Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents
-
ArXiv URL: http://arxiv.org/abs/2509.09265v1
-
Author: Jiacai Liu; Yuqian Fu; Yingru Li; Ke Wang; Yu Yue; Xintao Wang; Yuan Lin; Yang Wang; Jiawei Wang; Lin Zhang
-
Publisher: ByteDance
TL;DR
This paper proposes a framework called Entropy-Modulated Policy Gradients (EMPG). By leveraging the intrinsic uncertainty (entropy) of an intelligent agent at each step in long-horizon tasks to dynamically adjust policy gradients, it effectively addresses the credit assignment problem under sparse rewards, significantly improving the learning efficiency and final performance of LLM agents.
Key Definitions
The core of this paper is centered on using the model’s intrinsic uncertainty to reshape reinforcement learning signals. The key definitions are as follows:
- Entropy-Modulated Policy Gradients (EMPG): The core framework proposed in this paper. It does not rely on external dense reward signals, but instead modulates (re-calibrates) policy gradients through the intrinsic uncertainty generated by the agent during decision-making, quantified by policy entropy. The framework includes two key components: “self-calibrating gradient scaling” and “future clarity bonus.”
- Step-Level Uncertainty: A quantification of the agent’s confidence in each “think-act” cycle. This paper adopts a practical and efficient proxy metric: the average entropy of all tokens generated in a step. Low entropy indicates high confidence, while high entropy indicates uncertainty.
- Self-Calibrating Gradient Scaling: The first core component of EMPG. It is a scaling function that adjusts the learning signal assigned from the final task outcome according to the entropy of the current step. Its key role is to amplify gradients for high-confidence (low-entropy) steps while attenuating gradients for low-confidence (high-entropy) steps.
- Future Clarity Bonus: The second core component of EMPG. This is an intrinsic reward used to encourage the agent to choose actions that lead to more certain, clearer future states (i.e., lower entropy in the next step).
Related Work
At present, autonomous agents based on large language models (LLMs) face a core bottleneck when handling long-horizon tasks: because reward signals are extremely sparse (typically provided only at the end of the task), it is difficult to accurately assign credit to important intermediate steps.
To address this issue, current research mainly falls into two directions:
- Implicit Reward Guidance: Using traditional reinforcement learning techniques (such as reward shaping, intrinsic curiosity, and inverse reinforcement learning) to create dense reward signals. However, when facing the enormous state and action spaces inherent to LLM agent tasks, these methods are often too computationally expensive, difficult to scale, or heavily dependent on human prior knowledge.
- Explicit Step-Level Supervision: Using Process Reward Models (PRMs) to provide feedback for each step. But building PRMs requires high-cost human annotation, and defining the “correct” single step in complex interactive tasks is itself a difficult problem, leading to poor generalization and impracticality.
In addition, some work has tried to use policy entropy as a learning signal, but either it is risky due to “confidently making mistakes,” or its application is limited to single-turn generation tasks, failing to solve the credit assignment problem in multi-step decision-making.
This paper aims to solve the credit assignment problem in long-horizon, multi-step decision-making tasks that the above methods fail to handle effectively. Specifically, it first theoretically reveals the inherent coupling between policy gradient magnitude and policy entropy: high-entropy (uncertain) actions produce large gradients, while low-entropy (confident) actions produce small gradients, resulting in inefficient and unstable learning. The goal of this paper is to directly correct this intrinsic gradient dynamic.
Method
This paper proposes the Entropy-Modulated Policy Gradients (EMPG) framework, aiming to solve the credit assignment problem in long-horizon agent tasks by recalibrating the learning dynamics of policy gradients. Its core idea is to use the agent’s intrinsic, step-by-step uncertainty to modulate the learning signal.
Theoretical Motivation
The paper first theoretically analyzes the relationship between policy gradients and policy uncertainty. As shown in Proposition 1, for a standard softmax policy, the square of the expected L2 norm of the score function has a monotonic relationship with the policy’s Rényi-2 entropy:
\[\mathbb{E}_{a\sim\pi_{\theta}(\cdot \mid s)}\left[ \mid \mid \nabla_{z_{\theta}(s)}\log\pi_{\theta}(a \mid s) \mid \mid ^{2}\right]=1-\exp(-H_{2}(\pi))\]This reveals an inherent learning dynamic: high-entropy (uncertain) steps naturally produce large gradients, which may lead to unstable training; low-entropy (confident) steps produce small gradients, meaning that even if these steps are correct, their reinforcement effect is limited, thereby reducing learning efficiency. EMPG is designed precisely to directly address this dual challenge.
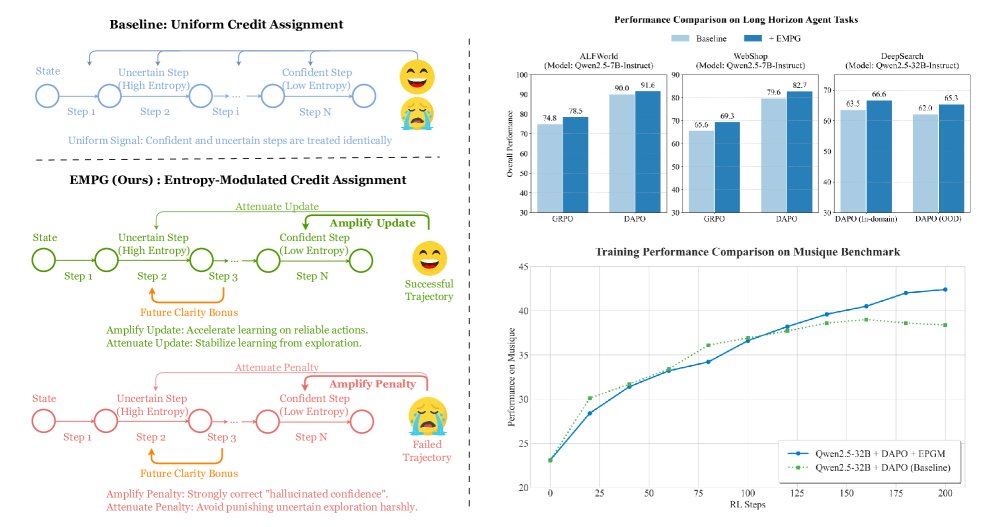
Innovations
The innovation of EMPG lies in introducing a new Modulated Advantage $A_{\text{mod}}$, which replaces the traditional practice in reinforcement learning of using a single advantage value for an entire trajectory, and instead customizes the learning signal for each decision step $t$:
\[A_{\text{mod}}(i,t)=\underbrace{A^{(i)}\cdot g(H_{t}^{(i)})}_{\text{self-calibrated gradient scaling}}+\underbrace{\zeta\cdot f(H_{t+1}^{(i)})}_{\text{future clarity reward}}\]where $A^{(i)}$ is the final return advantage of trajectory $i$, and $H_{t}^{(i)}$ is the entropy at step $t$. This advantage function consists of two core components:
1. Self-Calibrating Gradient Scaling $g(H)$
This component is designed to correct the gradient-entropy coupling problem identified in the theoretical motivation above.
- Function: It amplifies or shrinks the base advantage signal $A^{(i)}$ according to the entropy $H_t$ of the current step.
- Design: It is implemented through a batch-normalized exponential function, ensuring that its mean over the mini-batch is 1. It only redistributes the signal without changing its total amount, thereby guaranteeing training stability.
- Advantages:
- For confident and correct steps (low entropy, $A^{(i)}>0$), $g(H) > 1$, so the gradient is amplified, accelerating learning.
- For confident but incorrect steps (low entropy, $A^{(i)}<0$), $g(H) > 1$, so the penalty is strengthened, effectively suppressing “hallucination-like confidence.”
- For uncertain steps (high entropy), $g(H) < 1$, so the gradient is attenuated, preventing noise from exploratory actions from interfering with policy updates and improving training stability.
2. Future Clarity Bonus $f(H)$
This component provides the agent with an intrinsic incentive to guide it toward more purposeful exploration.
- Function: It provides an additional reward signal whose magnitude is proportional to the confidence of the next step (low entropy).
- Design: It is a simple exponential function that encourages the agent to choose actions leading to future states with less ambiguity and greater predictability.
- Advantages: By encouraging the agent to actively seek clear solution paths and steer away from chaotic, high-entropy trajectories, it learns a general meta-skill: actively seeking certainty in ambiguous environments.
Algorithm Flow
The overall algorithm of EMPG is as follows:
- Collect Data: Run the current policy $\pi_{\theta}$ and collect a batch of trajectories.
- Compute Base Advantage: Compute a trajectory-level advantage value $A^{(i)}$ for each trajectory based on its final task outcome (success/failure).
- Compute Step-Level Entropy: Compute the entropy $H_t$ for all trajectories and all steps in the batch.
- Normalize and Compute Modulation Factors: Normalize the entropy within the batch, then compute the self-calibrating scaling factor $g(H_t)$ and the future clarity bonus $f(H_{t+1})$.
- Compute Modulated Advantage: Use the formula to compute $A_{\text{mod}}(i,t)$ for each step.
- Final Normalization: Perform batch normalization (zero mean) on all $A_{\text{mod}}$ to obtain the final advantage signal $A_{\text{final}}(i,t)$.
- Update Policy: Use $A_{\text{final}}$ as the advantage function and update the model parameters $\theta$ via policy gradient methods.
Experimental Results
The paper conducted extensive experiments on three challenging long-horizon agent benchmarks: WebShop, ALFWorld, and Deep Search. The results show that EMPG achieves significant and consistent performance improvements.
Main Results
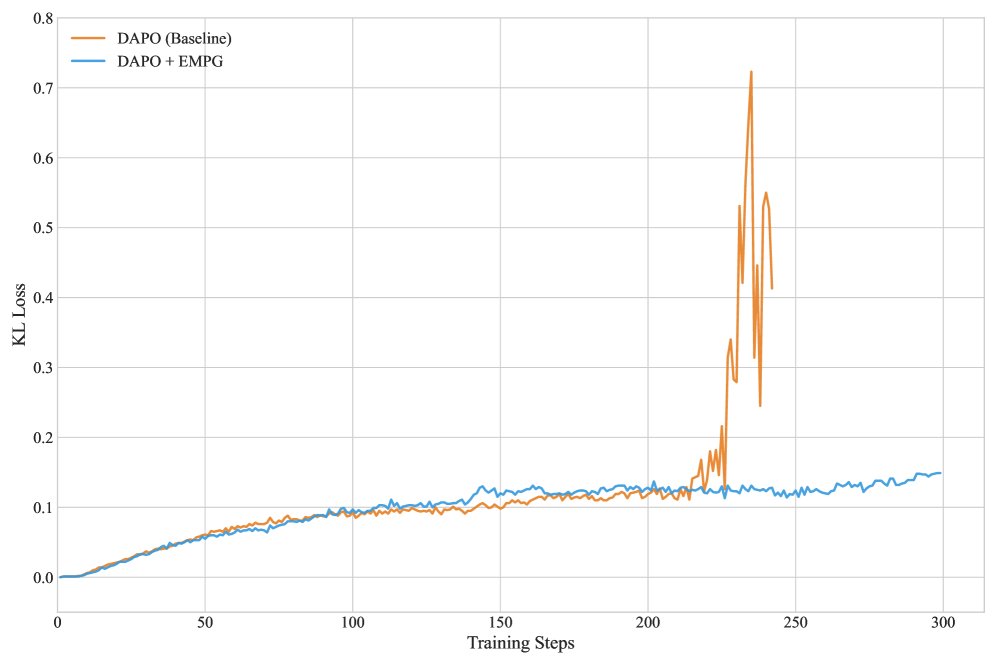
- Significant improvements over existing RL algorithms: On the ALFWorld and WebShop tasks (see Table 1), EMPG, as a plug-and-play module, can stably improve the performance of strong baselines such as GRPO and DAPO. For example, on the Qwen2.5-7B model, EMPG raises DAPO’s success rate on WebShop from 79.6% to 82.7%.
| Method | ALFWorld (All) | WebShop (Succ.) |
|---|---|---|
| Baseline: Qwen2.5-1.5B-Instruct | ||
| GRPO* | 65.6 | 58.2 |
| with EMPG* | 73.7 (+8.1) | 60.8 (+2.6) |
| DAPO* | 80.8 | 73.2 |
| with EMPG* | 88.1 (+7.3) | 73.8 (+0.6) |
| Baseline: Qwen2.5-7B-Instruct | ||
| GRPO* | 74.8 | 65.6 |
| with EMPG* | 78.5 (+3.7) | 69.3 (+3.7) |
| DAPO* | 90.0 | 79.6 |
| with EMPG* | 91.6 (+1.6) | 82.7 (+3.1) |
Table 1: A partial performance summary on the ALFWorld and WebShop tasks. EMPG brings improvements across different models and baselines.
- Scalability and generalization on complex tasks: On the more challenging Deep Search task (see Table 2), using the Qwen2.5-32B model, EMPG improves the average score of the DAPO baseline from 62.0 to 65.3. Notably, on the out-of-domain (OOD) test set, the performance gain from EMPG (+3.9) is higher than on the in-domain (ID) test set (+3.1), demonstrating its strong generalization ability.
| Method | ID Avg. | OOD Avg. | Overall Avg. |
|---|---|---|---|
| Qwen2.5-32B-Instruct | |||
| DAPO (baseline) | 63.5 | 59.8 | 62.0 |
| + Gradient scaling | 63.7 | 63.7 | 63.7 |
| + Future reward | 66.1 | 61.4 | 64.2 |
| + EMPG (this paper) | 66.6 (+3.1) | 63.7 (+3.9) | 65.3 (+3.3) |
Table 2: Main results and ablation studies on the Deep Search task.
In-depth analysis
-
Ablation study: The ablation experiments in Table 2 reveal the complementary roles of EMPG’s two components: the “future clarity reward” mainly improves performance on in-distribution (ID) tasks, playing a role in reinforcing exploitation of known patterns; the “self-calibrated gradient scaling” significantly improves generalization on unseen data (OOD tasks), playing a role in enhancing robustness. By integrating both, EMPG achieves a synergistic gain in both exploitation and generalization.
-
Training stability: Compared with the “policy collapse” that may occur in the later stages of the baseline DAPO method (with sharp KL divergence fluctuations), EMPG maintains a stable and low KL divergence throughout training, proving that its gradient modulation mechanism effectively prevents overly aggressive policy updates and ensures stable convergence.
- The necessity of step-level analysis: The analysis shows that, unlike previous token-level findings, at the step level of “thinking-action” even steps with very low initial entropy can undergo dramatic entropy changes after RL fine-tuning. This confirms the correctness of using “steps” as the basic unit for analysis and modulation, and is also a key motivation behind the design of EMPG.
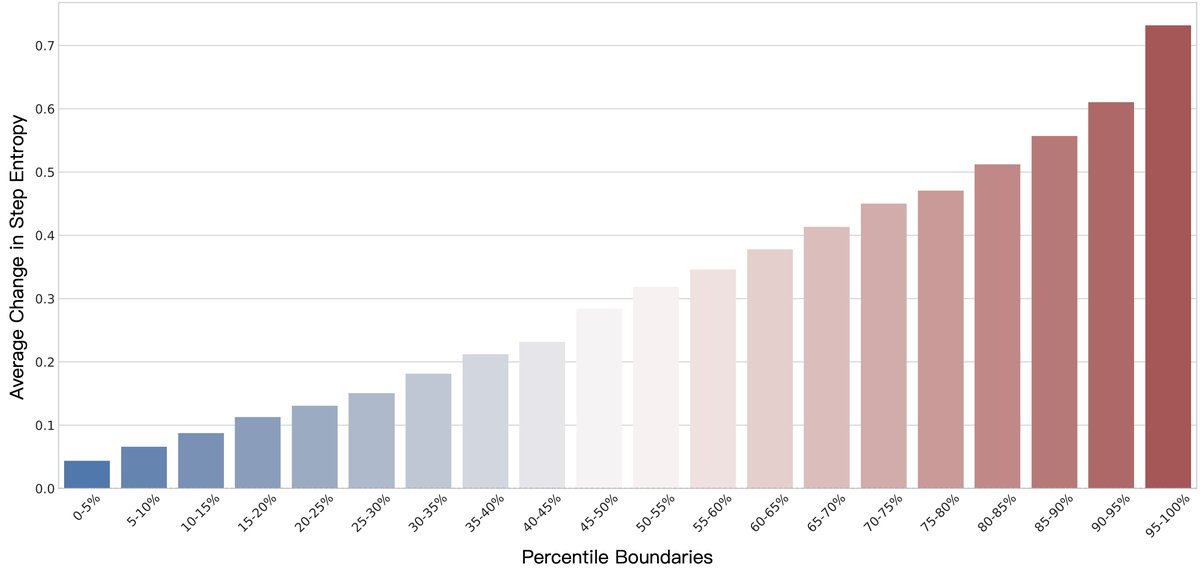
- Learning dynamics: The learning curves in the experiments show that baseline methods quickly hit a performance bottleneck and stagnate, whereas EMPG can continue learning and break through this bottleneck, ultimately converging to a higher performance level. This indicates that EMPG not only accelerates learning, but also guides the intelligent agent to discover better strategies that baseline methods cannot find.
Summary
EMPG is a theoretically grounded and general framework that successfully turns sparse final task rewards into dense, informative, and calibrated step-level learning signals by leveraging the intelligent agent’s own intrinsic uncertainty. Experiments show that, without introducing additional annotation costs, this method significantly improves the performance, stability, and generalization ability of LLM intelligent agents in long-horizon tasks, laying the foundation for developing more efficient and robust autonomous intelligent agents.