Improving Online Algorithms via ML Predictions
-
ArXiv URL: http://arxiv.org/abs/2407.17712v1
-
Authors: Manish Purohit; Ravi Kumar; Zoya Svitkina
-
Publisher: Google
TL;DR
This paper proposes a theoretical framework that uses machine learning (ML) predictions to improve the performance of online algorithms. The designed algorithms achieve near-optimal performance when the predictions are accurate (consistency), and do not degrade significantly when the predictions are wrong, gracefully falling back to the level of classic online algorithms (robustness).
Key Definitions
The paper introduces or adopts the following concepts, which are crucial for understanding the combination of online algorithms and ML predictions:
- Competitive Ratio: A standard measure of online algorithm performance, defined as the ratio between the cost of the online algorithm on the worst-case input and the cost of the optimal offline algorithm that knows all future information.
- Consistency: Measures how close the algorithm is to the optimal solution when the ML prediction is completely accurate. If an algorithm has a competitive ratio of $\beta$ when the prediction error is zero, it is called $\beta$-consistent.
- Robustness: Measures the algorithm’s performance in the worst case, that is, when the predictions may be very poor. If an algorithm’s competitive ratio is at most $\gamma$ under any prediction error, it is called $\gamma$-robust.
- Prediction Error ($\eta$): An indicator that quantifies the gap between the ML prediction and the true value. In this paper, the exact definition depends on the problem; for example, in the ski rental problem, $\eta = \mid y-x \mid $ (the absolute difference between the predicted and true number of days); for the job scheduling problem, $\eta = \sum_j \mid y_j - x_j \mid $ (the $L_1$ norm of the differences between the predicted and true processing times of all jobs).
Related Work
There are currently two main paradigms for handling uncertainty: one is machine learning, which builds models from historical data to predict the future; the other is online algorithms, which aim to design strategies with guaranteed worst-case performance, but such strategies are often too conservative and cannot exploit potentially favorable information.
Recent research has begun to combine the two, using ML predictions to improve the performance of online algorithms. The core challenge is how to design an algorithm that:
- When the predictions are accurate, can outperform the performance lower bound of traditional online algorithms (achieving good consistency).
- When the predictions are wrong, its performance does not collapse and can at least maintain the level of traditional online algorithms (ensuring robustness).
This paper aims to design new algorithms with both consistency and robustness for two classic online problems: ski rental and non-clairvoyant job scheduling.
Method
The core idea of this paper is not to blindly trust ML predictions, but to use them as a basis for adjusting the decision-making strategy of classic online algorithms, introducing a hyperparameter $\lambda$ to balance trust in the predictions against protection against the worst case.
Ski Rental
Problem setting: Renting skis costs 1 unit per day, while buying them outright costs $b$ units. The skier does not know how many days they will ski in total (the true number of days is $x$), but there is an ML model that predicts the number of days as $y$.
Limitations of the Naive Algorithm
A simple idea is to fully trust the prediction: if $y \geq b$, buy on the first day; otherwise, keep renting. This algorithm (Algorithm 1) is optimal when the prediction is accurate ($\eta=0$), so it is 1-consistent. But if the prediction is badly wrong (for example, predicting very few days $y < b$ while the actual number of days is much larger $x \gg b$), its cost can become arbitrarily high, so it is not robust.
Deterministic Robust and Consistent Algorithm (Algorithm 2)
To address this issue, the paper proposes a deterministic algorithm with a hyperparameter $\lambda \in (0, 1)$:
- If the prediction is $y \geq b$ (leaning toward buying), then buy on day $\lceil\lambda b\rceil$.
- If the prediction is $y < b$ (leaning toward renting), then buy on day $\lceil b/\lambda\rceil$.
Innovation: This algorithm uses $\lambda$ to balance trust in the prediction and a conservative strategy.
- Advantage: As $\lambda \to 0$, the algorithm trusts the prediction more and achieves better consistency (approaching 1); as $\lambda \to 1$, the algorithm becomes more conservative and more robust (approaching the classic optimal deterministic algorithm with competitive ratio 2). The algorithm is $(1+1/\lambda)$-robust and $(1+\lambda)$-consistent, providing a smooth trade-off.
Randomized Robust and Consistent Algorithm (Algorithm 3)
To obtain a better performance trade-off, the paper further designs a randomized algorithm. Instead of buying on a fixed day, it randomly selects a purchase day within a time window according to a specific probability distribution.
- If the prediction is $y \geq b$, then it randomly selects a purchase day from ${1, \dots, \lfloor\lambda b\rfloor}$ according to the probability distribution $q_i$.
- If the prediction is $y < b$, then it randomly selects a purchase day from ${1, \dots, \lceil b/\lambda\rceil}$ according to the probability distribution $r_i$.
Innovation: By randomizing, the algorithm smooths out the “sharpness” of the decision and avoids being targeted by the adversary at a specific decision point.
- Advantage: The algorithm is $(\frac{1+1/b}{1-e^{-(\lambda-1/b)}})$-robust and $(\frac{\lambda}{1-e^{-\lambda}})$-consistent. As shown below, compared with the deterministic algorithm, it can provide better consistency under the same robustness guarantee.
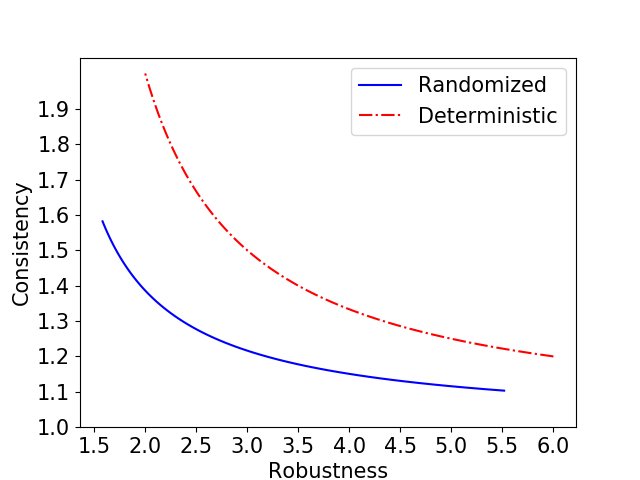
Non-clairvoyant Job Scheduling
Problem setting: Schedule $n$ jobs on a single machine with the goal of minimizing the total completion time. The actual processing time $x_j$ of each job is unknown, but a predicted value $y_j$ is available. Jobs can be preempted and resumed at any time. The classic optimal non-clairvoyant algorithm is Round-Robin (RR), with a competitive ratio of 2.
Preferential Round-Robin (PRR)
The paper proposes the PRR algorithm, which combines two strategies:
- Shortest Predicted Job First (SPJF): Execute jobs in increasing order of predicted processing time $y_j$. This strategy has good consistency but poor robustness.
- Round-Robin (RR): Allocate CPU time evenly among all unfinished jobs. This strategy is robust (competitive ratio 2).
The PRR algorithm executes the SPJF strategy at rate $\lambda$ while executing RR at rate $1-\lambda$. Specifically, at any time, the currently “shortest predicted” unfinished job receives processing rate $\lambda$, while all unfinished jobs share the remaining $1-\lambda$ processing rate.
Innovation: This algorithm is a hybrid strategy that uses a parameter $\lambda$ to combine a high-performance prediction-based strategy with a classic worst-case-guaranteed strategy.
- Advantage: The PRR algorithm is $(\frac{2}{1-\lambda})$-robust and $(\frac{1}{\lambda})$-consistent (under a more precise analysis, for the case $\eta=0$, consistency can reach $\frac{1+\lambda}{2\lambda}$). This allows the algorithm to perform far better than RR when the predictions are accurate, while not performing worse than RR when the predictions are wrong, successfully leveraging prediction information while avoiding the risks it brings.
Experimental Results
The paper validates the effectiveness of the proposed algorithms through simulation experiments.
Ski Rental Experiment
- Setup: The purchase cost is $b=100$, the true number of days $x$ is sampled uniformly from $[1, 400]$, and the prediction error follows a normal distribution with mean 0 and standard deviation $\sigma$.
- Conclusion: As shown in Figure (a), even when the prediction error is large (for example, $\sigma = 2b$), the average competitive ratio of the prediction-based algorithms proposed in this paper (both deterministic and randomized) is still significantly better than that of the classic algorithms that do not use predictions. In particular, the deterministic algorithm in this paper even outperforms the classic randomized algorithm.
Oblivious Scheduling Experiment
- Setup: There are 50 jobs, and their processing times are sampled from a Pareto distribution, with the statistics shown in the table below. The prediction error also follows a normal distribution.
| N | min | max | mean | $\sigma$ |
|---|---|---|---|---|
| 50 | 1 | 22352 | 2168 | 5475.42 |
- Conclusion: As shown in Figure (b), the SPJF algorithm, which relies solely on predictions, suffers a sharp performance drop as the error increases. In contrast, the PRR algorithm proposed in this paper ($\lambda=0.5$) performs much better than RR when the predictions are accurate, and when the prediction error is very large, its performance remains stable at the level of RR, demonstrating strong robustness.
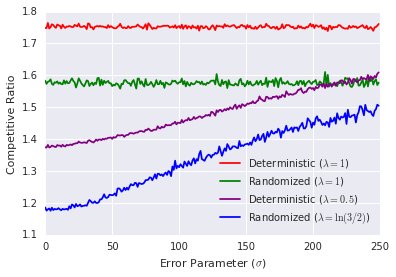 (a) Ski Rental
(a) Ski Rental
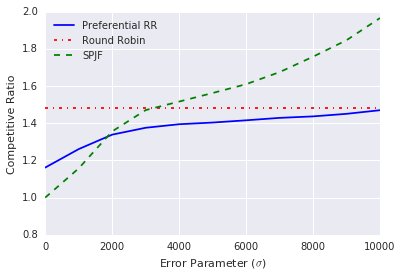 (b) Oblivious Scheduling
(b) Oblivious Scheduling
Final Conclusion: The experimental results strongly support the theoretical analysis, showing that the algorithmic framework proposed in this paper can effectively leverage machine learning predictions in practice to improve the performance of online decision-making while maintaining the necessary safety guarantees.