In-Context Distillation with Self-Consistency Cascades: A Simple, Training-Free Way to Reduce LLM Agent Costs
Agent inference costs cut by 2.5x: Stanford proposes “context distillation,” letting small models learn from large models without training

Building powerful LLM Agents is a hot trend right now, but there is a harsh reality facing every developer: the inference costs of top-tier models like GPT-4 or Claude are simply too high! This not only hinders large-scale deployment, but also makes rapid prototype validation extremely expensive. Is there a way to enjoy the intelligence of top models without bearing their hefty bills?
ArXiv URL:http://arxiv.org/abs/2512.02543v1
Researchers from Stanford University and other institutions have delivered an impressive answer. They propose an extremely simple yet efficient training-free method that reduces Agent inference costs by a full 2.5x while maintaining accuracy comparable to top models! The core secret is the clever combination of “context distillation” and “self-consistency cascades.”
Core idea: when “context distillation” meets “self-consistency cascades”
Traditional cost-reduction methods, such as model fine-tuning, are not only time-consuming and labor-intensive, but also require substantial expertise, which runs counter to the idea of agile development. The new paradigm proposed in this paper completely bypasses the training process.
Its core consists of two major components:
-
In-Context Distillation: This concept borrows from classic knowledge distillation, but the implementation is completely different. It no longer requires training a “student model” to learn from a “teacher model.” Instead, at each inference step, it dynamically retrieves the most relevant cases from a prebuilt “teacher model example library” and directly places them into the “student model’s” context. It is like an apprentice (the student model) being able to consult the master’s (the teacher model’s) solution notes at any time while solving a problem, thereby imitating the master’s thinking and actions “on the spot.”
-
Self-Consistency Cascades: With the chance to “learn from the master,” the student model’s capability is greatly enhanced, but how do we know when it has learned well and when it will make mistakes? “Self-consistency cascades” act as the quality inspector. It asks the student model to generate multiple answers to the same question, for example three. If all answers are exactly the same, it means the student is confident, and we accept its answer. If the answers are inconsistent, it means the student is confused, and the system automatically “cascades” the difficult problem to the expensive teacher model for resolution.
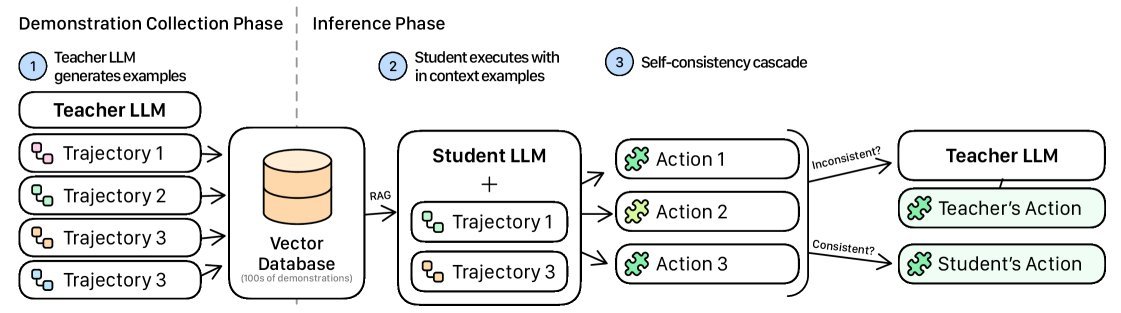
Figure 1: The workflow of context distillation and self-consistency cascades. First, teacher model demonstrations are collected and stored in a database; at inference time, relevant examples are retrieved for the student model, and a self-consistency check determines whether to seek help from the teacher model.
This strategy is very smart: it only uses the “ace card” at the most critical and least certain steps, while in the vast majority of cases the low-cost student model handles the task, achieving the best balance between cost and performance.
Two steps: how does the new method work?
The entire system workflow is clearly divided into two stages:
Stage 1: Building the teacher demonstration database
This step is the preparation phase. The researchers first use a high-performance “teacher model” (such as Claude 3 Sonnet) to run the Agent on a small task set, and fully record its successful trajectories—including the reasoning and action at each step.
These valuable experiences are converted into vectors and stored in a vector database $D$ for fast retrieval later. This process is one-time, and its cost can be quickly amortized over subsequent large-scale applications.
Stage 2: Inference and dynamic decision-making
When a new task arrives, the “student model” (such as GPT-4.1-mini) takes over. At each step $t$ of the Agent’s task execution:
-
Retrieval: Based on the current goal $g$, plan $p$, and observation $o_t$, the system retrieves the most relevant teacher demonstrations from database $D$.
-
Distillation: These retrieved “notes” are injected into the student model’s prompt, allowing the student model to learn the teacher’s behavior patterns in context.
-
Self-consistency check: The student model is asked to generate $N$ candidate actions ${a_t^{(i)}}$. The system checks whether these actions are exactly consistent.
-
Decision:
-
If all actions are consistent ($\text{Consistent}=1$), the student model’s action $a_t^{(1)}$ is adopted.
-
If the actions are inconsistent, it means the student model is uncertain, and the system delegates this step to the teacher model $M_t$ for decision-making.
This loop occurs at every step of the task, ensuring that the Agent remains both efficient and reliable throughout execution.
Stunning experimental results: a win-win for cost and accuracy
Talk is cheap; the data speaks for itself. The study was validated on two mainstream Agent benchmarks, ALFWorld and AppWorld.
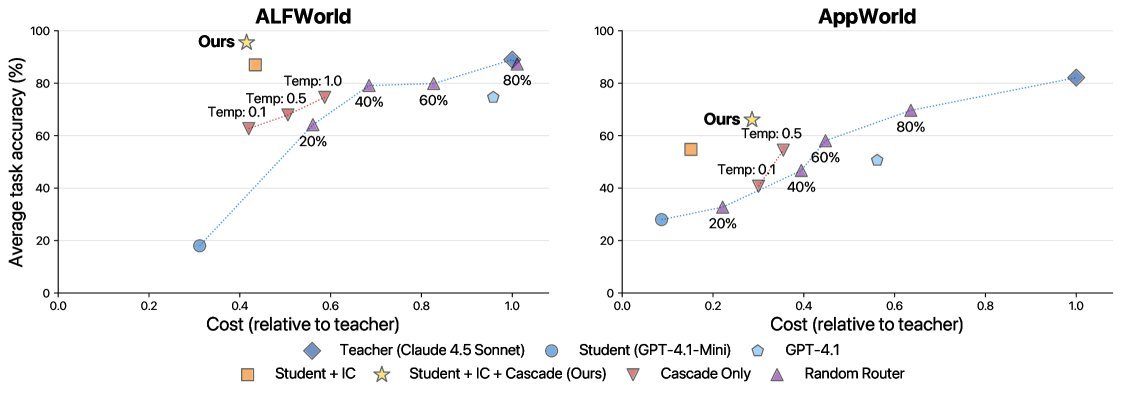
Figure 2: Pareto frontier of cost and accuracy. The yellow star representing “IC + Cascade” (the proposed method) significantly outperforms other methods on both benchmarks, achieving lower cost and higher accuracy.
The results are exciting:
-
Significant cost reduction: On ALFWorld, the method achieved a 2.5x cost reduction while matching and even surpassing the teacher model’s accuracy (per-task cost dropped from $0.059 to $0.024). On the more complex AppWorld, it also achieved a 2x cost reduction at the same accuracy level.
-
Fast cost recovery: On ALFWorld, the initial cost of collecting teacher examples is fully recovered after only 843 tasks. If deployed at a scale of 1 million tasks, it is expected to save more than $34,900!
-
Strong generality: The method is not only applicable to top-tier closed-source models, but also shows consistent effectiveness on open-source models (such as Llama 3), demonstrating broad applicability.
Even more interestingly, on ALFWorld, the student model equipped with “context distillation” even outperformed its teacher (96% vs 89%). The researchers speculate that this is because the retrieved multiple examples not only show the teacher’s reasoning process, but also indirectly provide rich information about the environment dynamics.
Conclusion: bringing advanced Agents to the masses
The greatest value of this study is that it provides an extremely practical and economical path for large-scale deployment of LLM Agents in real production environments.
It moves away from complex model training and cumbersome prompt engineering, and through a “plug-and-play” dynamic retrieval and decision-making mechanism, allows developers to continue enjoying the efficiency of agile development while keeping operating costs within an acceptable range.
Simple, training-free, and highly effective—this work undoubtedly removes a major barrier to the popularization and commercialization of LLM Agent technology, bringing once out-of-reach advanced Agent applications one step closer to us.