than 10,000 stars). Through multi-stage filtering (repository screening, PR screening, expert annotation review), the authenticity and high quality of the synthesized queries were ensured. In the end, 18 queries that best matched the definitions of Vibe Coding and Research Workflows were selected.
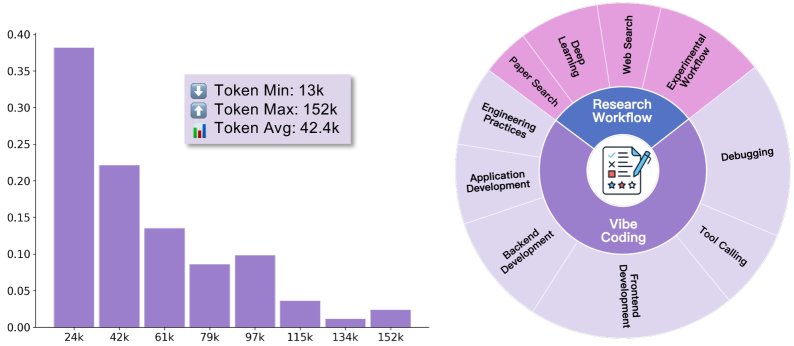
As shown in the figure, these data cover the two major domains of Vibe Coding and Research Workflows, and the trajectory lengths are widely distributed (average 42.4k tokens), reflecting the complexity of the tasks.
Training Trajectory Collection
After building the query pool, the authors collected trajectory data in the \(SII CLI\) environment. This environment integrates a rich set of development and research tools, supporting complex human-AI collaboration. The collection process was carried out by four computer science PhD students acting as “human collaborators,” who worked together with the GPT-5 model to solve these 78 tasks. They iterated continuously until each task was successfully completed, and recorded the complete interaction trajectories $\tau_i$. These trajectories include all details of the model’s reasoning, tool calls, environment observations, and human feedback, providing the model with a perfect example for learning complex problem-solving strategies. The longest trajectory reached 152k tokens, indicating the depth of the collaborative process it captured.
Experimental Conclusions
The experiments were conducted around \(AgencyBench\) and a series of general-purpose benchmarks, aiming to verify the effectiveness, data efficiency, and generalization ability of the LIMI method.

Core Results
1. Outstanding performance on AgencyBench: As shown in the table below, the LIMI model trained on only 78 samples achieved an average score of 73.5% on AgencyBench, significantly outperforming all baseline models, such as GLM-4.5 (45.1%), Kimi-K2-Instruct (24.1%), and Qwen3-235B-A22B-Instruct (27.5%). This demonstrates the effectiveness of the LIMI method and establishes a new SOTA.
| Model Group | Model | FTFC (%) | SCR (%) | RR (%) | Average (%) | Number of Samples | Dataset |
|---|---|---|---|---|---|---|---|
| Baseline SOTA Models | Kimi-K2-Instruct | 20.3 | 28.0 | 24.1 | 24.1 | N/A | Proprietary |
| DeepSeek-V3.1 | 10.9 | 12.8 | 12.0 | 11.9 | N/A | Proprietary | |
| Qwen3-235B… | 28.5 | 24.3 | 29.8 | 27.5 | N/A | Proprietary | |
| GLM-4.5 | 37.8 | 47.4 | 50.0 | 45.1 | N/A | Proprietary | |
| Data Efficiency Comparison | GLM-4.5-CC | 46.1 | 42.6 | 45.2 | 44.6 | 260 | CC-Bench |
| GLM-4.5-Web | 47.8 | 45.7 | 45.6 | 46.4 | 7,610 | AFM-WebAgent | |
| GLM-4.5-Code | 49.3 | 47.4 | 46.8 | 47.8 | 10,000 | AFM-CodeAgent | |
| Our Method | LIMI (GLM-4.5) | 71.7 | 74.6 | 74.3 | 73.5 | 78 | LIMI (this paper) |
| Model Scale Generalization | GLM-4.5-Air | 11.8 | 19.4 | 19.8 | 17.0 | N/A | Proprietary |
| LIMI-Air (GLM-4.5-Air) | 30.4 | 36.8 | 35.7 | 34.3 | 78 | LIMI (this paper) |
2. Astonishing Data Efficiency: The most striking conclusion from LIMI is its extremely high data efficiency. Compared with GLM-4.5-Code (47.8%), which was trained on the \(AFM-CodeAgent\) dataset containing 10,000 samples, LIMI (73.5%) achieved a massive 53.7% performance gain using 128 times less data. This strongly supports the core hypothesis that “less is more”: carefully curated, high-quality data is far more effective than large-scale, low-density data.
3. Broad Generalization Ability: Across multiple general-purpose benchmarks such as tool use (tau2-bench), code generation (EvalPlus), and scientific computing (SciCode), LIMI also performed exceptionally well, with an average score of 57.2%, surpassing all baseline models. This suggests that LIMI learned not just task-specific solutions, but general reasoning, planning, and tool-use capabilities.
| Model | TAU2-Air | TAU2-Ret | HE | MP | DS-1000 | SP | Average |
|---|---|---|---|---|---|---|---|
| Kimi-K2-Instruct | 20.3 | 44.0 | 88.4 | 76.5 | 32.2 | 2.5 | 37.3 |
| DeepSeek-V3.1 | 22.0 | 33.3 | 88.4 | 77.3 | 20.4 | 0.0 | 29.7 |
| Qwen3-235B… | 30.5 | 40.5 | 87.8 | 79.5 | 31.8 | 0.0 | 36.7 |
| GLM-4.5 | 32.5 | 38.0 | 89.0 | 81.1 | 37.5 | 0.0 | 43.0 |
| LIMI | 34.0 | 45.6 | 92.1 | 82.3 | 45.6 | 3.8 | 57.2 |
4. Impact of the Execution Environment: Through comparative evaluation with and without the \(SII CLI\) tool environment, the experiments found:
- Even without a tool environment, LIMI (50.0%) still outperformed the baseline model GLM-4.5 (48.7%), proving that its training method improves the model’s intrinsic core capabilities.
- When the \(SII CLI\) tool environment was provided, LIMI’s performance improved from 50.0% to 57.2%, showing that the model can effectively leverage tools to fully realize its agentic potential. This validates the synergy between intrinsic capability gains and environment empowerment.
Summary
The findings of this paper establish the Agent Efficiency Principle: the autonomous capabilities of AI agents do not come from accumulating more data, but from strategically distilling examples that capture high-quality, complex collaboration processes. With only 78 carefully designed samples, the LIMI method achieves performance that surpasses SOTA models trained on thousands or even tens of thousands of samples. This finding fundamentally challenges the scale-dependent paradigm that is common in agentic AI development, and points to a new, more sustainable path for building more efficient and more powerful autonomous AI systems in the future.