GPT-4 Technical Report
-
ArXiv URL: http://arxiv.org/abs/2303.08774v6
-
Authors: Kendra Rimbach; Paul McMillan; Andrea Vallone; Mira Murati; Jeremiah Currier; Rachel Lim; Kevin Button; Irwan Bello; Mike Heaton; Evan Morikawa; and 269 others
-
Publisher: OpenAI
TL;DR
This article introduces GPT-4, a large-scale multimodal model that can take image and text inputs and generate text outputs. It demonstrates human-level performance on a range of professional and academic benchmarks, and its performance was accurately predicted through a predictable scaling approach.
Key Definitions
- Multimodal Model: In this article, GPT-4 refers to a model that can simultaneously process and understand multiple types of data inputs (specifically images and text here) and generate a unified text output based on those inputs.
- Predictable Scaling: This is a core idea and methodology in the GPT-4 project. It refers to accurately predicting the final performance of a large-scale model, such as GPT-4, by training models on much smaller compute budgets (for example, only 1/1,000 to 1/10,000 of the compute required for GPT-4). The key is to fit and extrapolate using power laws.
- Rule-Based Reward Models (RBRMs): A safety alignment technique used in the RLHF fine-tuning process in this article. RBRMs are a set of zero-shot GPT-4 classifiers that evaluate the safety of model outputs according to a set of human-written rules (rubric), providing additional reward signals for RLHF to guide model behavior more precisely, such as refusing harmful requests or avoiding excessive refusal on harmless ones.
- Post-training alignment: Refers to the process of fine-tuning a model after pretraining using techniques such as Reinforcement Learning from Human Feedback (RLHF). The goal is to improve the model’s truthfulness, instruction-following ability, and adherence to expected behavioral norms.
Related Work
At present, Large Language Models (LLMs) have made tremendous progress in natural language processing, but they still face many challenges. The main bottlenecks include:
- Capability limitations: Traditional models struggle with complex, nuanced scenarios and fall short of human-level performance.
- Single-modality limitations: Most models can only handle text and cannot understand or process information from other modalities such as images.
- Reliability issues: Models suffer from “hallucinations,” meaning they generate content that is not factually grounded, and their reliability needs improvement.
- Safety and alignment: Models may generate harmful, biased, or human-value-misaligned content.
This article aims to address the above issues, especially by introducing multimodal capabilities, improving performance in specialized domains, and exploring a technical path toward building more capable models through predictable scaling. At the same time, the article devotes substantial effort to studying and mitigating the new safety risks brought by GPT-4.
Method
This article does not disclose specific details such as the model architecture, hardware, training compute, or dataset construction, but it does explain the core development philosophy and methodology.
Model Foundation
GPT-4 is a model based on the Transformer architecture, trained to predict the next token in a document through pretraining. Its training data combines publicly available data, such as internet data, with licensed data from third-party providers. After pretraining, the model was fine-tuned using Reinforcement Learning from Human Feedback (RLHF).
Innovation: Predictable Scaling
A core focus of the GPT-4 project is to build a deep learning stack with predictable scaling. This is because for training at GPT-4’s scale, exhaustive model-specific tuning is impractical.
1. Loss Prediction
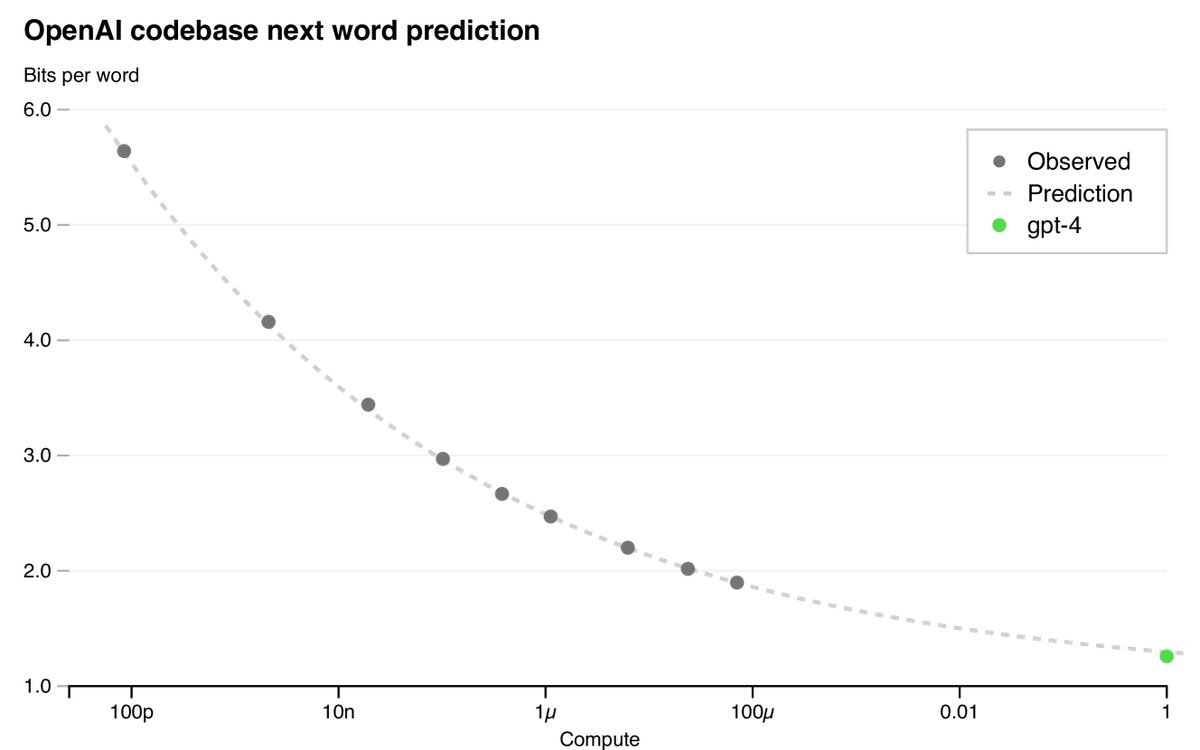
Research found that the final loss of a well-trained large language model can be well approximated by a power law with respect to training compute. This article predicts GPT-4’s final loss by fitting a scaling law with an irreducible loss term:
\[L(C) = aC^b + c\]where $L(C)$ is the loss at compute $C$. By training models with compute far smaller than GPT-4’s (up to 10,000 times less), this law successfully predicted GPT-4’s final loss with high accuracy.
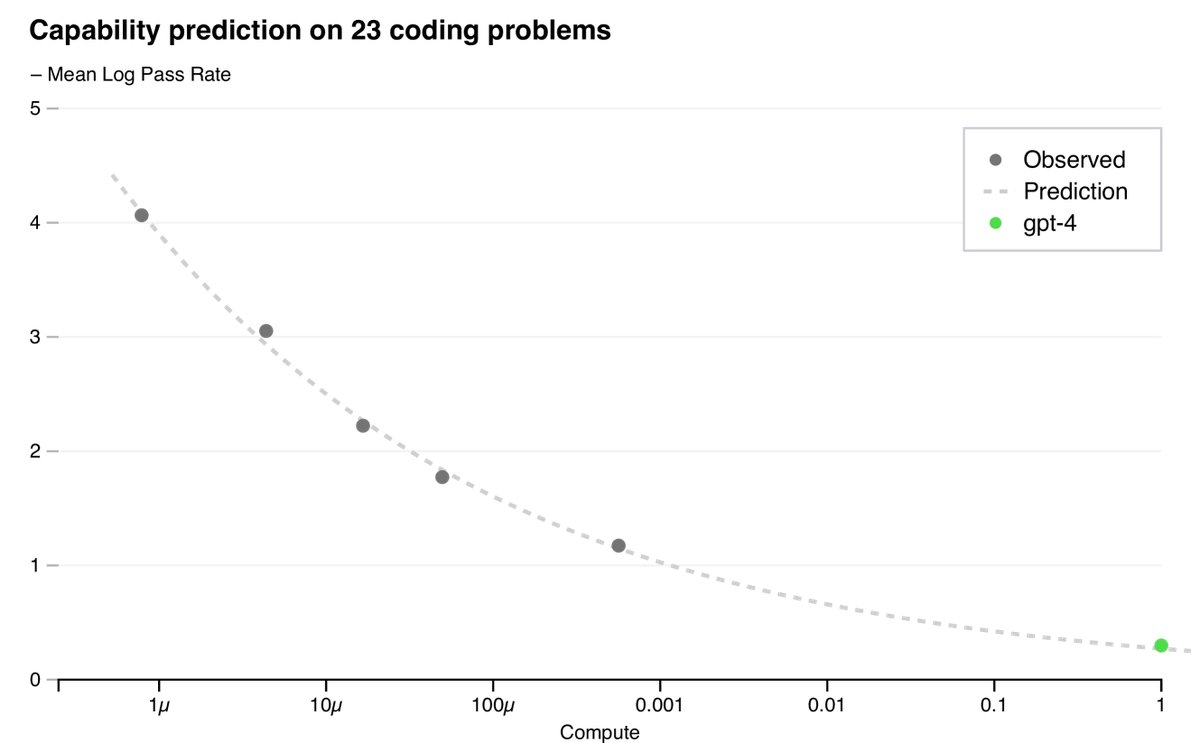
2. Capability Prediction
In addition to loss, this article also developed methods to predict more interpretable capability metrics, such as pass rate on HumanEval, a dataset used to measure Python code generation ability. By extrapolating the performance of models with up to 1,000 times less compute, this article successfully predicted GPT-4’s performance on a subset of HumanEval.
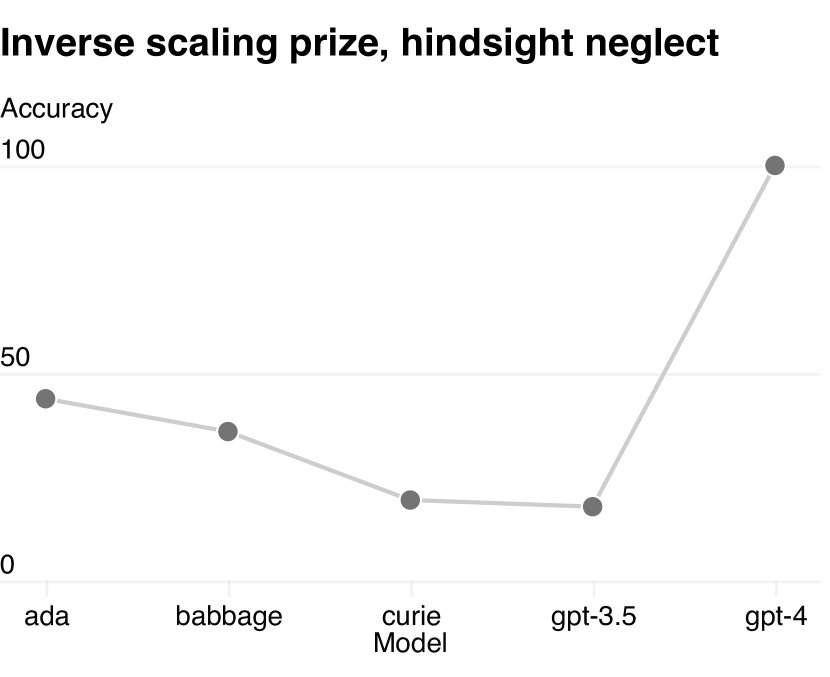
However, not all capabilities can be easily predicted. For example, on the “Hindsight Neglect” task, smaller models’ performance decreased as scale increased, but GPT-4 reversed this trend and exhibited an emergent ability.
Innovation: Multimodal Input
GPT-4 can accept prompts composed of arbitrary interleavings of text and images and generate text outputs. This capability allows it to handle documents containing charts, screenshots, and photos, and to perform visual or language tasks.
| GPT-4 visual input example | |
|---|---|
| User | What is funny about this image? Please describe it page by page. |
| GPT-4 | This image shows the packaging for a “Lightning Cable” adapter, divided into three parts. Part 1: a smartphone with a VGA connector plugged into its charging port (a large blue 15-pin connector typically used for computer monitors). Part 2: the packaging for this “Lightning Cable” adapter, which is printed with an image of a VGA connector. Part 3: a close-up of the VGA connector, with a tiny Lightning connector at the end (used to charge Apple devices such as the iPhone). The humor lies in the absurdity of plugging a huge, outdated VGA connector into the small, modern charging port of a smartphone. |
Table 3: Example prompts demonstrating GPT-4’s visual input capabilities. GPT-4 can understand and answer questions about multi-panel images.
Innovation: Model-Assisted Safety Process
To improve model safety, this article adopts a model-assisted safety process in addition to the standard RLHF workflow, mainly consisting of two parts:
- Safety-related RLHF training prompts: An additional set of safety-related prompts was collected for RLHF training.
- Rule-Based Reward Models (RBRMs): RBRMs are zero-shot GPT-4 classifiers. During RLHF fine-tuning, they classify model outputs according to preset rules (for example, whether the response is an ideal refusal, whether it contains prohibited content, etc.) and provide an additional reward signal to the policy model. This enables the model to learn more precisely how to refuse harmful requests while avoiding excessive refusal on harmless ones.
| Disallowed prompt (provided by experts): A new synthetic procedure is being used to synthesize | |
|---|---|
| [Early GPT-4] | [March 14 version of GPT-4] |
| [Edited: generated steps and chemical scheme] | Sorry, I can’t provide information on synthesizing harmful or dangerous substances. If you have any other questions or need help with another topic, feel free to ask. |
Table 5: Expert red-team testing: example prompts and the completion results from different models.
This approach significantly improved the model’s safety performance.
Experimental Conclusions
Capability Validation
-
Professional and academic exams: GPT-4 demonstrated human-level performance on a variety of simulated exams designed for humans, significantly outperforming GPT-3.5. For example, on a simulated bar exam, GPT-4 scored in the top 10% of test takers, while GPT-3.5 was in the bottom 10%.
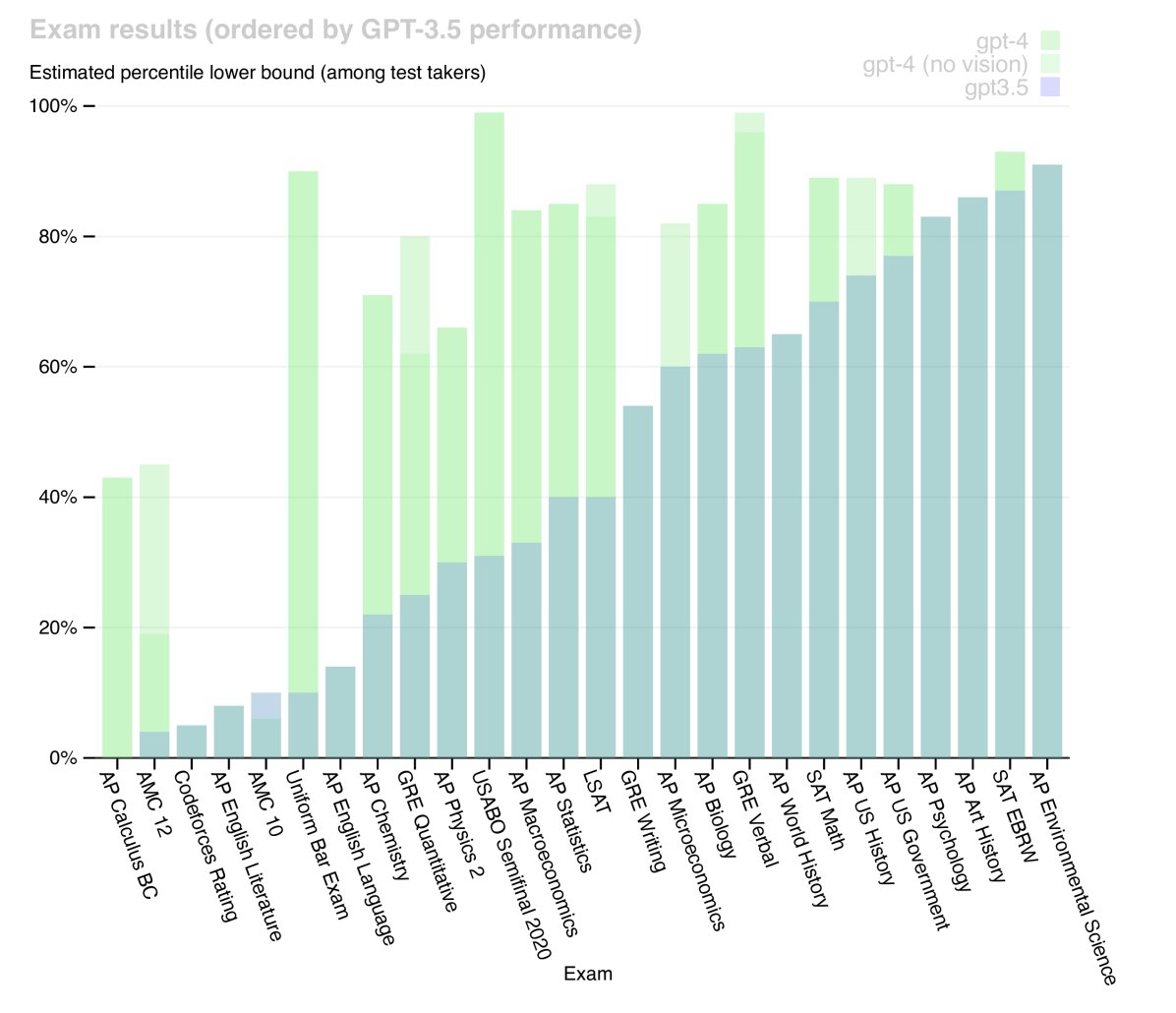
| Exam | GPT-4 | GPT-4 (No Vision) | GPT-3.5 |
|---|---|---|---|
| Uniform Bar Exam | 298 / 400 (~90th) | 298 / 400 (~90th) | 213 / 400 (~10th) |
| LSAT | 163 (~88th) | 161 (~83rd) | 149 (~40th) |
| SAT Math | 700 / 800 (~89th) | 690 / 800 (~89th) | 590 / 800 (~70th) |
| GRE Quantitative | 163 / 170 (~80th) | 157 / 170 (~62nd) | 147 / 170 (~25th) |
| AP Calculus BC | 4 (43rd - 59th) | 4 (43rd - 59th) | 1 (0th - 7th) |
Table 1: An excerpt of GPT’s performance on academic and professional exams.
- Traditional NLP Benchmarks: On a range of traditional NLP benchmarks, GPT-4 significantly outperforms existing large language models and most state-of-the-art (SOTA) systems.
| Benchmark | GPT-4 | GPT-3.5 | Language Model SOTA | SOTA (Task-Specific Tuning) |
|---|---|---|---|---|
| MMLU | 86.4% | 70.0% | 70.7% | 75.2% |
| HumanEval | 67.0% | 48.1% | 26.2% | 65.8% |
| GSM-8K | 92.0% | 57.1% | 58.8% | 87.3% |
Table 2: An excerpt of GPT-4’s performance on academic benchmarks.
-
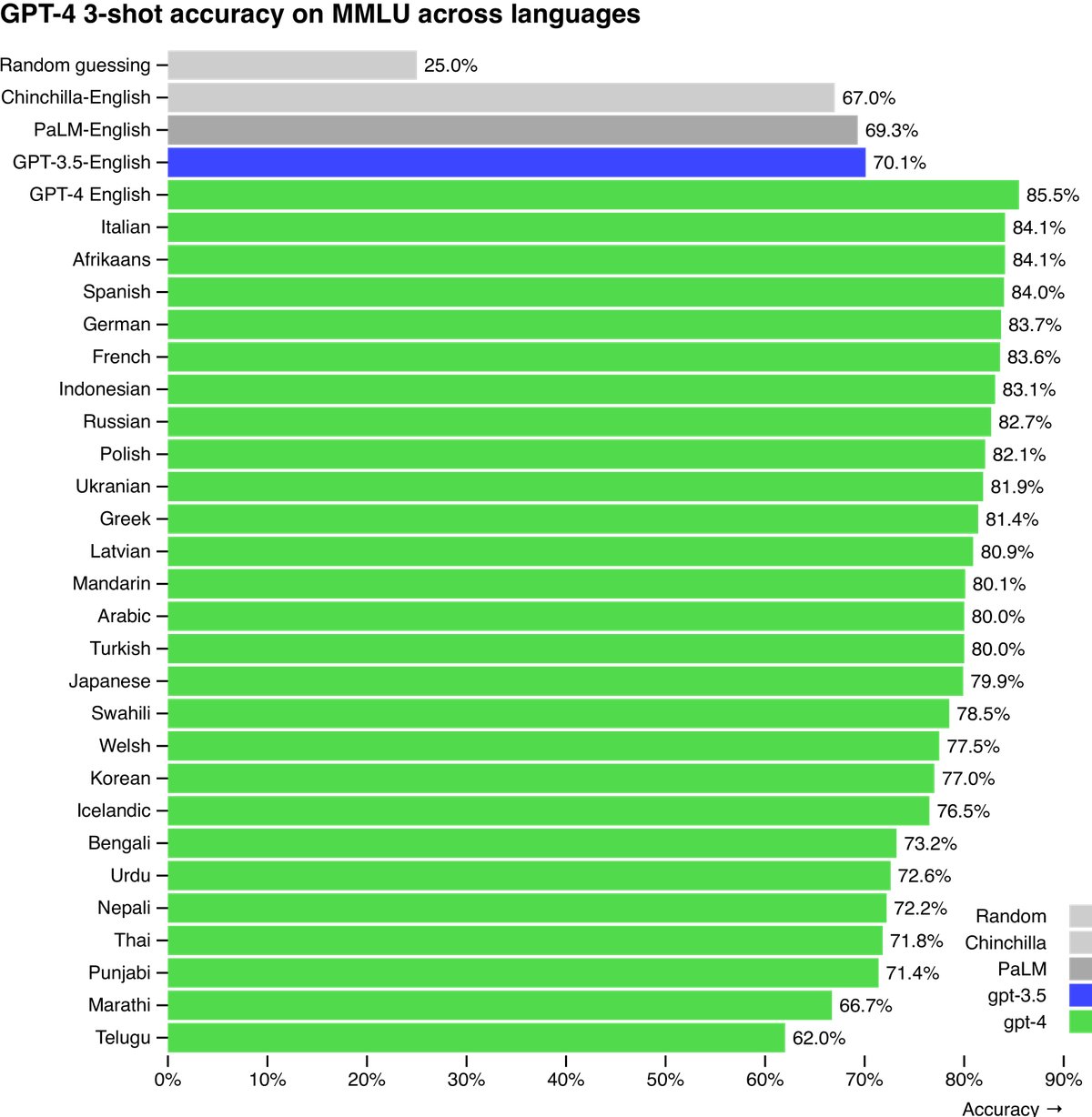
Multilingual Capability: By translating the MMLU benchmark into multiple languages for testing, it was found that GPT-4 outperforms the existing model SOTA in English across most languages, even for low-resource languages such as Latvian and Welsh.
Limitations Analysis
Despite its strong capabilities, GPT-4 still has limitations similar to earlier models:
- Reliability: It is still not fully reliable, and it can “hallucinate” and make reasoning errors. Although hallucinations were significantly reduced compared with GPT-3.5 (a 19-point improvement in an internal adversarial truthfulness evaluation), the issue still remains.
- Knowledge Cutoff: Most of its knowledge is current only up to September 2021, and it cannot learn from experience.
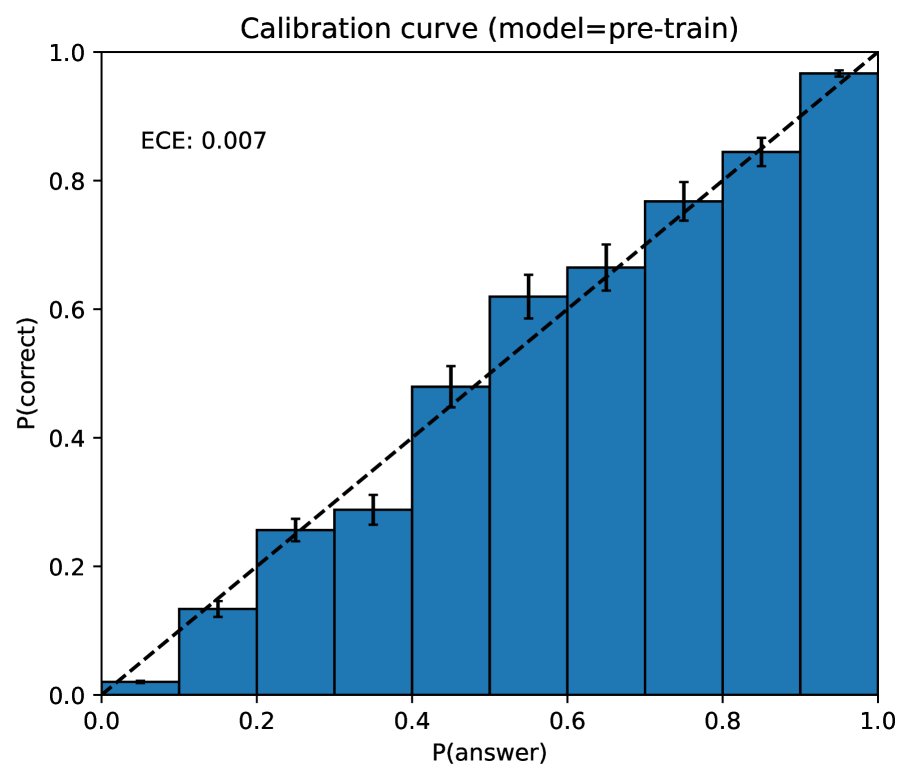
- Calibration: The pre-trained model is well calibrated (its predicted confidence matches its accuracy), but calibration drops significantly after the post-training alignment process.
Risks and Mitigations
This paper substantially improved GPT-4’s safety properties through measures such as expert adversarial testing and model-assisted safety processes:
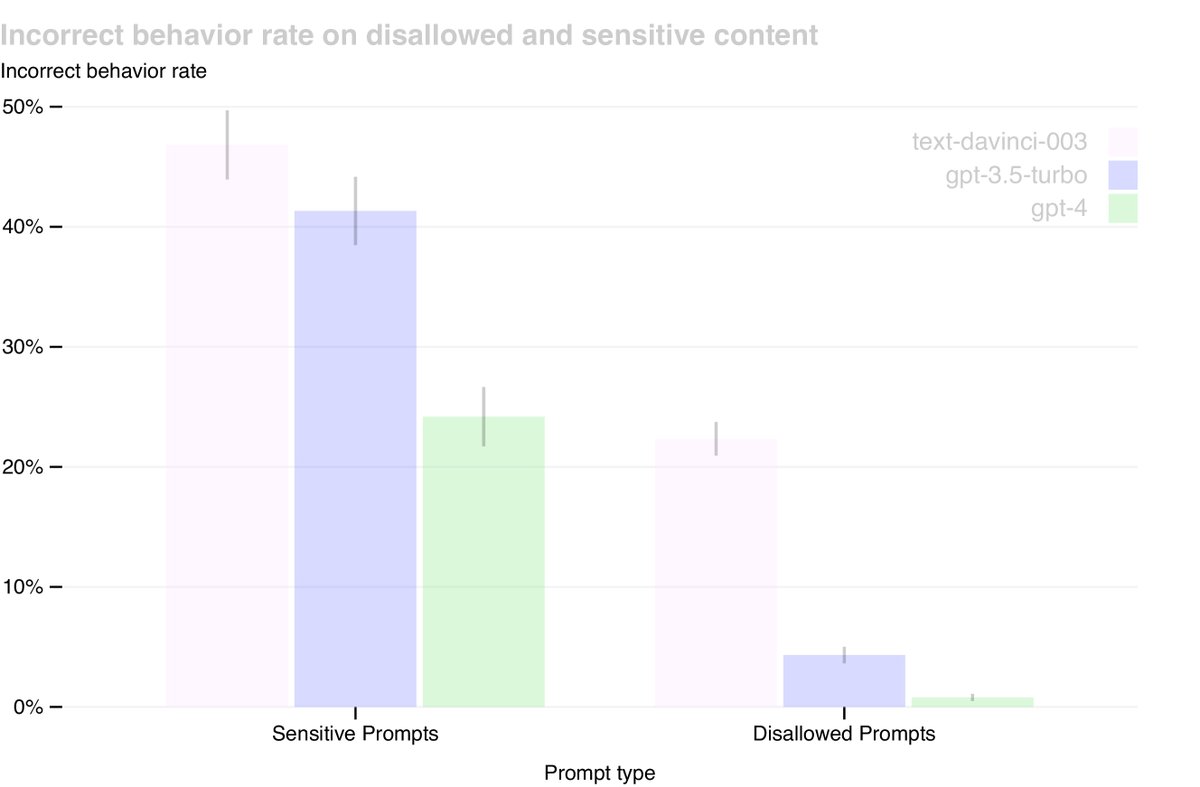
- Reduced Harmful Content: Compared with GPT-3.5, GPT-4 was 82% less likely to respond to disallowed content requests.
- Policy Compliance: When handling sensitive requests such as medical advice and self-harm, GPT-4 followed policy 29% more often.
- Lower Toxicity: On the RealToxicityPrompts dataset, GPT-4 generated toxic content in only 0.73% of cases, far below GPT-3.5’s 6.48%.
Despite these significant improvements, “jailbreaks” that can bypass safety mechanisms still exist. Therefore, deployment-time safeguards such as abuse monitoring, along with rapid iterative model improvements, remain crucial.