Kimi k1.5: Scaling Reinforcement Learning with LLMs
-
ArXiv URL: http://arxiv.org/abs/2501.12599v4
-
Authors: Huabin Zheng; Haochen Ding; Xingzhe Wu; Han Zhu; Weiran He; Jin Zhang; Yibo Liu; Y. Charles; Zhengxin Zhu; Yingbo Yang; and 84 others
TL;DR
This paper proposes a method for scaling the capabilities of large language models (LLM) through reinforcement learning (RL). Its core idea is to leverage long context and an improved policy optimization algorithm to build a simplified framework that does not require complex techniques such as Monte Carlo tree search, achieving state-of-the-art performance on multiple reasoning benchmarks.
Key Definitions
- Long Chain-of-Thought, Long-CoT: The core concept of this paper, referring to the model generating extremely long reasoning trajectories within a context window of up to 128k tokens, involving complex cognitive processes such as planning, evaluation, reflection, and exploration. Compared with traditional Chain-of-Thought (CoT), it is not just a list of steps, but an implicit planning process that simulates search and trial-and-error in long text.
- Partial Rollout: A key training optimization technique designed for long-context reinforcement learning. It breaks a long generation trajectory (rollout) into multiple segments and completes them step by step across different training iterations. This avoids the high computational cost and resource monopolization caused by generating overly long sequences in a single pass, making RL training on ultra-long contexts possible.
- Online Policy Mirror Descent: The core policy optimization algorithm used in this paper. It is an off-policy reinforcement learning algorithm that maximizes reward while constraining the distance between the new policy and the old policy (reference policy) using relative entropy (KL divergence), thereby ensuring training stability.
- Long2short: A model compression or knowledge distillation technique aimed at transferring the complex reasoning ability of a powerful Long-CoT model to an efficient model that uses only Short-CoT at inference time, thereby reducing deployment cost while maintaining high performance.
Related Work
Currently, pretraining language models through next token prediction is the mainstream approach, but its effectiveness is limited by the amount of high-quality training data available. Reinforcement learning (RL) opens up a new direction for continuously improving artificial intelligence, enabling models to learn through exploration guided by reward signals and thereby reducing dependence on static datasets.
However, previous work applying RL to LLM has not achieved competitive results. This paper aims to address this problem: how to design an effective and scalable RL framework that can fully leverage the capabilities of LLM, especially on complex reasoning tasks, while being simpler in framework design than approaches that rely on traditional planning algorithms such as Monte Carlo tree search (MCTS) and value functions.
Method
The training pipeline of the Kimi k1.5 model proposed in this paper includes multiple stages: pretraining, standard supervised fine-tuning (SFT), Long-CoT supervised fine-tuning (Long-CoT SFT), and the core reinforcement learning (RL) stage. The report focuses on the RL stage.
RL Preparation
Before reinforcement learning, two key preparation steps are required:
- RL Prompt Set Construction: Building a high-quality RL prompt set is crucial. This paper follows three principles:
- Diversity Coverage: Prompts should cover multiple domains such as STEM, programming, and general reasoning.
- Balanced Difficulty: A model-based evaluation method is used to ensure a balanced difficulty distribution of questions by having the SFT model generate answers multiple times and judging difficulty based on the success rate.
- Accurate Evaluation: Questions that are easy to “reward hack” are excluded (such as multiple-choice and true/false questions), and methods are designed to filter out questions whose answers can be easily guessed without reasoning, ensuring the effectiveness of the reward signal.
- Long Chain-of-Thought Supervised Fine-Tuning (Long-CoT SFT): Before formal RL training, the paper uses a carefully constructed small-scale, high-quality Long-CoT dataset to perform lightweight SFT on the model. This dataset is generated through prompt engineering and contains reasoning trajectories that simulate human cognitive processes such as planning, evaluation, reflection, and exploration. This “warm-up” step is intended to help the model initially acquire the ability to generate structured, long-form reasoning.
Reinforcement Learning
Problem Formulation
This paper treats the complex reasoning process as an RL problem. Given a question $x$, the policy model $\pi_{\theta}$ needs to autoregressively generate a series of intermediate thought steps $z$ (i.e., CoT) and the final answer $y$. The goal is to maximize the expected value of a reward function $r(x,y,y^{*})$, which determines correctness based on the model answer $y$ and the ground-truth answer $y^{*}$ (reward is 0 or 1).
\[\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D},(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]\]The core insight of this paper is that, by leveraging the long-context capability of LLM, explicit planning algorithms such as tree search can be transformed into an implicit search process inside the model. The model performs trial and error, backtracking, and correction within a long chain of thought, achieving effects similar to the search of planning algorithms, but implemented simply through autoregressive generation.
Policy Optimization
This paper adopts a variant of online policy mirror descent. In each iteration, the algorithm optimizes an objective with relative entropy regularization, using the current policy $\pi_{\theta_i}$ as the reference to prevent overly large policy updates:
\[\max_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E}_{(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]-\tau\mathrm{KL}(\pi_{\theta}(x) \mid \mid \pi_{\theta_{i}}(x))\right]\]The final gradient update form is as follows. It is similar to policy gradient with a baseline, but the samples come from the off-policy reference model $\pi_{\theta_i}$, and an $l_2$ regularization term is added:
\[\frac{1}{k}\sum_{j=1}^{k}\left(\nabla_{\theta}\log\pi_{\theta}(y_{j},z_{j} \mid x)(r(x,y_{j},y^{*})-\overline{r})-\frac{\tau}{2}\nabla_{\theta}\left(\log\frac{\pi_{\theta}(y_{j},z_{j} \mid x)}{{\pi}_{\theta_{i}}(y_{j},z_{j} \mid x)}\right)^{2}\right)\]It is worth noting that this framework does not use a value function. The authors assume that, in long chain-of-thought generation, traditional credit assignment is harmful. Exploring wrong paths and eventually recovering from them is crucial for learning how to solve complex problems. If a value function were used, these valuable exploratory behaviors would be penalized too early.
Key Techniques and Strategies
- Length Penalty: To address the tendency of the model to generate overly long responses during RL training (“overthinking”), the paper introduces a length reward. Among all correct answers, shorter answers are rewarded; at the same time, incorrect and verbose answers are penalized.
- Sampling Strategies:
- Curriculum Sampling: Questions are sampled from easy to hard to improve efficiency in the early stage of training.
- Prioritized Sampling: The model’s success rate $s_i$ on each question is tracked, and questions are sampled with probability $1-s_i$, thereby focusing training on questions where the model performs poorly.
- Multimodal and Domain-Specific Methods:
- Coding: An automated pipeline is designed to use tools such as CYaRon to generate high-quality test cases for programming problems without test cases, serving as the reward signal.
- Mathematics: A Chain-of-Thought reward model (Chain-of-Thought RM) is trained that not only gives a correct/incorrect judgment but also generates the reasoning process behind the judgment, achieving an accuracy of 98.5%, far surpassing traditional RMs.
- Vision: The RL training data covers three major categories: real-world data, synthetic visual reasoning data, and text-rendered data, in order to improve the model’s ability to handle charts, real scenes, and mixed image-text content.
Long2short
To make the model more efficient while maintaining high performance, this paper proposes several methods for transferring the capabilities of a Long-CoT model to a Short-CoT model:
- Model Merging: Directly average the weights of the Long-CoT model and the Short-CoT model.
- Shortest Rejection Sampling: Sample multiple times for a question and select the shortest correct answer as SFT data.
- DPO: Use the shortest correct answer as the positive example and other longer answers (whether correct or not) as negative examples to construct preference pairs for DPO training.
- Long2short RL: After standard RL, perform a dedicated RL stage with a stronger length penalty and a restricted maximum rollout length.
Infrastructure Innovation
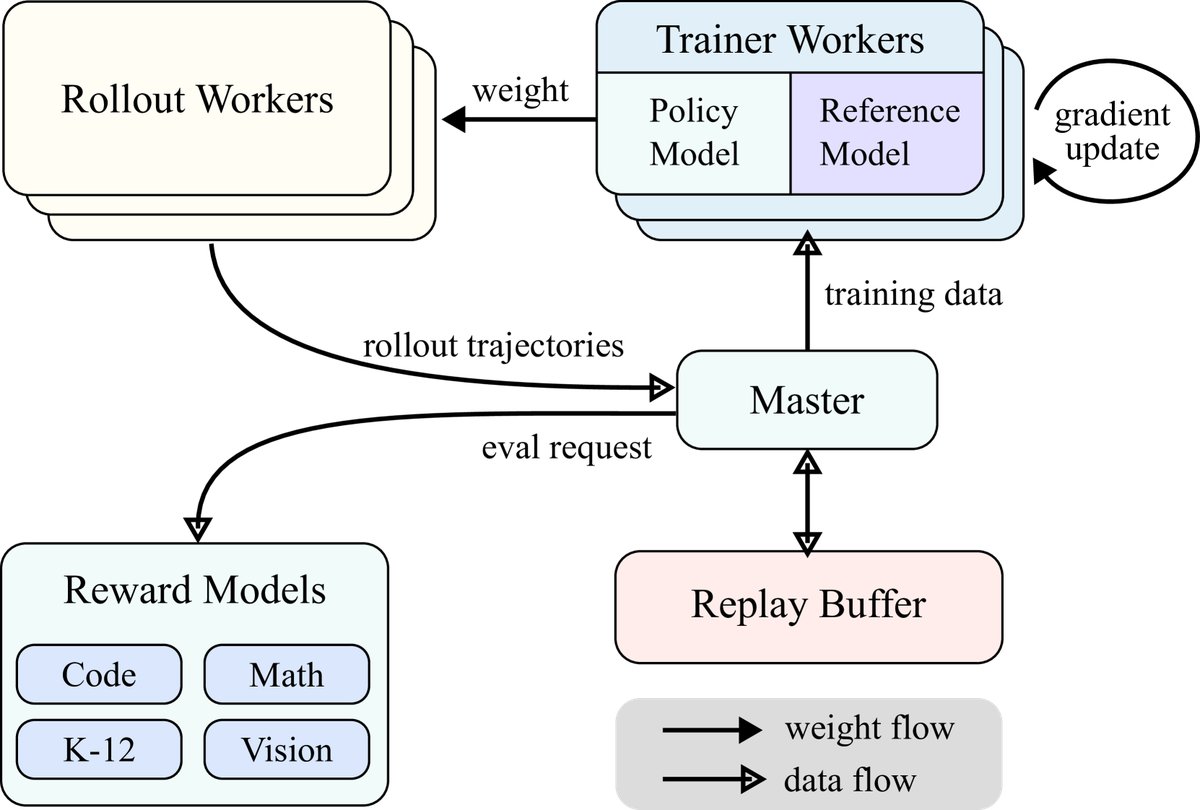
- Large-scale RL training system: This paper builds a synchronous iterative RL training system. The system includes a central master, rollout worker nodes, and training worker nodes. The rollout nodes are responsible for generating experience and storing it in the Replay Buffer, while the training nodes fetch data from it to update the model.
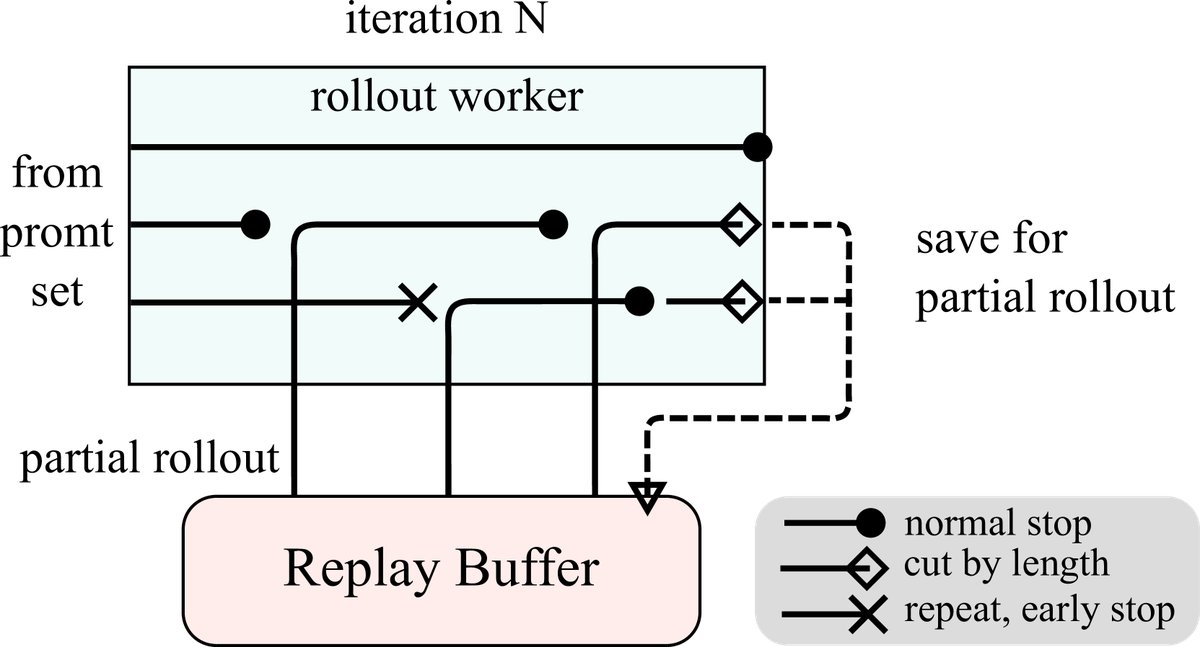
- Partial Rollouts: This is the core technique that enables long-context RL. The system sets a fixed token budget for each rollout. If a generation is not completed in one pass, the unfinished part is stored in the Replay Buffer and continued in the next iteration. In this way, prior content can be efficiently reused, greatly reducing the computational cost of generating long sequences.
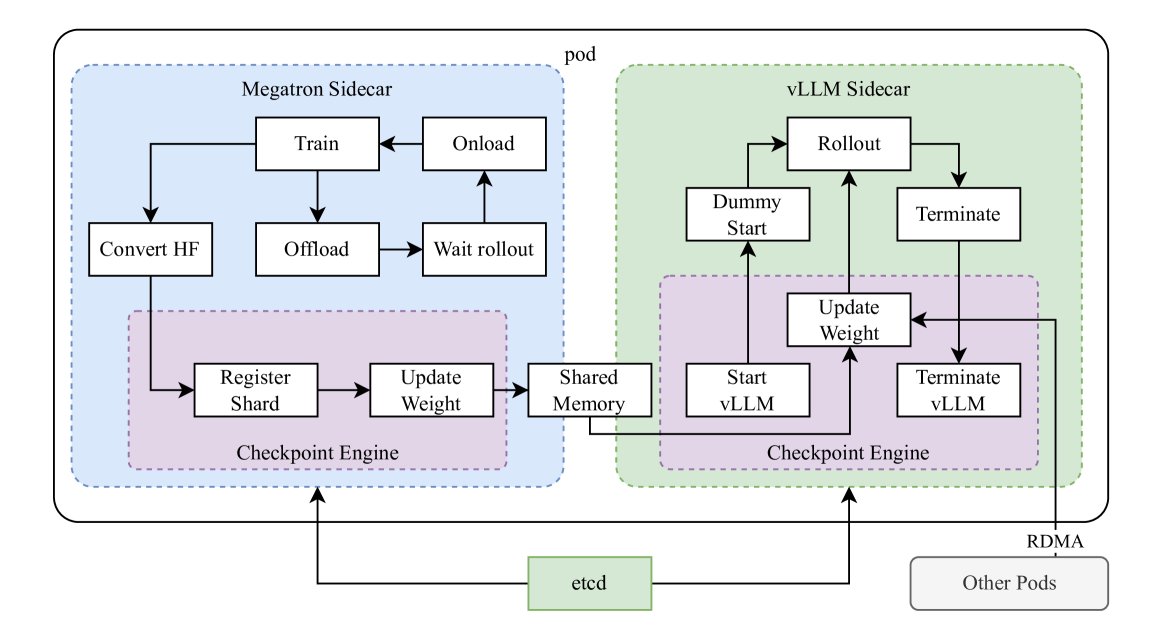
- Hybrid deployment of training and inference: To maximize GPU utilization, this paper designs a hybrid deployment framework. The framework uses Kubernetes Sidecar containers to deploy both the training framework (Megatron) and the inference framework (vLLM) in the same Pod. During the RL training phase, the GPU is used by Megatron; during the rollout (inference) phase, the model weights are transferred to vLLM in a memory-efficient way for execution, while the training process is paused. This avoids the GPU idling problem in on-policy RL caused by waiting for inference.
Experimental conclusions
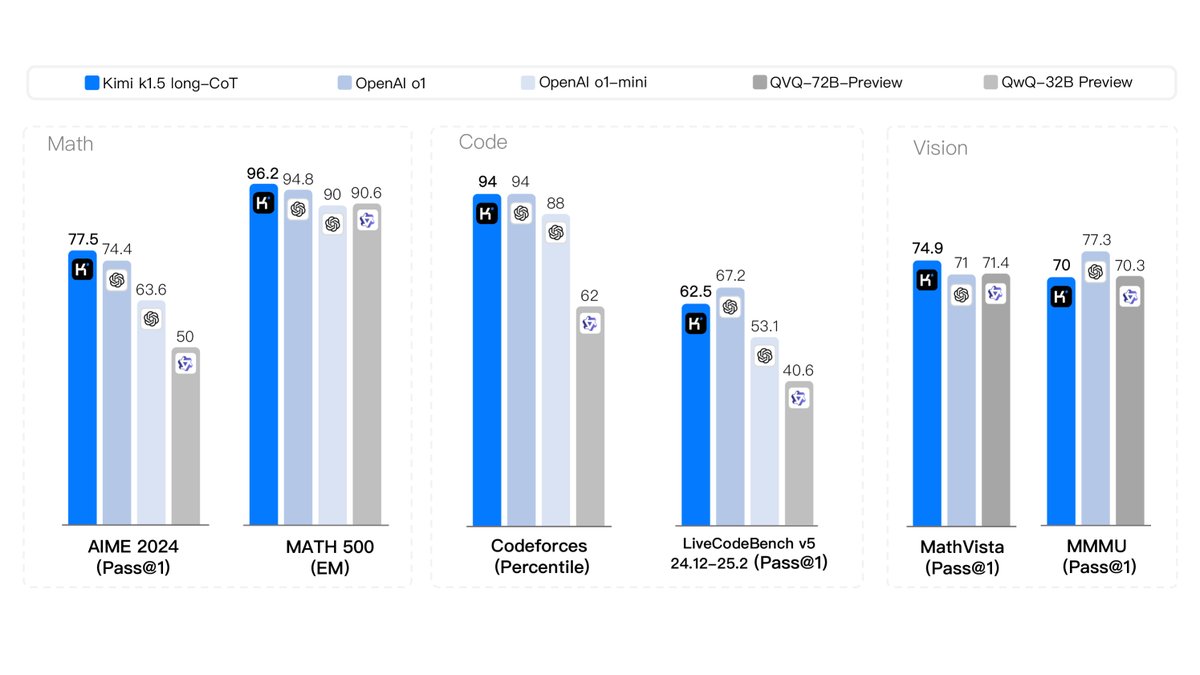
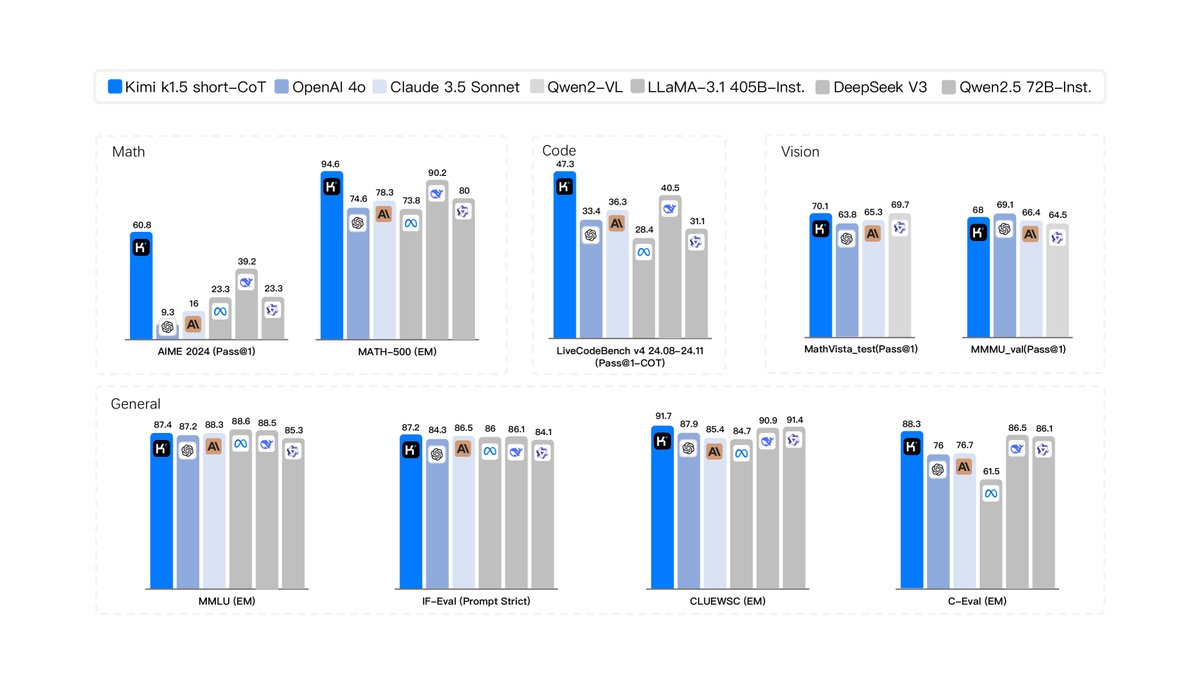
This paper validates the effectiveness of the proposed method through evaluations on multiple authoritative benchmarks.
- Main advantages and SOTA performance:
- Long-CoT model: Kimi k1.5 achieves industry-leading performance on multiple highly challenging reasoning benchmarks, comparable to OpenAI’s o1 model. For example, it reaches 77.5 on AIME, 96.2 on MATH 500, the 94th percentile on Codeforces, and 74.9 on the multimodal reasoning benchmark MathVista.
- Short-CoT model: The Short-CoT model obtained through the long2short technique proposed in this paper also achieves SOTA performance, significantly surpassing existing similar models (such as GPT-4o and Claude Sonnet 3.5). For example, it reaches 60.8 on AIME, 94.6 on MATH500, and 47.3 on LiveCodeBench.
- Verified conclusions:
- The experimental results strongly demonstrate that combining RL with long-context scaling is an effective path to improving LLM reasoning ability.
- The simplified RL framework proposed in this paper (without a value network or MCTS) is feasible and can achieve top-tier performance.
- The long2short technique is proven to be an effective knowledge distillation method, capable of successfully transferring the powerful capabilities of large, high-cost models to smaller, more efficient models, balancing performance and practicality.
- Scenarios with mediocre or poor performance:
- The paper does not explicitly mention scenarios where the method performs poorly or has obvious shortcomings, and mainly focuses on the SOTA results it achieves.