Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
-
ArXiv URL: http://arxiv.org/abs/2304.13705v1
-
Authors: Tony Zhao; Chelsea Finn; Vikash Kumar; S. Levine
-
Publishing Institutions: Meta; Stanford University; University of California, Berkeley
TL;DR
This paper proposes a low-cost open-source bimanual teleoperation hardware system called ALOHA, and combines it with a novel imitation learning algorithm called ACT. By predicting action sequences (Action Chunking) rather than single-step actions, it successfully enables low-cost robots to learn a variety of fine manipulation tasks that previously required expensive equipment.
Key Definitions
- ALOHA (A Low-cost Open-source Hardware System for Bimanual Teleoperation): A low-cost (<$20k) bimanual teleoperation hardware system built by the authors. It uses off-the-shelf robot arms (ViperX and WidowX) and 3D-printed components, allowing an operator to intuitively control the robot through joint-space mapping to collect high-quality, high-frequency fine manipulation demonstration data.
- Action Chunking: The core algorithmic idea proposed in this paper. Traditional methods predict one action at a time, whereas action chunking means the policy model predicts a sequence of actions for the next \(k\) time steps at once. This shortens the effective time horizon of the task by a factor of \(k\), significantly alleviating the “compounding errors” problem in imitation learning.
- Temporal Ensembling: A technique used during inference to smooth robot actions. The system queries the policy model at every time step rather than every \(k\) steps, producing overlapping action chunks. For any given time step, the system aggregates (via weighted averaging) the action commands for that time step from different predictions, making the final executed action smoother and more coherent.
- ACT (Action Chunking with Transformers): The full name of the imitation learning algorithm proposed in this paper. The algorithm uses a Transformer architecture to implement action chunking and is trained with a conditional variational autoencoder (Conditional VAE, CVAE) to effectively model the inherent multimodality and noise in human demonstration data.
Related Work
At present, fine manipulation tasks (such as threading a needle or inserting batteries) usually rely on expensive, highly precise high-end robots and sensors. Although imitation learning makes it possible to use low-cost hardware, it has a fatal weakness: compounding errors. Small errors produced by the policy during execution accumulate over time, causing the robot to enter unfamiliar states never seen in the training data, ultimately leading to task failure. This problem is especially severe in fine manipulation tasks that require high precision.
Existing methods for mitigating compounding errors either require cumbersome online expert intervention (such as DAgger) or are limited to low-dimensional state spaces, making them unsuitable for scenarios that learn directly from high-dimensional pixels (images).
Therefore, the core question this paper aims to solve is: How can low-cost, low-precision robot hardware successfully perform complex bimanual manipulation tasks that require high precision and closed-loop feedback by learning directly from images?
Method
The contributions of this paper consist of two synergistic parts: a low-cost teleoperation hardware system, ALOHA, for data collection, and an innovative learning algorithm, ACT.
ALOHA: Low-cost Teleoperation Hardware System
To obtain high-quality fine manipulation demonstration data, the paper designed and built the ALOHA system.
- Design principles: Low cost, versatile functionality, user-friendly, and easy to repair and assemble.
- Hardware composition: The system consists of two pairs of robot arms: a larger pair of ViperX 6-DoF arms serving as the “follower,” and a smaller pair of WidowX arms of the same brand serving as the “leader.” The operator controls the follower by directly backdriving the leader arms, and the two are connected through joint-space mapping, avoiding the issue of inverse kinematics (IK) failing near singularities.
- Innovative design: To improve the teleoperation experience, the authors designed a 3D-printed “handle-and-scissors” mechanism that makes it easier for the operator to control gripper opening/closing and arm movement. They also designed a rubber-band gravity compensation device to reduce the operator’s burden.
- Perception system: The system is equipped with four consumer-grade webcams: two mounted on the robot wrists to provide close-up views, and two others providing global front and top views.
 Figure 1: The ALOHA system, where the user teleoperates the follower arm by driving the leader arm. The system can perform tasks requiring precise, dynamic, and rich contact, such as threading a zipper pull and playing table tennis.
Figure 1: The ALOHA system, where the user teleoperates the follower arm by driving the leader arm. The system can perform tasks requiring precise, dynamic, and rich contact, such as threading a zipper pull and playing table tennis.
 Figure 3: Multiple camera views of ALOHA, a schematic of the workspace, and the custom gripper and “handle-scissors” control device.
Figure 3: Multiple camera views of ALOHA, a schematic of the workspace, and the custom gripper and “handle-scissors” control device.
ACT: Transformer-based Action Chunking Algorithm
To address the compounding errors problem, this paper proposes the ACT algorithm, whose core idea is to learn a policy that generates action sequences.
Innovations
-
Action Chunking: The core innovation of the algorithm. The policy $\pi_{\theta}(a_{t:t+k} \mid s_t)$ no longer predicts a single action $a_t$ from the current state $s_t$, but instead predicts the entire action sequence $a_{t:t+k}$ for the next \(k\) time steps. This is equivalent to reducing the task’s decision frequency by a factor of \(k\), significantly reducing the chance of compounding errors. In addition, it can better handle the non-Markovian behaviors common in human demonstrations, such as temporary pauses.
-
Temporal Ensembling: To avoid action stuttering caused by making decisions only every \(k\) steps, ACT runs the policy at every time step to generate overlapping action chunks. For the action at the current time step \(t\), there may be multiple candidate actions from past predictions. ACT fuses these actions into a single command through weighted averaging (with newer predictions given higher weight), thereby producing smooth and responsive trajectories.
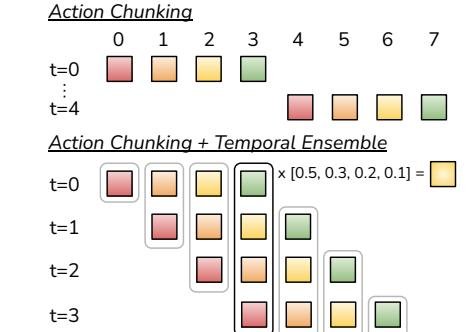 Figure 5: During inference, ACT uses action chunking and temporal ensembling. Rather than alternating between “observe” and “act,” it makes predictions at every time step and performs weighted averaging over overlapping action chunks.
Figure 5: During inference, ACT uses action chunking and temporal ensembling. Rather than alternating between “observe” and “act,” it makes predictions at every time step and performs weighted averaging over overlapping action chunks.
- Using CVAE to model human data: Human demonstrations are inherently noisy and multimodal (there may be multiple valid actions for the same state). To address this, ACT is modeled as a conditional variational autoencoder (CVAE).
- Architecture: The model includes a CVAE encoder and a CVAE decoder (i.e., the policy itself), both implemented with Transformers.
- Training: During training, the encoder compresses the observations and ground-truth action sequence into a latent variable $z$ (representing the action “style”), while the decoder (policy) learns to reconstruct the action sequence from the observations and $z$. The loss function includes a reconstruction loss (L1 loss) and a KL-divergence regularization term.
- Inference: During inference, the encoder is discarded and the latent variable $z$ is fixed to the mean of the prior distribution (i.e., 0), enabling the policy to produce deterministic, high-quality action sequences.
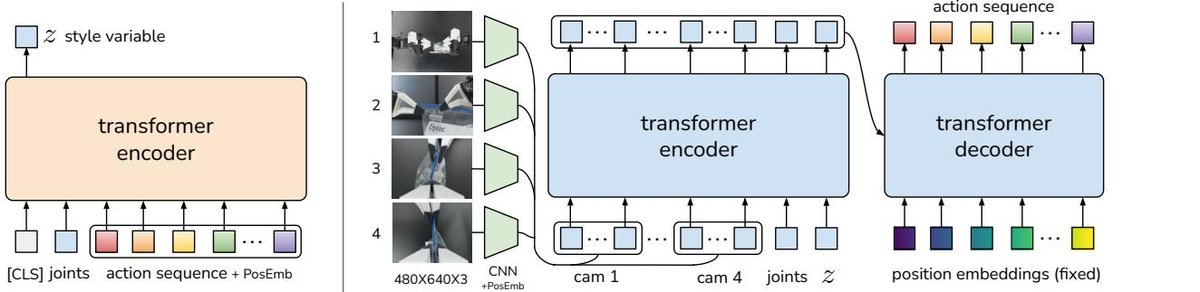 Figure 4: ACT architecture diagram. On the left is the CVAE encoder, used only during training, which compresses the action sequence and joint states into the latent variable z. On the right is the CVAE decoder (i.e., the policy), which fuses multi-view images, joint states, and the latent variable z, and uses a Transformer encoder-decoder to predict an action sequence.
Figure 4: ACT architecture diagram. On the left is the CVAE encoder, used only during training, which compresses the action sequence and joint states into the latent variable z. On the right is the CVAE decoder (i.e., the policy), which fuses multi-view images, joint states, and the latent variable z, and uses a Transformer encoder-decoder to predict an action sequence.
Summary of the algorithm flow
- Training (Algorithm 1): Sample observation $o_t$ and the corresponding future \(k\)-step action sequence $a_{t:t+k}$ from the demonstration dataset $\mathcal{D}$. Train the policy network $\pi_{\theta}$ and encoder $q_{\phi}$ through the CVAE framework.
- Inference (Algorithm 2): At each time step \(t\), obtain the current observation $o_t$, set the latent variable $z=0$, and call the policy $\pi_{\theta}(\hat{a}_{t:t+k} \mid o_t, z)$ to predict the next \(k\) actions. Store these predicted actions in a buffer, and compute the final current action to execute through temporal ensembling.
Experimental conclusions
This paper evaluated ACT on 2 simulated tasks and 6 real-world fine manipulation tasks, such as opening a zip bag, installing a battery, opening a seasoning cup, and threading a Velcro strap.
| Task (data source) | BC-ConvMLP | BeT | RT-1 | VINN | ACT (this paper) |
|---|---|---|---|---|---|
| Block transfer (simulation, script) | 34 | 60 | 44 | 13 | 97 |
| Block transfer (simulation, human) | 3 | 16 | 4 | 17 | 82 |
| Bimanual insertion (simulation, script) | 17 | 51 | 33 | 9 | 90 |
| Bimanual insertion (simulation, human) | 1 | 13 | 2 | 11 | 60 |
| Open zip bag (real world) | 5 | 27 | 28 | 3 | 88 |
| Install battery (real world) | 0 | 1 | 20 | 0 | 96 |
Table I: Comparison of success rates (%) on 4 tasks. ACT significantly outperforms previous methods across all tasks and data types.
| Task (real world) | Tip Over | Open Lid | — | Total | |
|---|---|---|---|---|---|
| BeT | 12 | 0 | — | 0 | |
| ACT (this paper) | 100 | 84 | — | 84 | |
| Task (real world) | Lift | Grasp | Insert | Total | |
| BeT | 0 | 0 | 0 | 0 | |
| ACT (this paper) | 96 | 92 | 20 | 20 | |
| Task (real world) | Grasp | Cut | Handover | Hang | Total |
| BeT | 24 | 0 | 0 | 0 | 0 |
| ACT (this paper) | 96 | 72 | 100 | 64 | 64 |
| Task (real world) | Lift | Insert | Support | Secure | Total |
| BeT | 8 | 0 | 0 | 0 | 0 |
| ACT (this paper) | 100 | 92 | 92 | 92 | 92 |
Table II: Comparison of subtasks and final success rates (%) for 4 additional real-world tasks. ACT performs excellently, while the best baseline, BeT, achieves a success rate of 0 on these complex tasks.
- Verified advantages:
- Effectiveness: The experimental results show that ACT surpasses all baseline methods (including BC-ConvMLP, BeT, RT-1, and VINN) by a large margin on all 8 tasks (for example, a 96% success rate on the battery installation task, while other methods are close to 0). This demonstrates that the proposed system and algorithm can effectively learn and complete fine manipulation on low-cost hardware.
- The importance of action chunking: Ablation experiments confirm that action chunking is key to performance gains. As the chunk size \(k\) increases, the performance of all methods improves significantly. This shows that action chunking is a universal and effective technique for mitigating error accumulation.
- The necessity of CVAE: Experiments show that when training with more stochastic human demonstration data, the CVAE objective is crucial; if CVAE is removed, model performance drops sharply from 35.3% to 2%.
- The necessity of high-frequency control: User studies show that 50Hz high-frequency teleoperation control reduces task completion time by an average of 62% compared with 5Hz low-frequency control, demonstrating the importance of high-frequency feedback for fine manipulation.
-
Scenarios with poor performance: In the “Thread Velcro” task, ACT’s final success rate was low (20%). The main reason for failure was perception challenges: the black Velcro strap had low contrast against the black background, and the target occupied only a small portion of the image, making it difficult for the system to localize accurately, which led to failures during aerial grasping or alignment for insertion.
- Final conclusion: This paper successfully demonstrates that by combining carefully designed low-cost teleoperation hardware (ALOHA) with an innovative imitation learning algorithm (ACT), inexpensive robotic systems can acquire fine manipulation skills that previously only high-end equipment could accomplish, with very high requirements for precision and closed-loop feedback. Its core algorithmic innovation, “action chunking,” provides a powerful solution to the error accumulation problem in imitation learning.