Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
-
ArXiv URL: http://arxiv.org/abs/2304.13712v2
-
Authors: Bing Yin; Qizhang Feng; Ruixiang Tang; Xia Hu; Haoming Jiang; Jingfeng Yang; Xiaotian Han; Hongye Jin
-
Publishing Institutions: Amazon; Rice University; Texas A&M University
TL;DR
This article is a comprehensive practical guide for practitioners and end users. It takes a deep dive into how to effectively use large language models (LLMs) to solve natural language processing (NLP) problems from three dimensions: models, data, and downstream tasks, and it also analyzes in detail the pros and cons of choosing LLMs versus fine-tuned models in different scenarios.
Practical Guide to Models
This section first provides an overview and observations on the development of modern language models, and then mainly divides them into two categories: BERT-style (encoder-decoder or encoder-only) and GPT-style (decoder-only).
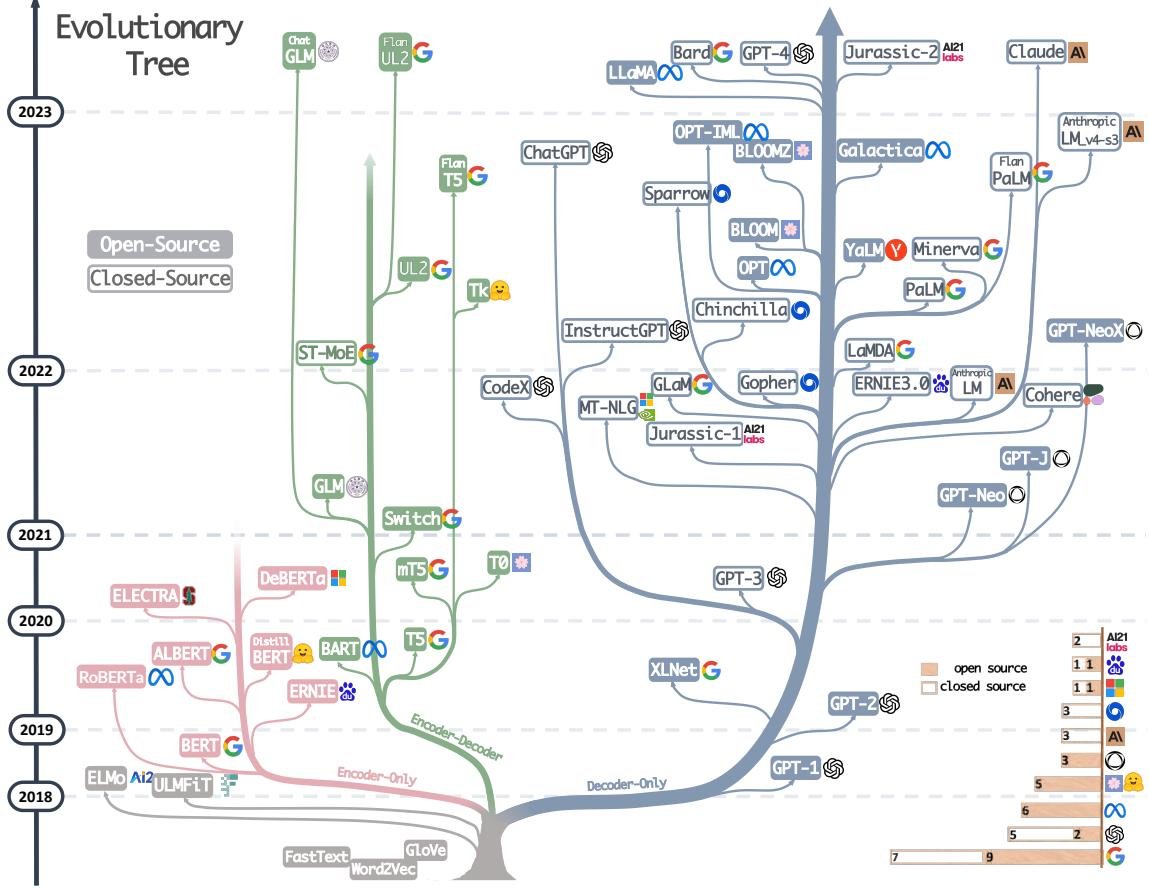 Figure 1. The evolutionary tree of modern LLMs. It traces the development of language models in recent years and highlights some of the best-known models. Models on the same branch are more closely related. Transformer-based models are shown in non-gray colors: the blue branch is decoder-only models, the pink branch is encoder-only models, and the green branch is encoder-decoder models. A model’s vertical position on the timeline represents its release date. Open-source models are shown as solid squares, while closed-source models are shown as hollow squares. The stacked bar chart in the lower right shows the number of models from different companies and institutions.
Figure 1. The evolutionary tree of modern LLMs. It traces the development of language models in recent years and highlights some of the best-known models. Models on the same branch are more closely related. Transformer-based models are shown in non-gray colors: the blue branch is decoder-only models, the pink branch is encoder-only models, and the green branch is encoder-decoder models. A model’s vertical position on the timeline represents its release date. Open-source models are shown as solid squares, while closed-source models are shown as hollow squares. The stacked bar chart in the lower right shows the number of models from different companies and institutions.
From the evolutionary tree in Figure 1, the following trends can be observed: a) Decoder-only models are gradually dominating the development of LLMs: In the early days, these models were less popular than encoder-decoder or encoder-only models. But since the release of GPT-3 in 2021, decoder-only models have seen explosive growth, while encoder-only models represented by BERT have gradually declined.
b) OpenAI remains the leader in the LLM field: Both in the past and now, OpenAI has consistently been at the forefront of developing models comparable to GPT-3 and GPT-4, and other institutions have found it difficult to catch up.
c) Meta has made outstanding contributions to open-source LLMs: Meta is one of the most generous contributors to the open-source community among commercial companies, and all of the LLMs it has developed have been open-sourced.
d) LLMs are trending toward closed source: Before 2020, most LLMs were open source. But since GPT-3, companies have increasingly preferred to keep their models closed source (e.g., PaLM, LaMDA, GPT-4), which has made model-training research more difficult for academia, and API-based research may become the mainstream.
e) Encoder-decoder models still have potential: Although decoder-only models seem more promising because of their flexibility and generality, encoder-decoder architectures are still being actively explored, and most of them are open source.
The table below summarizes the characteristics and representative models of these two types of models.
| Features | Representative LLMs | ||
|---|---|---|---|
| Encoder-decoder or encoder-only (BERT-style) | Training Model type Pretraining task | Masked Language Models Discriminative Predict masked words | ELMo, BERT, RoBERTa, DistilBERT, BioBERT, XLM, XLNet, ALBERT, ELECTRA, T5, GLM, XLM-E, ST-MoE, AlexaTM |
| Decoder-only (GPT-style) | Training Model type Pretraining task | Autoregressive Language Models Generative Predict the next word | GPT-3, OPT, PaLM, BLOOM, MT-NLG, GLaM, Gopher, Chinchilla, LaMDA, GPT-J, LLaMA, GPT-4, BloombergGPT |
BERT-style language models: encoder-decoder or encoder-only
The core training paradigm of this type of model is the Masked Language Model, in which some words in the input sentence are masked and the model is then asked to predict those masked words based on the context. This approach enables the model to deeply understand the relationships between words and between words and context. Models of this kind, such as BERT, RoBERTa, and T5, have achieved SOTA (State-of-the-art) results on many NLP tasks, such as sentiment analysis and named entity recognition.
GPT-style language models: decoder-only
These models are usually Autoregressive Language Models, trained by predicting the next word based on the preceding sequence of words. Research has found that scaling up these models significantly can greatly improve their performance in few-shot and even zero-shot settings. Models represented by GPT-3 demonstrate outstanding few-shot/zero-shot capabilities through prompting and in-context learning. A recent breakthrough is ChatGPT, which was optimized on top of GPT-3 for dialogue tasks, enabling more interactive, coherent, and context-aware conversations.
Practical Guide to Data
Data plays a crucial role in model selection and performance, and its impact runs through the entire process of pretraining, fine-tuning, and inference.
Core Viewpoint 1
(1) When facing out-of-distribution (OOD) data, such as adversarial examples and domain shift, LLMs have better generalization ability than fine-tuned models.
(2) When labeled data is limited, LLMs are the better choice; when labeled data is sufficient, either can be used, depending on the task requirements.
(3) It is recommended to choose models that have been pretrained on data from domains similar to the downstream task.
Pretraining Data
The quality, quantity, and diversity of pretraining data are the foundation of LLMs’ powerful capabilities and have a decisive impact on model performance. Pretraining data usually contains massive amounts of text from books, articles, websites, and more, aiming to instill rich vocabulary knowledge, grammar, syntax, semantics, and common sense into the model. Data diversity is also crucial. For example, PaLM and BLOOM perform well on multilingual tasks and machine translation because they include large amounts of multilingual data; GPT-3.5 excels at code generation because it includes code data. Therefore, when choosing an LLM, priority should be given to the similarity between its pretraining data and the downstream task.
Fine-tuning Data
Depending on the amount of labeled data available, there are three scenarios:
- Zero annotated data: In this case, directly using the zero-shot capability of LLMs is the best choice. LLMs usually outperform traditional zero-shot methods in zero-shot settings, and because model parameters are not updated, catastrophic forgetting can be avoided.
- Few annotated data: LLMs’ in-context learning ability stands out here. By including a few examples in the input prompt, LLMs can generalize effectively to new tasks, and their performance can even match that of fine-tuned SOTA models. In contrast, traditional few-shot learning methods, such as meta-learning, when applied to small models, may perform poorly due to model size and overfitting issues.
- Abundant annotated data: When there is a large amount of labeled data, both fine-tuning small models and using LLMs are viable. Fine-tuned models usually fit the data well, while LLMs may have an advantage when specific constraints, such as privacy protection, must be satisfied. The choice here should take performance, computational resources, and deployment constraints into account.
In summary, LLMs are more versatile in terms of data availability, while fine-tuned models are a reliable option when sufficient labeled data is available.
Test/User Data
In real-world deployment, there are often distribution differences between test data and training data, such as domain shifts, out-of-distribution variations, or adversarial examples. Fine-tuned models, having been fitted to a specific data distribution, tend to generalize poorly when facing these challenges. LLMs, by contrast, show stronger robustness because they have not undergone an explicit fitting process. In particular, LLMs trained with Reinforcement Learning from Human Feedback (RLHF) (such as InstructGPT and ChatGPT) have significantly improved generalization and perform well on most adversarial and OOD tasks.
Practical Guide to NLP Tasks
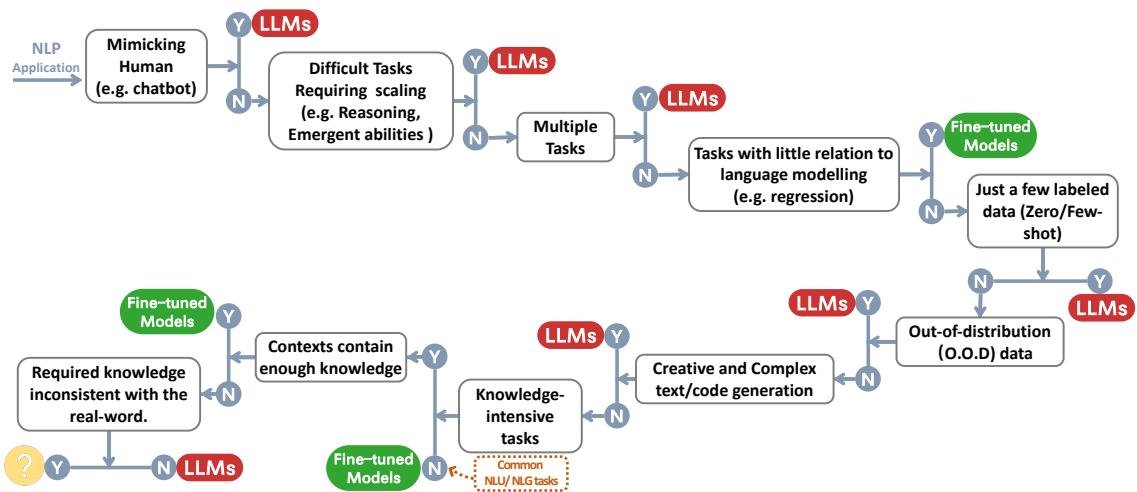
This section examines in detail where LLMs are and are not suitable across various NLP downstream tasks. The figure below provides a decision flowchart that can serve as a quick reference for model selection.
Traditional NLU Tasks
Traditional Natural Language Understanding (NLU) tasks include text classification, named entity recognition (NER), textual entailment, and so on, and are usually intermediate steps in larger AI systems.
Core Viewpoint 2
In traditional NLU tasks, fine-tuned models are usually the better choice, but LLMs can help when strong generalization is required.
- No use case: On most NLU benchmarks with sufficient, high-quality labeled data and little distribution shift between the test set and the training set (such as GLUE and SuperGLUE), fine-tuned models usually outperform LLMs.
- Text classification: On most datasets, LLMs lag slightly behind fine-tuned models. The gap is especially large in toxicity detection tasks, where LLMs perform poorly, while BERT-based fine-tuned models (such as Perspective API) do better.
- Natural Language Inference (NLI) and Question Answering (QA): On most datasets, fine-tuned models perform better.
- Information Retrieval (IR): LLMs have not been widely applied yet, because it is difficult to convert a large number of candidate texts into the few-shot/zero-shot format they are good at.
- Lower-level intermediate tasks (NER, dependency parsing): Based on existing evaluations, LLMs perform far worse than fine-tuned models on these tasks (such as CoNLL03 NER).
- Use case: When a task requires extremely strong generalization, the advantages of LLMs become clear.
- Miscellaneous text classification: For real-world classification tasks with diverse topics, unclear relationships, and formats that are hard to standardize, LLMs perform better.
- Adversarial NLI (ANLI): This is a difficult dataset built through adversarial mining, and LLMs show superior performance on it.
- These examples all demonstrate the excellent generalization ability of LLMs when handling out-of-distribution data and sparsely labeled data.
Generation Tasks
Natural Language Generation (NLG) tasks mainly fall into two categories: converting input text into a new symbol sequence (such as summarization and translation), and generating text “from scratch” in an open-ended way (such as writing emails, stories, or code).
Core Viewpoint 3
With strong generation ability and creativity, LLMs perform better on most generation tasks.
- Use case:
- Summarization: Although they do not lead on automatic metrics such as ROUGE, in human evaluations, summaries generated by LLMs are preferred for faithfulness, coherence, and relevance.
- Machine Translation (MT): LLMs excel at translating low-resource languages into English, thanks to the large amount of English text in their pretraining data. Multilingual pretrained models (such as BLOOM) perform well across a broader range of language pairs.
- Open-ended generation: LLMs are remarkably capable at generating news articles, novels, and code. For example, GPT-4 can solve a substantial portion of difficult LeetCode programming problems.
- No use case: In most high-resource and extremely low-resource translation tasks, specially fine-tuned models (such as DeltaLM+Zcode) still achieve the best performance.
Knowledge-Intensive Tasks
These tasks rely heavily on background knowledge, domain expertise, or world knowledge, going beyond simple pattern recognition.
Core Viewpoint 4
(1) Because they store massive amounts of real-world knowledge, LLMs perform well on knowledge-intensive tasks.
(2) When the knowledge required by a task does not match what the model has learned, or when the task only requires contextual knowledge, LLMs perform poorly; in such cases, fine-tuned models are equally effective.
- Use case:
- Closed-book QA: On tasks that require the model to recall factual knowledge (such as NaturalQuestions and TriviaQA), LLMs perform far better than fine-tuned models.
- Massive Multitask Language Understanding (MMLU): This is a challenging benchmark covering 57 subjects and requiring broad knowledge; the newly released GPT-4 achieved SOTA performance on this task.
- Some tasks in Big-bench: On certain tasks that require specific domain knowledge (such as Indian mythology or the periodic table), LLMs even outperform the human average.
- No use case:
- Tasks that only require contextual knowledge: For example, in Machine Reading Comprehension (MRC), the model only needs to understand the given passage to answer the question, and a small fine-tuned model can handle this as well.
- Tasks where the required knowledge conflicts with the model’s stored knowledge: When the task requirements conflict with or are unrelated to the model’s existing world knowledge (such as the “ASCII art digit recognition” or “mathematical symbol redefinition” tasks in Big-Bench), LLMs perform very poorly, even worse than random guessing.
- Scenarios where retrieval augmentation can be used: Through retrieval augmentation, the model can access an external knowledge base. In this “open-book” setting, a small fine-tuned model combined with a retriever can outperform LLMs without retrieval.
Capabilities Related to Scale
Scaling model size (such as parameter count and compute) greatly enhances the capabilities of language models. Some abilities, such as reasoning, evolve from being almost unusable to approaching human level as model scale increases.
Core Viewpoint 5
(1) As model scale grows exponentially, LLMs become especially strong in arithmetic reasoning and commonsense reasoning.
(2) As LLMs scale up, some unexpected abilities emerge, such as word manipulation and logical ability, which can be surprising in applications.
(3) Because our understanding of how LLM capabilities change with scale is limited, performance does not always improve steadily as scale increases in many cases.
- Use case: reasoning
- Arithmetic reasoning/problem solving: LLMs’ arithmetic reasoning ability improves significantly with scale. On datasets such as GSM8k, as general-purpose models, LLMs can already compete with specialized models, and GPT-4 surpasses all other methods. With Chain-of-Thought (CoT) prompting, their computational ability can be further improved.
- Commonsense reasoning: LLMs’ commonsense reasoning ability also improves steadily with scale, outperforming fine-tuned models on datasets such as StrategyQA. On ARC-C (elementary and middle school science questions), GPT-4’s accuracy is already close to 100%.
- Applicable Scenarios: Emergent Abilities Emergent abilities refer to capabilities that do not exist in small models and only suddenly appear after the model size exceeds a certain threshold. These abilities cannot be predicted by extrapolating the performance of small models.
- Word manipulation: such as reversing word spelling, word ordering, and letter rearrangement.
- Logical abilities: such as logical deduction, logical sequences, and logic grid puzzles.
- Others: advanced coding (e.g., automatic debugging), conceptual understanding, etc.
- Non-applicable Scenarios and Understanding
- Inverse Scaling Phenomenon: On some tasks, model performance decreases as model size increases. For example, LLMs perform poorly on tasks that require handling redefined mathematical symbols (Redefine-math).
- U-shaped Phenomenon: On other tasks, performance first decreases and then increases as model size grows. This phenomenon has been observed in tasks that evaluate whether a model ignores hindsight information (Hindsight-neglect).
- The causes of these phenomena are still being explored and may be related to the model’s overreliance on prior knowledge, the granularity of evaluation metrics, and the inherent complexity of the task. This suggests that when choosing a model, bigger is not always better.
Other Miscellaneous Tasks
This section discusses other tasks not covered previously, in order to more comprehensively understand the strengths and weaknesses of LLMs.
Core Viewpoint 6
(1) For tasks that differ greatly from LLMs’ pretraining objectives and data, fine-tuned models or specialized models still have their place.
(2) LLMs are excellent human imitators, data annotators, and generators. They can also be used for quality evaluation of NLP tasks and bring additional benefits such as interpretability.
- Non-applicable Scenarios (No use case):
- Regression tasks: LLMs perform poorly on regression tasks that predict continuous values (e.g., GLUE STS-B), and are inferior to fine-tuned RoBERTa models. This is mainly because their language-modeling pretraining objective does not match the objective of regression tasks.
- Multimodal tasks: LLMs are mainly trained on text data and have limited ability to handle tasks involving multimodal data such as images, audio, and video. At present, fine-tuned multimodal models such as BEiT and PaLI still dominate in areas like visual question answering (VQA) and image captioning.
- Applicable Scenarios (Use case):
- Human imitation and dialogue: LLMs represented by ChatGPT excel at imitating human conversation and can carry out coherent, reliable, and information-rich multi-turn exchanges.
- Data annotation and generation: LLMs can serve as high-quality annotators and generators for data augmentation, and the data they generate is even used to train other models.
- Quality evaluation: LLMs can act as evaluators for NLG tasks such as summarization and translation, and their evaluation results correlate highly with human judgments, though they may exhibit a bias toward LLM-generated text.
- Additional advantages: Certain capabilities of LLMs bring extra benefits, such as the chain-of-thought (CoT) reasoning process providing instance-level interpretability for model predictions.
Real-world “Tasks”
Real-world “tasks” usually do not have as clear a definition as those in academia; user inputs may be noisy, and task types are diverse and ambiguous.
Core Viewpoint 7
Compared with fine-tuned models, LLMs are better suited to real-world scenarios. However, how to effectively evaluate model performance in the real world remains an open question.
The challenges of real-world scenarios mainly come from:
- Noisy/unstructured input: User input may contain spelling mistakes, colloquial expressions, and mixed languages.
- Non-standardized tasks: User requests usually do not fall into predefined NLP task categories, and a single request may even contain multiple tasks.
- Following complex instructions: User instructions may contain implicit intent, requiring the model to understand the context and respond appropriately.
Because they are trained on diverse data, LLMs have stronger open-domain response capabilities and better handling of ambiguous, noisy input, making them more suitable than fine-tuned models designed for specific tasks to address these challenges. Techniques such as instruction tuning and human alignment tuning further enhance LLMs’ ability to understand and follow user instructions. Evaluating a model’s effectiveness in the real world is very difficult and relies mainly on expensive human evaluation, which is also an important research direction.
Other Considerations
Although LLMs perform strongly across a variety of downstream tasks, practical applications still need to consider other factors such as efficiency, cost, and latency.