KCM: KAN-Based Collaboration Models Enhance Pretrained Large Models
-
ArXiv URL: http://arxiv.org/abs/2510.20278v1
-
Authors: Siliang Tang; Guangyu Dai; Yueting Zhuang
-
Publishing Institution: Zhejiang University
TL;DR
This paper proposes a large-small model collaboration framework called KCM (KAN-Based Collaboration Models). It uses a small judgment model based on Kolmogorov-Arnold Network (KAN) to intelligently assign input samples to either an efficient small model or a powerful pretrained large model for processing, and achieves collaborative enhancement between the two models through prompt modification and knowledge distillation, thereby significantly reducing inference costs while approaching large-model performance.
Key Definitions
- KCM (KAN-Based Collaboration Models): The core method proposed in this paper. A large-small model collaboration framework that dynamically assigns tasks through a judgment model. For samples judged as “simple,” the small model handles them directly; for “difficult” samples, the large model takes over. At the same time, the small model’s outputs are used to assist the large model (prompt modification), and the large model’s outputs are fed back to the small model (knowledge distillation), forming a closed-loop learning system.
- KAN (Kolmogorov-Arnold Network): A neural network architecture that replaces the traditional multilayer perceptron (MLP). Its core feature is that learnable activation functions are placed on the network’s “edges” rather than using fixed activation functions on the “nodes” as in MLPs. This allows KAN to learn more complex functions with fewer parameters and offers better interpretability and accuracy potential. In KCM, KAN is used to build the core “judgment small model.”
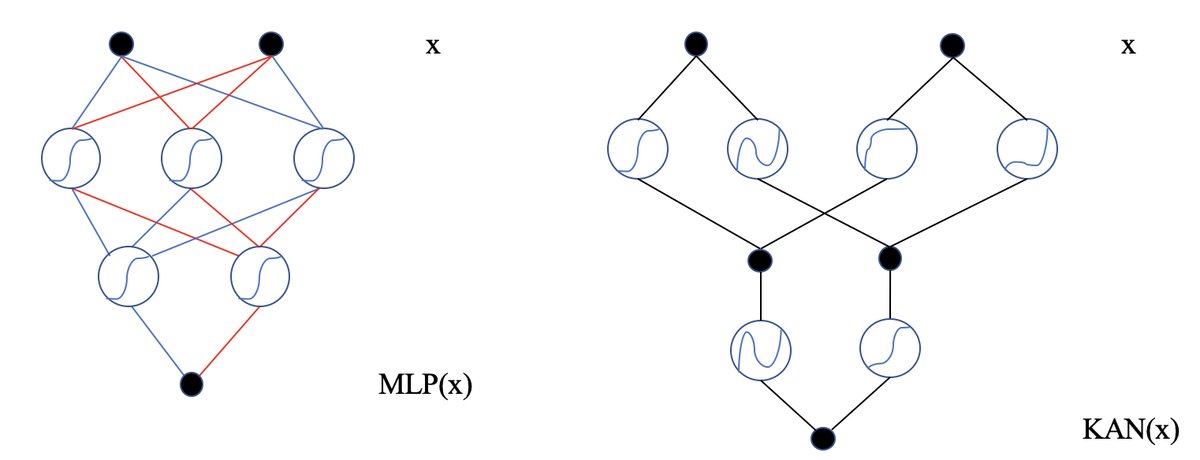
- Judgment Small Model: A key component in the KCM framework, built on KAN. Its role is to take an input sample \(x\) and output a confidence score \(C_x\), which is used to determine whether the sample should be handled by the small model or the large model. High confidence means the sample is suitable for the small model, while low confidence means the large model needs to intervene.
Related Work
At present, to balance the strong performance of large models with their high computational cost, large-small model collaboration has become an important research direction. Existing methods attempt to combine the strengths of both, but the key bottleneck lies in how to design an efficient and intelligent scheduling mechanism to decide when and how to use each model.
This paper aims to solve this specific problem: designing a general, efficient collaboration framework that not only intelligently allocates tasks between large and small models to reduce cost, but also improves the performance of the entire system through bidirectional interaction between models—that is, the small model assists the large model, and the large model guides the small model.
Method
The core idea of KCM is to build an intelligent, adaptive collaboration system. Its training and inference process are shown in the figure below, where a judgment model determines the data flow, and prompt modification and knowledge distillation are combined to enable the two models to co-evolve.
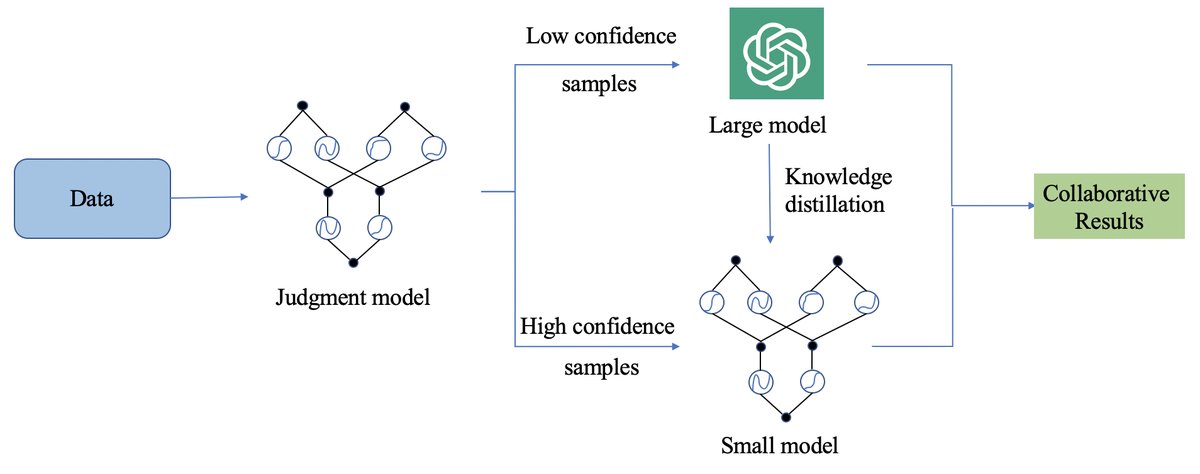
Innovations
The main innovations of this method are reflected in the following aspects:
KAN-Based Judgment Small Model
The core of the system is a judgment small model $F_j$, which is responsible for evaluating the “difficulty” of each input sample $x$. Unlike traditional MLP-based judges, this paper innovatively adopts the KAN architecture. KAN shifts the learning focus from nodes to edges; by learning activation functions on the edges, it can achieve higher accuracy and better generalization with fewer parameters.
This model processes the input $x$ and outputs a confidence score $C_x$, which is obtained by applying softmax to the model output logits $y_i$:
\[C_{x} = \frac{e^{y_{i}}}{\Sigma e^{y_{n}}}, y_{i} \in F_{j}(x)\]When $C_x$ is higher than the preset threshold $\epsilon$, the sample is considered “simple” and is handled by the small model $F_s$; otherwise, it is considered “difficult” and is handled by the large model $F_l$.
Small-Model Prompt Modification
For samples judged as “difficult” and sent to the large model $F_l$, KCM does not simply call the large model directly. Instead, it uses the small model $F_s$’s preliminary prediction for the sample to construct or modify the prompt given to the large model.
\[R_{l} = F_{l}(x_{i}, prompt), y_{i} \in F_{s}(x)\]This is equivalent to providing the large model with a “preliminary reference answer” or “context,” which can help the large model focus more quickly and accurately on the key points of the problem, thereby improving its efficiency and effectiveness on difficult samples.
Large-Model Knowledge Distillation
To allow the small model to learn from the large model’s “wisdom,” KCM adopts a knowledge distillation mechanism. When the large model $F_l$ processes a difficult sample $x$ and produces output $C_l$, this output is used as a “teacher” signal to guide the learning of the small model $F_s$ through a KL-divergence loss function. This enables the small model to learn the large model’s “thinking pattern” when handling complex problems.
\[L_{ls} = KL(F_{s}(x), C_{l}), \quad \text{when } C_{l} > \epsilon\]In addition, the confidence output $C_x$ from the judgment model $F_j$ can also serve as a distillation signal to help optimize the small model $F_s$.
\[L_{js} = KL(F_{s}(x), C_{x}), \quad \text{when } C_{x} > \epsilon\]This bidirectional flow of knowledge forms a virtuous cycle: the small model becomes increasingly stronger and can handle more samples, which further reduces the frequency of calls to the expensive large model.
Algorithm Flow
Training phase:
- For each sample, the judgment model $F_j$ first computes the confidence $C_x$.
- If $C_x$ is below the threshold $\epsilon$, the sample is marked as “difficult” and sent to the large model $F_l$.
- The large model’s output $C_l$ is used to compute the distillation loss $L_{ls}$ to update the small model $F_s$.
- The process iterates continuously, and the small model $F_s$ is continuously optimized under the joint guidance of the judgment model and the large and small models.
Inference phase:
- For a new sample, the judgment model $F_j$ computes the confidence $C_x$.
- If $C_x > \epsilon$, the result from the small model $F_s$ is used directly.
- If $C_x \le \epsilon$, the large model $F_l$ is invoked (possibly combined with prompt modification from the small model) to obtain the final result.
Experimental Conclusions
Experiments on language, vision, and multimodal tasks verified the effectiveness and generality of the KCM framework, and the threshold $\epsilon$ was set to 0.98.
- Language tasks: On the APD dataset, whether combined with BERT or ChatGPT, KCM significantly improved the accuracy of the baseline models and outperformed other collaboration methods.
Accuracy of BERT+KCM on the APD dataset
| Model | IER | IED | Trigger | Role 1 | Role 2 | Average |
|---|---|---|---|---|---|---|
| BERT | 88.5% | 85.3% | 87.2% | 81.3% | 79.8% | 84.42% |
| BERT+D | 89.2% | 85.9% | 87.8% | 82.2% | 80.5% | 85.12% |
| BERT+KD | 89.9% | 86.2% | 88.3% | 82.5% | 80.9% | 85.56% |
| BERT+MCM | 90.5% | 86.8% | 88.8% | 83.2% | 81.5% | 86.16% |
| BERT+KCM | 91.1% | 87.2% | 89.5% | 83.9% | 82.3% | 86.80% |
Accuracy of ChatGPT+KCM on the APD dataset
| Model | IER | IED | Trigger | Role 1 | Role 2 | Average |
|---|---|---|---|---|---|---|
| ChatGPT | 92.5% | 90.3% | 91.2% | 85.3% | 84.8% | 88.82% |
| ChatGPT+D | 92.9% | 90.8% | 91.8% | 85.9% | 85.2% | 89.32% |
| ChatGPT+KD | 93.3% | 91.2% | 92.3% | 86.3% | 85.9% | 89.80% |
| ChatGPT+MCM | 93.8% | 91.8% | 92.9% | 86.9% | 86.5% | 90.38% |
| ChatGPT+KCM | 94.3% | 92.3% | 93.5% | 87.5% | 87.3% | 90.98% |
- Visual task: On the long-tailed image classification dataset CIFAR-100-LT, KCM also improved the performance of multiple vision backbones (such as ResNet).
Accuracy on the CIFAR-100-LT dataset
| Model | Many | Medium | Few | Overall |
|---|---|---|---|---|
| ResNet-32 | 65.2% | 46.1% | 20.3% | 46.8% |
| ResNet-32+KCM | 70.3% | 51.5% | 23.8% | 52.3% |
| BBN | 73.5% | 51.2% | 26.5% | 53.5% |
| BBN+KCM | 78.4% | 56.8% | 29.3% | 58.7% |
- Multimodal task: On the MSCOCO dataset, KCM enhanced CLIP’s performance on image-text retrieval tasks.
Experimental accuracy on the MSCOCO dataset
| Model | I2T R@1 | I2T R@5 | I2T R@10 | T2I R@1 | T2I R@5 | T2I R@10 |
|---|---|---|---|---|---|---|
| CLIP | 73.2% | 91.5% | 96.8% | 54.7% | 79.5% | 87.2% |
| CLIP+KCM | 75.4% | 93.1% | 97.8% | 57.2% | 81.6% | 89.1% |
- Ablation study: To verify the superiority of using KAN as the judgment model, this paper directly compared the performance of KCM (based on KAN) and MCM (based on MLP). The results show that KCM outperformed MCM on all test tasks, with an average performance improvement of about 6%, demonstrating the advantage of KAN in building efficient judgment models.
Ablation study accuracy of MCM and KCM
| Model | APD(%) | CIFAR(%) | MSCOCO(%) |
|---|---|---|---|
| MCM | 90.38 | 57.6 | 77.2 |
| KCM | 90.98 | 58.7 | 78.2 |
Conclusion
The experimental results strongly demonstrate that KCM is a flexible and efficient large-small model collaboration framework. Through the combination of KAN-based intelligent routing, prompt modification, and knowledge distillation, it achieves significant performance gains across tasks in multiple modalities while successfully reducing reliance on large models. This method not only outperforms baseline models and traditional collaboration methods in terms of effectiveness, but also validates the value of KAN networks in building such collaborative systems.