Kling-Omni Technical Report
10-Step Reasoning for Movie-Quality Video Generation: Inside Kuaishou’s Kling-Omni All-in-One Architecture

There has long been a sense of fragmentation in video generation: some models excel at text-to-video, some specialize in video editing, and others need external tools to understand complex visual instructions. This kind of pipeline-style patchwork is not only inefficient, but also makes it harder to capture the user’s nuanced creative intent.
ArXiv URL:http://arxiv.org/abs/2512.16776v1
Kuaishou’s newly released Kling-Omni technical report is designed to put an end to this fragmentation. As an end-to-end all-in-one generation framework, Kling-Omni not only breaks down the barriers between video generation, editing, and reasoning, but also compresses the reasoning steps to an astonishing 10 through efficient distillation. It is more than just a content creation tool; it is a key step toward a “multimodal world simulator” that can perceive, reason about, and simulate the physical world.
Unified Architecture: From “Patchwork” to “Integration”
Existing video models often rely on static text encoders, making it difficult to capture complex visual details; video editing, meanwhile, usually requires separate adapters, which makes the system bloated. Kling-Omni’s core breakthrough is the proposal of a new interaction paradigm—Multimodal Visual Language (MVL).
This paradigm no longer treats text, images, and video as separate inputs, but instead builds them into a unified input representation.
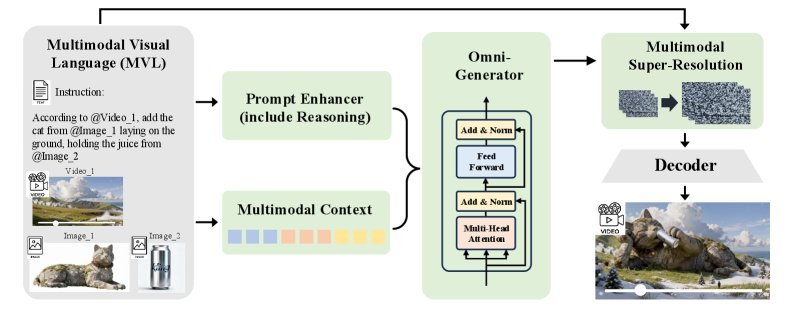
As shown above, Kling-Omni’s architecture is mainly composed of three key components:
-
Prompt Enhancer (PE): A module based on MLLM that “translates” user intent. It combines vague user instructions with world knowledge and turns them into refined prompts that the model can understand more easily.
-
Omni-Generator: The core engine. It processes visual and text tokens in a shared embedding space, enabling deep cross-modal interaction and ensuring that the generated video both follows the instructions and remains visually consistent.
-
Multimodal Super-Resolution: Used to further improve image quality by restoring high-frequency details through conditioning on the original MVL signal.
Training Strategy: From Understanding to Intuition
To give the model “all-in-one” capabilities, the research team designed a progressive multi-stage training strategy.
During pretraining, the model builds basic instruction-following ability from large-scale text-video paired data. It then enters the Supervised Fine-tuning (SFT) stage, where it is exposed to highly interleaved image, video, and text mixed data, learning to handle complex editing tasks and semantic understanding.
The most noteworthy stage is Reinforcement Learning (RL). To make the generated videos align with human aesthetics, Kling-Omni adopts Direct Preference Optimization (DPO).
Why choose DPO? Compared with the GRPO algorithm used by DeepSeekMath and others, DPO avoids expensive trajectory sampling and only requires a single diffusion forward process to complete optimization. By constructing “preference pairs” (that is, videos humans judge as better vs. worse), the model learns how to generate videos with more natural motion and more complete visuals.
Extreme Optimization: The Secret Behind 10-Step Inference
Video generation models usually face enormous compute challenges. Kling-Omni achieves a qualitative leap in inference efficiency through distillation.
The researchers developed a two-stage distillation method:
-
Trajectory Matching Distillation: Makes the student model imitate the teacher model’s generation trajectory.
-
Distribution Matching Distillation: Further optimizes generation performance.
Unlike common SDE-based distillation methods such as DMD or SiD, Kling-Omni uses ODE sampling distillation, which is better suited to video tasks. With this combined approach, the number of function evaluations (NFE) required to generate a single video is dramatically reduced from 150 to 10 NFE. This means a 15x speedup in inference with almost no loss in image quality.
In addition, to address the memory bottleneck in long-sequence video generation, Kling-Omni adopts a hybrid parallel inference strategy (Ulysses parallelism + tensor parallelism) and designs a dedicated cache mechanism, achieving an additional speedup of about $2\times$.
Data Foundation: Building a Multimodal Data Engine
A powerful model depends on high-quality data. Kling-Omni has built a comprehensive data system covering the entire pipeline from data collection to processing.
In particular, for data synthesis, relying solely on real data often makes it difficult to learn precise controllability. Therefore, the team used internal image editing and video understanding models to construct a large amount of high-quality synthetic data for training the model’s editing and multi-image reference capabilities.

To ensure data quality, they also established a three-tier filtering system (as shown above), which cleans the data along three dimensions: basic quality, temporal stability, and cross-modal alignment, ensuring that only top-quality data is fed to the model.
Performance Evaluation: Results Beyond SOTA
How well does Kling-Omni actually perform? The research team built the OmniVideo-1.0 benchmark, which includes more than 500 test cases covering different subjects, scenes, and challenges.
In comparisons with industry-leading models such as Veo 3.1 and Runway-Aleph, Kling-Omni showed clear advantages.
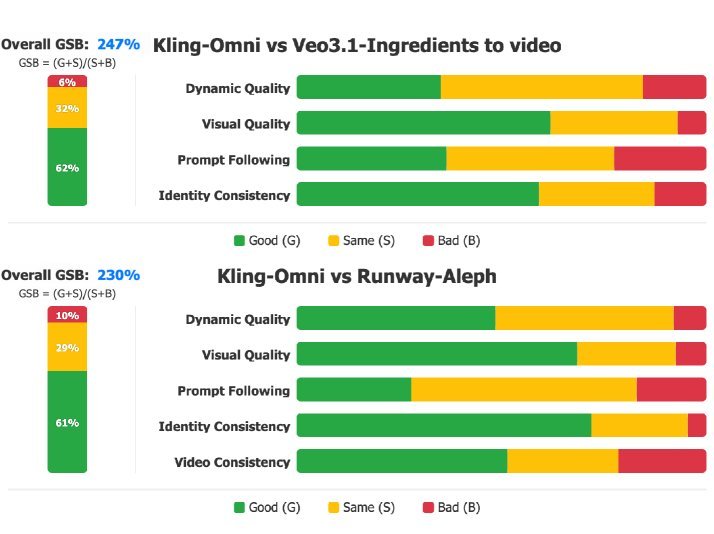
From the GSB (Good-Same-Bad) evaluation results above, we can see that:
-
In the image-reference generation task, Kling-Omni outperforms Veo 3.1 across multiple dimensions.
-
In the video editing task, compared with Runway-Aleph, Kling-Omni shows stronger editing ability while preserving the original video’s characteristics.
Conclusion
Kling-Omni is more than just a video generation model; it demonstrates the possibility of integrating perception, reasoning, and generation into a single system. With a unified architecture and efficient inference strategy, it makes “what you imagine is what you get” video creation more accessible than ever.
More importantly, its emerging understanding of the physical world and reasoning ability gives us a glimpse of the future shape of a “multimodal world simulator.” In such a simulator, AI would no longer merely generate pixels passively, but would begin to understand the dynamic and complex logic of the world behind those pixels.