Kimi Linear: An Expressive, Efficient Attention Architecture
KimiLinear Unveiled: The First Full Surpass of Full Attention, 6x Faster Decoding at 1M Context!
On the path toward more powerful AI agent, long-text processing has become an unavoidable “performance wall.” The traditional Transformer architecture, with its $O(N^2)$ attention computation complexity and linearly growing KV cache, becomes increasingly inadequate when handling ultra-long sequences, making efficiency and cost major bottlenecks.
Paper Title: Kimi Linear: An Expressive, Efficient Attention Architecture ArXiv URL: http://arxiv.org/abs/2510.26692v2
People once hoped that linear attention would solve this problem, but it often comes at the cost of model performance, especially on short-text tasks. It seemed like an impossible trade-off: performance or efficiency, you could only choose one.
Now, the Kimi team has offered a new answer: Kimi Linear.
This is a new hybrid linear attention architecture that, under strict fair comparisons, has for the first time comprehensively outperformed traditional Full Attention models across all scenarios, including short text, long text, and even reinforcement learning (RL).
It not only achieves up to a 6x throughput improvement in 1-million-token ultra-long-context decoding, but also reduces KV cache usage by 75%.
Kimi Delta Attention (KDA): A More Fine-Grained Memory Controller
At the core of the Kimi Linear architecture is a brand-new linear attention module called Kimi Delta Attention (KDA). To understand the elegance of KDA, we can think of it as an upgraded “memory management system.”
Traditional linear attention is like a brain with limited memory: in order to remember new things, it has to crudely forget old information, leading to the loss of key details.
Some improved methods, such as Gated DeltaNet (GDN), introduce a “forget gate” that allows the model to decide what to forget by “topic” (head-wise). It is like adding a few coarse switches to the memory system, letting it decide to forget the broad category of “history” while keeping “physics.” This is better than random forgetting, but still not fine-grained enough.
KDA, however, makes a revolutionary upgrade: it introduces a fine-grained gating mechanism.

This mechanism is like installing an independent switch for each “memory neuron” (channel-wise) in the brain. The model no longer forgets by “topic,” but can instead target a specific “knowledge point.” For example, when processing historical information, it can selectively forget an unimportant year while firmly retaining the key chain of historical events.
This “pixel-level” precise control over memory states allows KDA to use memory more efficiently within a limited RNN state capacity, greatly enhancing the model’s expressiveness.
Built for Efficiency: A Customized Parallel Algorithm
Fine-grained control is great, but will it slow things down? The Kimi team solved this with a customized chunkwise algorithm.
KDA’s state transition matrix adopts a special Diagonal-Plus-Low-Rank (DPLR) structure. The team designed a computation method tailored to this structure, enabling efficient parallel execution on hardware such as GPU Tensor Cores.
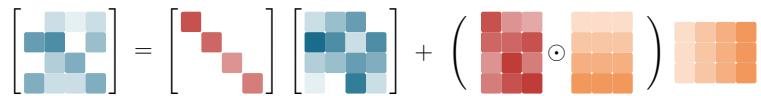
This algorithm cleverly transforms complex recursive computation into chunkwise parallel processing, not only avoiding the numerical precision issues common in other fine-grained gating methods, but also greatly reducing computation. Compared with a general DPLR implementation, KDA’s operator efficiency improves by nearly 100%.
This means KDA maintains extremely high hardware efficiency while also delivering strong expressive power.
The Kimi Linear Architecture: The Golden Ratio of Linear and Global
Kimi Linear is not a purely linear attention model, but a carefully designed hybrid architecture. It interleaves efficient KDA layers and traditional Full Attention layers (MLA in the paper) in a 3:1 ratio.
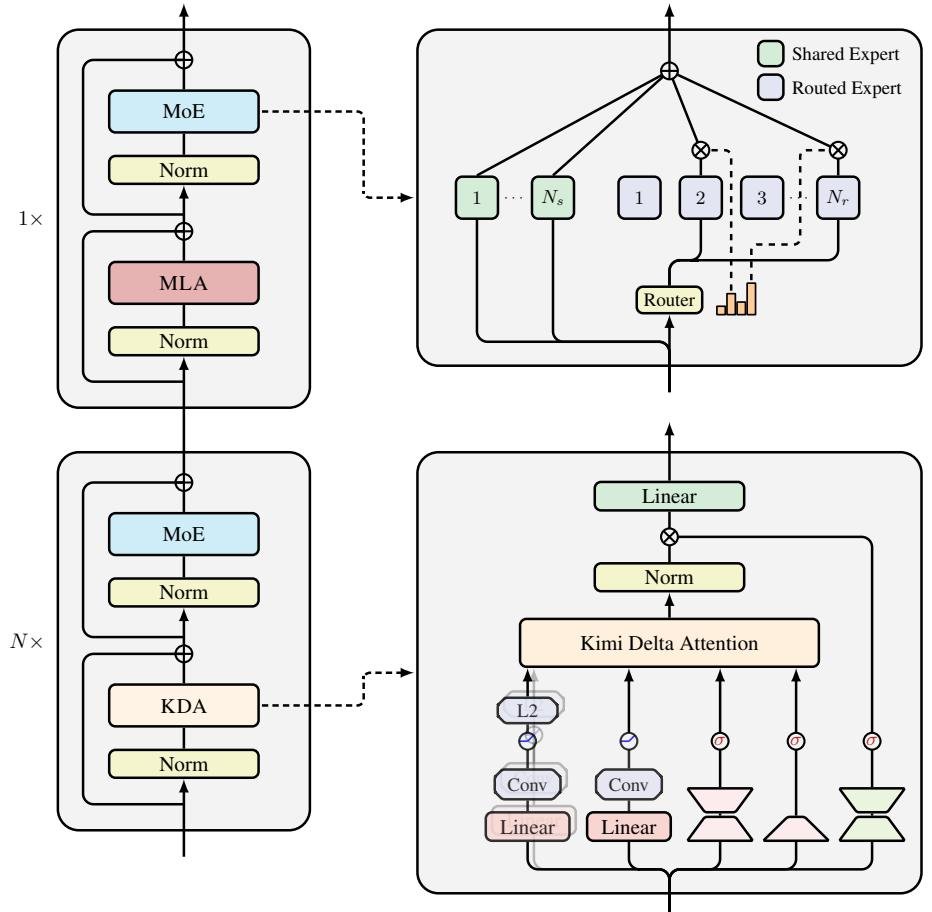
This design is nothing short of brilliant:
- 3 KDA layers: As the main workhorse, they handle the vast majority of sequence information, ensuring speed and low memory usage for long-text processing.
- 1 Full Attention layer: As a “global information hub,” it appears periodically to ensure the model does not lose global contextual relationships due to the locality of linear attention, solving the common “long-range retrieval” problem in pure linear models.
This 3:1 ratio is the experimentally validated “golden ratio,” achieving the best balance between performance and efficiency.
Crushing Full Attention: Stunning Experimental Results
Talk is cheap; the experimental data shows Kimi Linear’s true strength. In a “fair duel” against a Full Attention baseline model (MLA) with exactly the same configuration, parameters, and training data, Kimi Linear achieved overwhelming advantages.
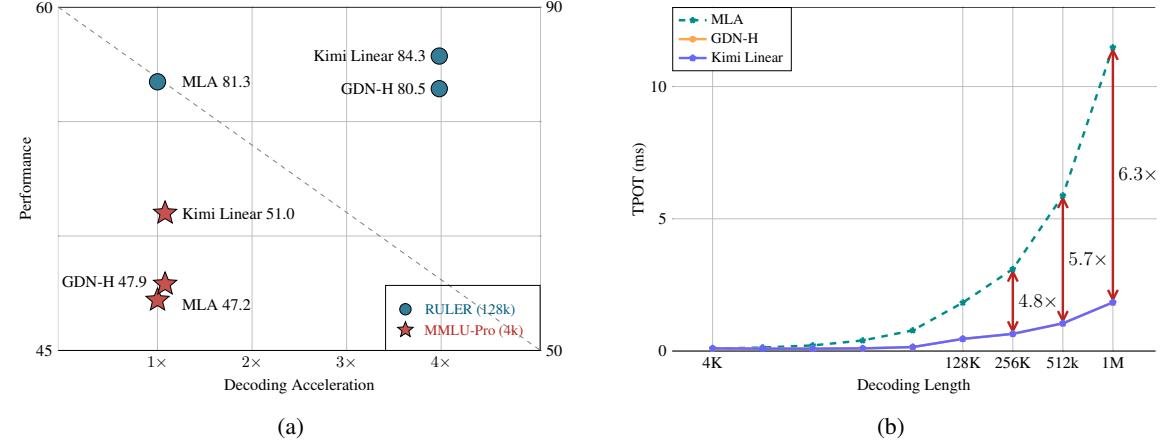 Caption: Kimi Linear achieves Pareto optimality in both performance and acceleration
Caption: Kimi Linear achieves Pareto optimality in both performance and acceleration
- Comprehensive performance lead: Whether on short-text general knowledge benchmarks (such as MMLU-Pro) or long-text RULER benchmarks, Kimi Linear scores significantly higher than the Full Attention model. This proves it is not a “one-trick pony,” but a true all-rounder.
- Massive efficiency gains: In million-token decoding tasks, thanks to the constant RNN state size, Kimi Linear’s throughput is 6.3x that of the Full Attention model. This means it can generate the same number of tokens much faster.
- Significant memory savings: KV cache usage is reduced by up to 75%, enabling larger batch sizes under the same hardware conditions and further improving overall throughput.
 Caption: At a 1M context length, Kimi Linear decodes 6x faster than Full Attention
Caption: At a 1M context length, Kimi Linear decodes 6x faster than Full Attention
Conclusion
The emergence of Kimi Linear marks an important breakthrough in the attention mechanism of large models. It not only overturns the long-standing impression that linear attention is “inferior to Full Attention,” but also surpasses it across multiple dimensions.
This research shows that through sophisticated gating design (KDA), efficient hardware-aware algorithms (customized parallel computation), and a smart hybrid architecture (the 3:1 ratio), we can absolutely build models that are both stronger than Full Attention and more efficient than it.
Kimi Linear is no longer a “toy” in the lab, but a “plug-and-play” solution that can seamlessly replace existing Full Attention architectures. To advance the community, the Kimi team has already open-sourced the core KDA operators, the vLLM integration implementation, and the model weights for pretraining and instruction fine-tuning, paving the way for the next generation of more efficient and more powerful AI agent.