KTO: Model Alignment as Prospect Theoretic Optimization
-
ArXiv URL: http://arxiv.org/abs/2402.01306v4
-
Authors: Kawin Ethayarajh; Douwe Kiela; Winnie Xu; Dan Jurafsky; Niklas Muennighoff
-
Publisher: Contextual AI; Stanford University
TL;DR
This paper proposes a new large-model alignment method called KTO (Kahneman-Tversky Optimization). Based on prospect theory, it can achieve performance on models ranging from 1 billion to 30 billion parameters that matches or even surpasses DPO, which relies on preference data, using only binary feedback signals of “desirable” or “undesirable.”
Key Definitions
This paper introduces several core concepts to re-examine and construct model alignment methods from the perspective of cognitive science (prospect theory):
- Prospect Theory: A cognitive science theory that describes how humans make decisions under uncertainty. Its core idea is that human perception of value is relative (based on a reference point) and that people are more sensitive to losses than to gains of the same magnitude (loss aversion).
- Human-Aware Losses (HALOs): A family of loss functions proposed in this paper. They model the model alignment problem as maximizing human subjective value. These loss functions are characterized by a value function $v$ applied to the difference between the “implied reward” of the model and a “reference point,” thereby simulating human cognitive biases such as loss aversion and risk aversion.
- Implied Reward: Defined as $r_{\theta}(x,y) = \beta \log[\pi_{\theta}(y \mid x)/\pi_{\text{ref}}(y \mid x)]$. It measures the log-probability gain of generating a specific output $y$ when moving from the reference model $\pi_{\text{ref}}$ to the current model $\pi_{\theta}$, and can be understood as how “good” the model thinks the output is.
- KTO (Kahneman-Tversky Optimization): The core alignment method proposed in this paper. It is a HALO whose loss function is directly derived from Kahneman and Tversky’s value function model. Unlike DPO, which maximizes the log-likelihood of preference data, KTO aims to directly maximize the (prospect-theoretic) utility of generated outputs, and it requires only binary feedback on whether a single output is “desirable” or “undesirable.”
Related Work
At present, the mainstream approach to aligning large language models (LLMs) is reinforcement learning from human feedback (RLHF). RLHF is usually a two-step process: first, train a reward model to fit human preference data (for example, output $y_w$ is preferred over $y_l$); then use reinforcement learning algorithms such as PPO to optimize the language model so that it maximizes reward while not drifting too far from the original SFT model (via a KL-divergence penalty).
However, the RLHF pipeline is complex and training is unstable. Direct Preference Optimization (DPO) emerged as a simpler and more stable alternative. Through a clever derivation, DPO turns the RLHF objective into a simple classification loss that can be optimized directly on preference data, avoiding explicit reward modeling and complex RL training.
The key problem this paper aims to solve is: the most effective alignment methods today, such as RLHF and DPO, rely heavily on paired preference data ($(x, y_w, y_l)$), and such data is costly, slow to collect, and scarce in the real world. This paper explores whether preference data is truly necessary, and seeks to develop an efficient alignment method that depends only on more easily obtained binary feedback signals—that is, judging whether a single output is “good” or “bad.”
Method
Prospect-Theory Perspective and HALOs
The paper first provides a new explanation for the success of existing alignment methods from the perspective of prospect theory in cognitive science. Prospect theory suggests that human perception of value is not linear, but instead exhibits reference dependence, loss aversion, and risk attitude.
The authors find that successful alignment methods such as DPO and PPO-Clip implicitly reflect these human cognitive biases in the mathematical form of their loss functions. For example, they both contain a nonlinear value function, and the penalty slope for negative rewards (losses) differs from that for positive rewards (gains).
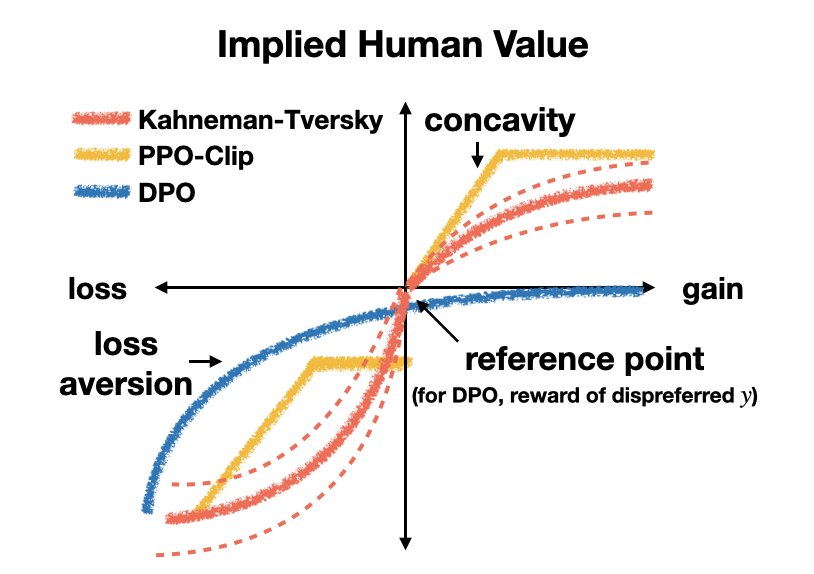 Figure 1: The utility functions that different Human-Aware Losses (HALOs) implicitly assign to humans when outcomes are random variables. Note that these implicit value functions share characteristics such as “loss aversion” with the typical human value function in prospect theory.
Figure 1: The utility functions that different Human-Aware Losses (HALOs) implicitly assign to humans when outcomes are random variables. Note that these implicit value functions share characteristics such as “loss aversion” with the typical human value function in prospect theory.
Based on this insight, the paper formally defines the concept of Human-Aware Losses (HALOs). A loss function is a HALO if it can be expressed as the expectation of some value function $v$, where $v$ acts on the difference between the “implied reward” and a “reference point.”
\[f(\pi\_{\theta},\pi\_{\text{ref}}) = \mathbb{E}\_{x,y\sim\mathcal{D}}[a\_{x,y}v(r\_{\theta}(x,y)-\mathbb{E}\_{Q}[r\_{\theta}(x,y^{\prime})])]+C\_{\mathcal{D}}\]The authors prove that both DPO and PPO-Clip belong to HALOs. Experiments also provide preliminary evidence that HALO methods (DPO and an offline PPO variant) generally outperform non-HALO methods (such as CSFT and SLiC), especially on large models, indicating that the design of the loss function itself—its embedded inductive bias—is crucial for alignment performance.
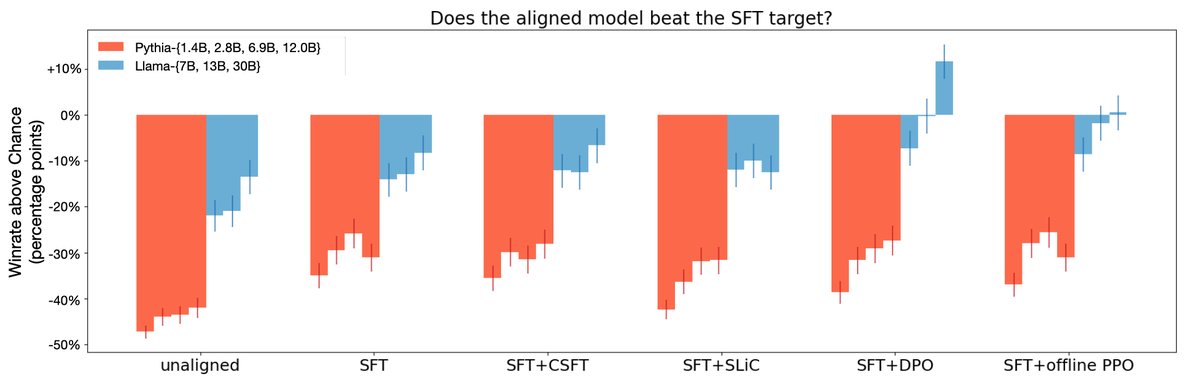 Figure 2: HALOs (DPO, offline PPO variant) achieve a higher win rate than non-HALOs (SLiC, CSFT) in GPT-4 evaluation.
Figure 2: HALOs (DPO, offline PPO variant) achieve a higher win rate than non-HALOs (SLiC, CSFT) in GPT-4 evaluation.
KTO: Derivation and Innovation
Innovation
Traditional methods such as DPO indirectly optimize the model by maximizing the log-likelihood of preference pairs, whereas KTO’s core innovation is to directly maximize the expected utility of generated content. This utility function is directly inspired by prospect theory’s modeling of human value perception.
Method Details
The authors design the KTO loss function based on the classic Kahneman-Tversky value function. To improve stability and controllability, they make several modifications:
- They replace the original power function with a logistic function $\sigma$ that has a similar shape but is smoother.
- They introduce the hyperparameter $\beta$ to control the degree of risk aversion. The larger $\beta$ is, the more curved the value-function curve becomes, indicating stronger risk aversion toward gains and stronger risk-seeking tendency toward losses.
- They introduce $\lambda_D$ and $\lambda_U$ to control the weights of “desirable” and “undesirable” samples, respectively, in order to achieve an effect similar to “loss aversion” or to handle data imbalance.
The final KTO loss function is defined as:
\[L\_{\text{KTO}}(\pi\_{\theta},\pi\_{\text{ref}})=\mathbb{E}\_{x,y\sim D}[\lambda\_{y}-v(x,y)]\]The value function $v(x, y)$ takes different forms depending on whether the sample is desirable or undesirable:
\[\begin{split} r\_{\theta}(x,y)&=\log\frac{\pi\_{\theta}(y \mid x)}{\pi\_{\text{ref}}(y \mid x)} \\ z\_{0}&=\text{KL}(\pi\_{\theta}(y^{\prime} \mid x)\ \mid \pi\_{\text{ref}}(y^{\prime} \mid x)) \\ v(x,y)&=\begin{cases}\lambda\_{D}\sigma(\beta(r\_{\theta}(x,y)-z\_{0})) & \text{if }y\sim y\_{\text{desirable}} \mid x\\ \lambda\_{U}\sigma(\beta(z\_{0}-r\_{\theta}(x,y))) & \text{if }y\sim y\_{\text{undesirable}} \mid x\\ \end{cases} \end{split}\]- Reference point $z_0$: In KTO, the reference point is set to the KL divergence of the current policy $\pi_\theta$ relative to the reference policy $\pi_{\text{ref}}$. Intuitively, this represents the “effort” the current model must expend to generate an “average” output. In practice, for computational efficiency, the outputs of other samples in the same microbatch are used to obtain a biased but efficient estimate $\hat{z}_0$.
- How it works: With this design, KTO encourages the model to learn the intrinsic characteristics of desirable outputs. If the model simply and crudely increases the probability of a particular desirable sample $y$, the overall KL divergence $z_0$ will rise, offsetting the increase in $r_\theta(x,y)$ and preventing the loss from decreasing effectively. Only when the model learns the underlying patterns that distinguish “good” from “bad” can it increase the probability of good samples without significantly increasing (or even while reducing) the KL divergence, thereby truly optimizing the loss function.
Data and Hyperparameters
- Data Processing: KTO can directly use naturally occurring binary-labeled data. For existing preference datasets ($y_w \succ y_l$), $y_w$ can simply be treated as a “desirable” sample and $y_l$ as an “undesirable” sample.
- Hyperparameter Recommendations: The paper provides practical suggestions for hyperparameter settings. For example, KTO’s optimal learning rate is usually higher than DPO’s (e.g., 5e-6 vs 5e-7). The choice of $\beta$ and $\lambda$ depends on model size, whether SFT is performed, and the ratio of good to bad samples in the data.
| Model | Method | Learning Rate | $\beta$ | AlpacaEval (LC) $\uparrow$ | BBH $\uparrow$ | GSM8K (8-shot) $\uparrow$ | | — | — | — | — | — | — | — | | Llama-3 8B | SFT+KTO | 5e-6 | 0.05 | 10.59 | 65.15 | 60.20 | | Llama-3 8B | KTO | 5e-6 | 0.10 | 11.25 | 65.26 | 57.92 | | Qwen2.5 3B Instruct | SFT+KTO | 5e-6 | 0.10 | 13.01 | 32.39 | 61.11 | | Qwen2.5 3B Instruct | KTO | 5e-6 | 0.50 | 16.63 | 20.41 | 60.35 | Table 1: Recommended hyperparameter settings for aligning different models on UltraFeedback.
Experimental Conclusions
This paper validates the effectiveness of KTO through a series of experiments.
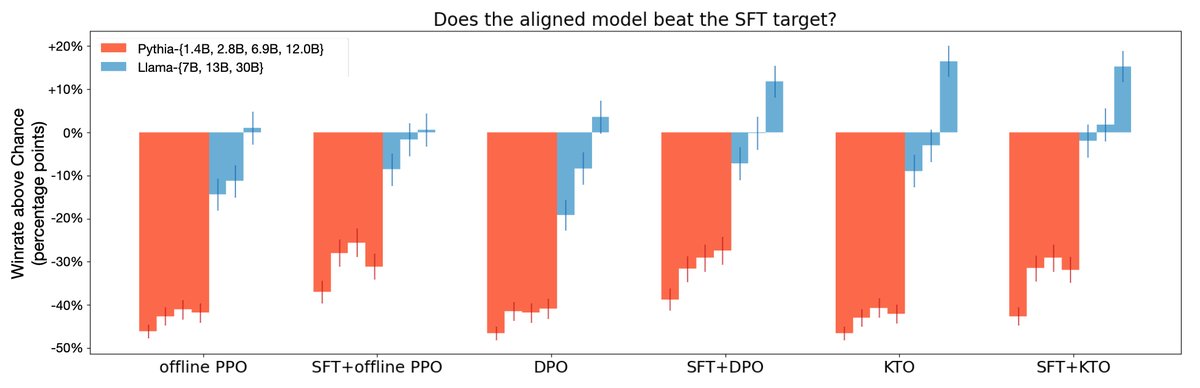 Figure 3: Win rates evaluated by GPT-4 show that KTO performs on par with or better than DPO across all model scales. For Llama-family models, KTO alone can even match SFT+DPO.
Figure 3: Win rates evaluated by GPT-4 show that KTO performs on par with or better than DPO across all model scales. For Llama-family models, KTO alone can even match SFT+DPO.
- Superior Performance: On Pythia and Llama-family models ranging from 1B to 30B parameters, after splitting preference data into binary data, SFT+KTO achieves performance comparable to or better than SFT+DPO. On tasks such as GSM8K, the gains from KTO are especially significant (see the table below).
| | | | | | | — | — | — | — | — | | Dataset ($\rightarrow$) | MMLU | GSM8k | HumanEval | BBH | | Metric ($\rightarrow$) | EM | EM | pass@1 | EM | | SFT | 57.2 | 39.0 | 30.1 | 46.3 | | DPO | 58.2 | 40.0 | 30.1 | 44.1 | | ORPO ($\lambda=0.1$) | 57.1 | 36.5 | 29.5 | 47.5 | | KTO ($\beta=0.1$, $\lambda_{D}=1$) | 58.6 | 53.5 | 30.9 | 52.6 | | KTO (one-$y$-per-$x$) | 58.0 | 50.0 | 30.7 | 49.9 | | KTO (no $z_0$) | 58.5 | 49.5 | 30.7 | 49.0 | Table 2 (partial): Benchmark results for one-round alignment of Zephyr-β-SFT on UltraFeedback. KTO shows clear advantages on GSM8k and BBH.
- SFT Can Be Skipped: For sufficiently large models (e.g., Llama-13B/30B), performing KTO alignment directly on the pretrained model can achieve performance comparable to first doing SFT and then KTO. In contrast, if DPO skips SFT, it tends to produce overly long outputs and nonsense.
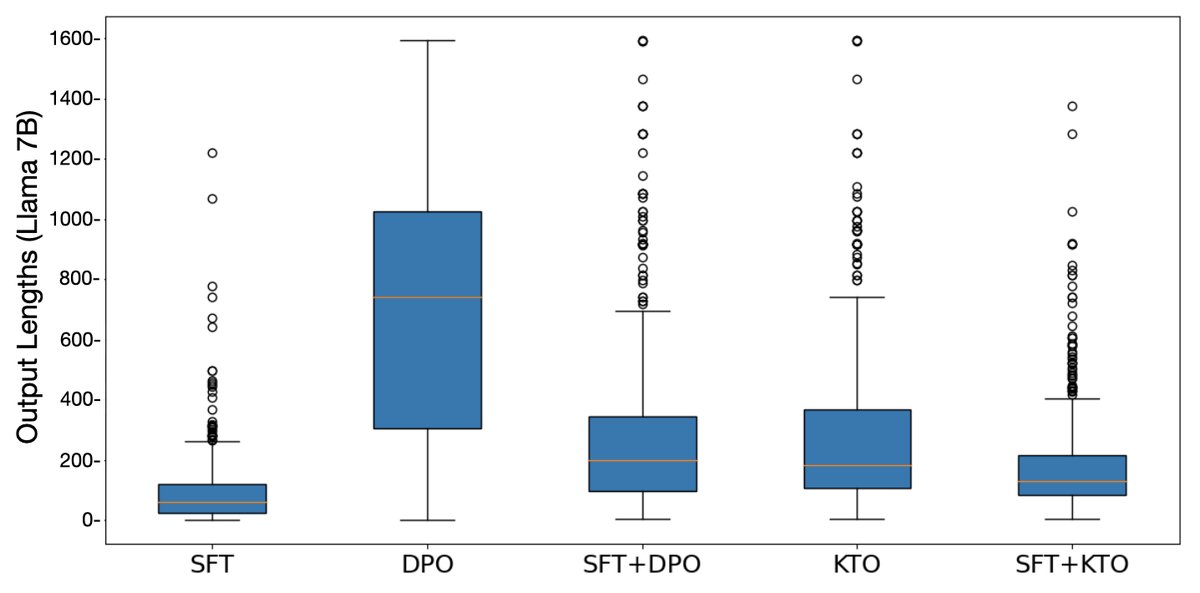 Figure 4: When aligned directly without SFT, DPO models tend to generate overly long responses, whereas KTO does not have this problem.
Figure 4: When aligned directly without SFT, DPO models tend to generate overly long responses, whereas KTO does not have this problem.
- Data Robustness: Experiments show that KTO’s strong performance is not due to “stealing” pairwise information from preference data.
- Even under extreme data imbalance (for example, dropping 90% of the desirable samples so that the good/bad sample ratio is 1:10), KTO can still outperform DPO by adjusting the $\lambda$ weight.
- On unpaired datasets with only one output per input, KTO (one-$y$-per-$x$), even with half the data, still outperforms DPO trained on the full paired dataset.
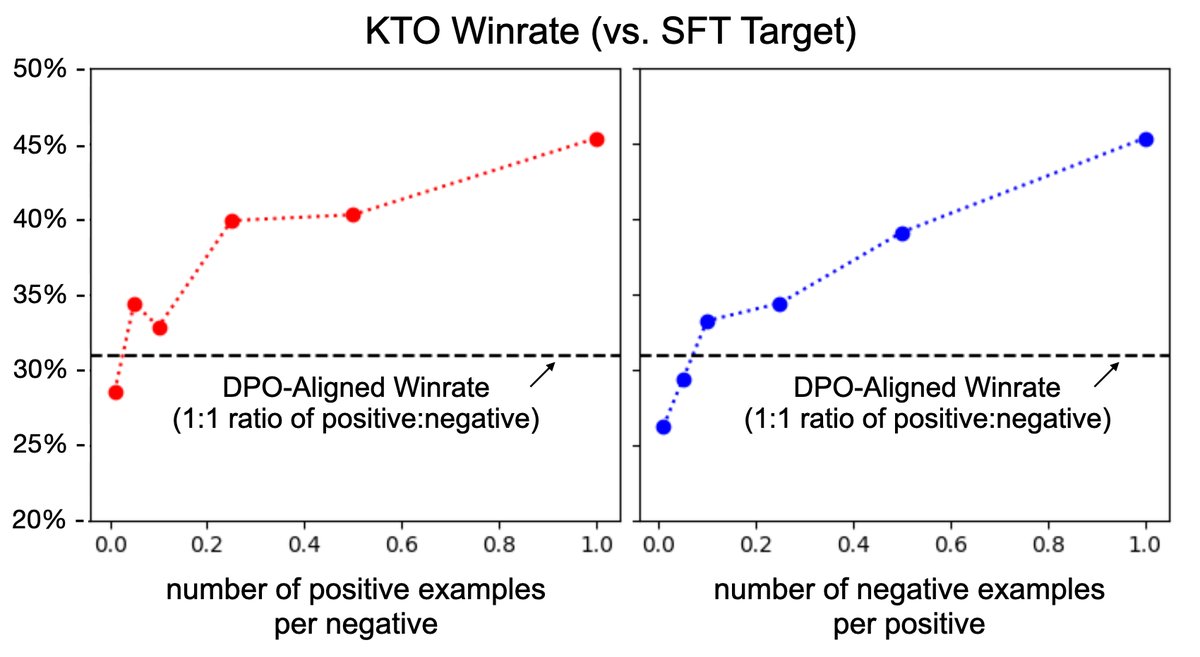 Figure 5: Even when desirable samples are extremely scarce (for example, a 1:10 good/bad ratio), the performance of a KTO-aligned Llama-7B model can still match or exceed DPO.
Figure 5: Even when desirable samples are extremely scarce (for example, a 1:10 good/bad ratio), the performance of a KTO-aligned Llama-7B model can still match or exceed DPO.
- Soundness of the Design: Ablation studies on the KTO loss show that its key design choices, such as the reference point $z_0$ and the symmetric value-function curve, are crucial to final performance. Removing these components leads to a significant drop in performance.
The final conclusion is: KTO is a highly effective and data-efficient method for aligning large models. Its success shows that drawing inspiration from cognitive science (prospect theory) to design loss functions is a fruitful direction. More broadly, there is no universal alignment loss that is optimal in all scenarios; the best choice depends on the inductive bias required by the specific task, which is a factor that should be carefully considered in model alignment.