Let's Verify Step by Step
-
ArXiv URL: http://arxiv.org/abs/2305.20050v1
-
Authors: Teddy Lee; Harrison Edwards; Hunter Lightman; I. Sutskever; Yura Burda; K. Cobbe; Jan Leike; John Schulman; Bowen Baker; Vineet Kosaraju
-
Publishing Organization: OpenAI
TL;DR
This article demonstrates through experiments on the highly challenging MATH math dataset that Process Supervision significantly outperforms Outcome Supervision in training reward models, and the resulting model can more reliably solve complex multi-step reasoning problems.
Key Definitions
- Outcome Supervision (ORM): A method for training reward models that provides feedback only based on the final result of the model-generated chain of solution steps, whether correct or incorrect.
- Process Supervision (PRM): Another method for training reward models that provides feedback on every intermediate step in the solution chain (for example, marking whether each step is correct).
- PRM800K: A large-scale dataset released in this paper, containing 800,000 step-by-step feedback labels from human annotations of model-generated math solution steps, used to train process-supervised reward models.
- Active Learning: During data collection, instead of randomly selecting samples for annotators to label, samples are strategically chosen that are most likely to “confuse” the current best reward model (that is, solutions that the model rates highly but whose final answers are wrong), in order to improve labeling efficiency.
Related Work
Although current large language models can generate multi-step reasoning processes through “chain of thought” and similar methods, they still frequently produce logical errors or “hallucination.” Training a reward model to distinguish good and bad outputs to guide model generation or search is an effective way to improve reliability.
Previous work (Uesato et al., 2022) compared outcome supervision and process supervision, but found that their final performance was similar on relatively simple math tasks. This left several key questions unanswered: on more complex tasks, which supervision method is better? How can expensive human feedback be used more efficiently?
This paper aims to address these questions by conducting a more detailed, large-scale comparison of the two supervision methods using stronger base models, more feedback data, and the more challenging MATH dataset.
Method
The core of this paper is a comparison of two methods for training reward models: outcome supervision (ORM) and process supervision (PRM). The evaluation criterion is which reward model can better select the correct solution from N candidate solutions generated by a generator model (Best-of-N).
Method Overview
This study does not involve using reinforcement learning (RL) to optimize the generator model itself, but instead focuses on how to train the most reliable reward model. The experiments are divided into two scales:
- Large-scale: Based on fine-tuning GPT-4, with the goal of training the strongest ORM and PRM to push the state of the art.
- Small-scale: To enable fairer and more controlled comparison experiments (such as ablation studies), a large-scale PRM is used as a “synthetic supervisor” to provide labels for training smaller models.
Data Collection and PRM800K
To obtain the data required for process supervision, the paper hired human annotators to label, step by step, solutions generated by models for MATH problems.
- Annotation Interface: Annotators assigned each step a “positive” label (correct and reasonable), “negative” (incorrect or unreasonable), or “neutral” (ambiguous).
 Figure 1: Screenshot of the interface used to collect feedback on each solution step.
Figure 1: Screenshot of the interface used to collect feedback on each solution step.
- Active Learning Strategy: To maximize the value of human annotation, the paper adopted an active learning strategy. Priority was given to “convincing wrong-answer solutions” that the current best PRM model rated highly but whose final answers were wrong. Since the model must have made a mistake on these solutions, annotating them provides the most valuable information.
- Dataset: The final PRM800K dataset contains 800,000 step-level labels.
Process-Supervised Reward Model (PRM)
- Training: The PRM is trained to predict whether the token after each solution step is correct. This prediction task can be integrated into the standard language model training pipeline.
- Scoring: When evaluating a complete solution, its PRM score is defined as the product of the probabilities that all steps are correct.
- Supervision Scope: To make the comparison with outcome supervision fairer, for incorrect solutions, process supervision provides labels only up to the first incorrect step. This aligns the amount of information used by the two methods (both only confirm that at least one error exists) and controls annotation cost.
Figure 2: Two solutions to the same problem scored by PRM. The left is correct, the right is incorrect. Green backgrounds indicate high PRM scores, and red indicates low scores. PRM successfully identifies the erroneous steps in the wrong solution.
Outcome-Supervised Reward Model (ORM)
- Training: The ORM is trained to predict whether a complete solution is correct. Its labels are usually obtained by automatically checking the final answer.
- Scoring: During evaluation, the ORM’s prediction on the final token is used as the score for the entire solution.
- Limitation: A major issue with ORM is that a model may arrive at the correct answer through an incorrect reasoning process (“false positive”), and ORM will incorrectly label it as a good solution.
Experimental Conclusions
Large-Scale Experimental Comparison
In the large-scale experiments, the PRM was trained on the PRM800K dataset, while the ORM was trained on a dataset that was an order of magnitude larger and uniformly sampled. Although the training sets were not perfectly matched, both represent best practices under their respective supervision methods.
- Main Result: As shown in Figure 3, PRM’s performance is significantly better than ORM and the Majority Voting baseline across all sample sizes (N). Moreover, as N increases, PRM’s advantage becomes even more pronounced, indicating that PRM is better at searching among a large number of candidate solutions.
- SOTA Performance: Ultimately, the PRM model in this paper solved 78.2% of the problems on a representative MATH test subset.
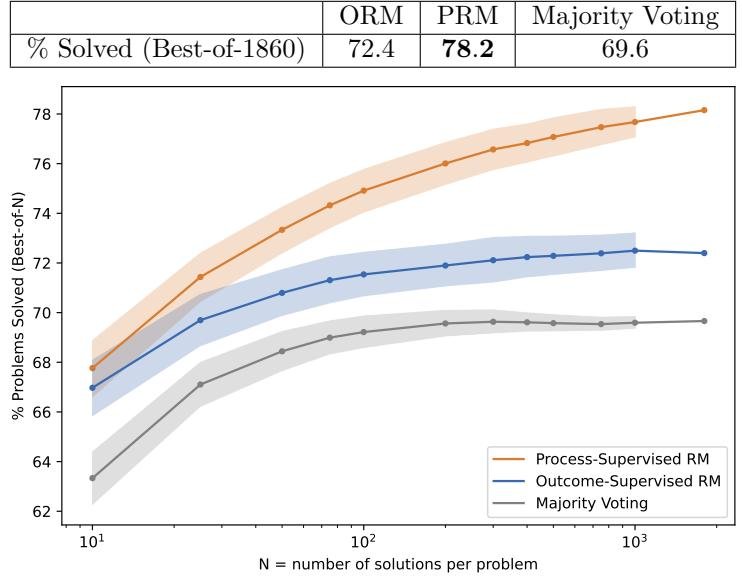 Figure 3: Performance comparison of different reward models on best-of-N selection. PRM (blue) significantly outperforms ORM (green) and Majority Voting (red).
Figure 3: Performance comparison of different reward models on best-of-N selection. PRM (blue) significantly outperforms ORM (green) and Majority Voting (red).
Small-Scale Synthetic Supervision Experiments
To conduct stricter controlled experiments, the paper used the trained large-scale PRM (called \(PRMlarge\)) as the annotator to simulate human feedback.
- Process vs. Outcome Supervision: As shown in Figure 4a, across all data sizes, process supervision far outperforms both forms of outcome supervision (one based on final-answer checking and the other based on the overall judgment of \(PRMlarge\)). This demonstrates the inherent advantage of process supervision.
- Active Learning Effect: As shown by the dashed line in Figure 4a, the data efficiency of the active learning strategy is 2.6 times that of uniform sampling. This means that to reach the same performance, active learning requires far less data.
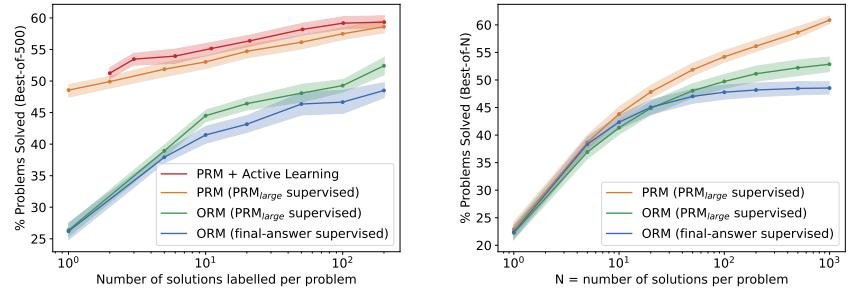 Figure 4: Comparison of different forms of supervision. (a) shows how performance changes as the amount of data increases; process supervision (blue) has a clear advantage, while active learning (purple dashed line) is more efficient. (b) shows the best-of-N performance of each method under different N values.
Figure 4: Comparison of different forms of supervision. (a) shows how performance changes as the amount of data increases; process supervision (blue) has a clear advantage, while active learning (purple dashed line) is more efficient. (b) shows the best-of-N performance of each method under different N values.
Out-of-Distribution Generalization (OOD)
We tested on entirely new STEM competition problems the model had never seen before (such as AP Physics, Calculus, AMC10/12, etc.), with results shown in the table below.
- Results: PRM still consistently outperforms ORM and majority voting, demonstrating its strong generalization ability; its advantage is not limited to the MATH dataset.
| Domain | ORM | PRM | Majority Voting | # Problems |
|---|---|---|---|---|
| AP Calculus | 68.9% | 86.7% | 80.0% | 45 |
| AP Chemistry | 68.9% | 80.0% | 71.7% | 60 |
| AP Physics | 77.8% | 86.7% | 82.2% | 45 |
| AMC10/12 | 49.1% | 53.2% | 32.8% | 84 |
| Total | 63.8% | 72.9% | 61.3% | 234 |
Key Conclusions
- Process supervision is better: By providing more precise feedback, process supervision significantly simplifies the model’s credit assignment problem, enabling it to train a more reliable reward model than outcome supervision.
- Negative “alignment tax”: Process supervision is not only more effective, but also inherently safer and more interpretable, because it directly rewards reasoning processes that humans approve of rather than just an outcome. This means that adopting a safer alignment method (process supervision) actually brings performance gains, which the authors call a “negative alignment tax.”
- Active learning works: Active learning can significantly improve data annotation efficiency and is a key technique for reducing the cost of applying process supervision.