Generative Early Stage Ranking
Meta Reshapes Recommender Systems: GESR Breaks the Two-Tower Bottleneck with “Hybrid Attention,” Delivering a Big Performance Boost with Only 10% More Latency

Behind your feed app lies an ongoing trade-off between efficiency and effectiveness. The classic “two-tower model” has dominated for years because of its efficiency, but does it really understand you?
ArXiv URL:http://arxiv.org/abs/2511.21095v1
Recently, Meta researchers offered a disruptive answer: Generative Early Stage Ranking (GESR).
This technique not only significantly improves the core metrics of recommender systems, but also successfully deploys a complex attention mechanism under strict industrial-grade latency requirements.
This may be another major evolution in recommender system architecture after the two-tower model.
The “ceiling” of the two-tower model
In the multi-stage ranking pipeline of recommender systems, Early Stage Ranking (ESR) plays a crucial bridging role.
It needs to quickly filter hundreds of high-quality candidates from massive recall results and pass them to more refined downstream ranking models.
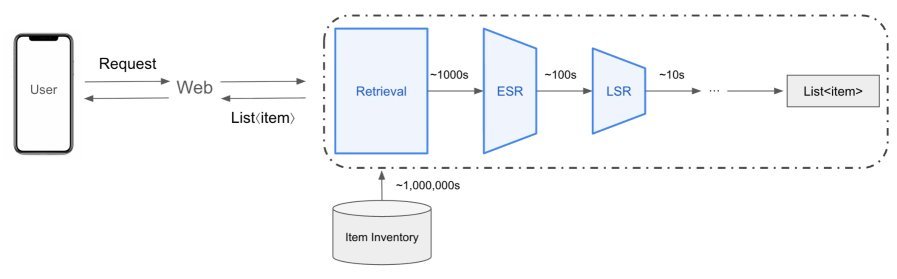
To balance efficiency and effectiveness, industry widely adopts a “user-item decoupled” two-tower architecture.
The user tower and item tower compute independently, and the final interest prediction relies only on a simple dot product. This design allows all item Embedding to be precomputed and cached, so online serving only needs to compute the user Embedding, making it extremely fast.
But the cost is severe: the model cannot capture fine-grained cross features between users and items.
For example, if you’ve recently been watching sci-fi movies, the system recommends you a sci-fi novel. The two-tower model is very hard-pressed to understand this cross-domain “sci-fi” thematic connection at an early stage.
The core of GESR: Mixture of Attention (MoA)
To break through this bottleneck, GESR does not abandon the two-tower model; instead, it adds a powerful new module alongside it: Mixture of Attention (MoA).
This module no longer keeps users and items “separated”; instead, it allows them to interact fully during the encoding stage.
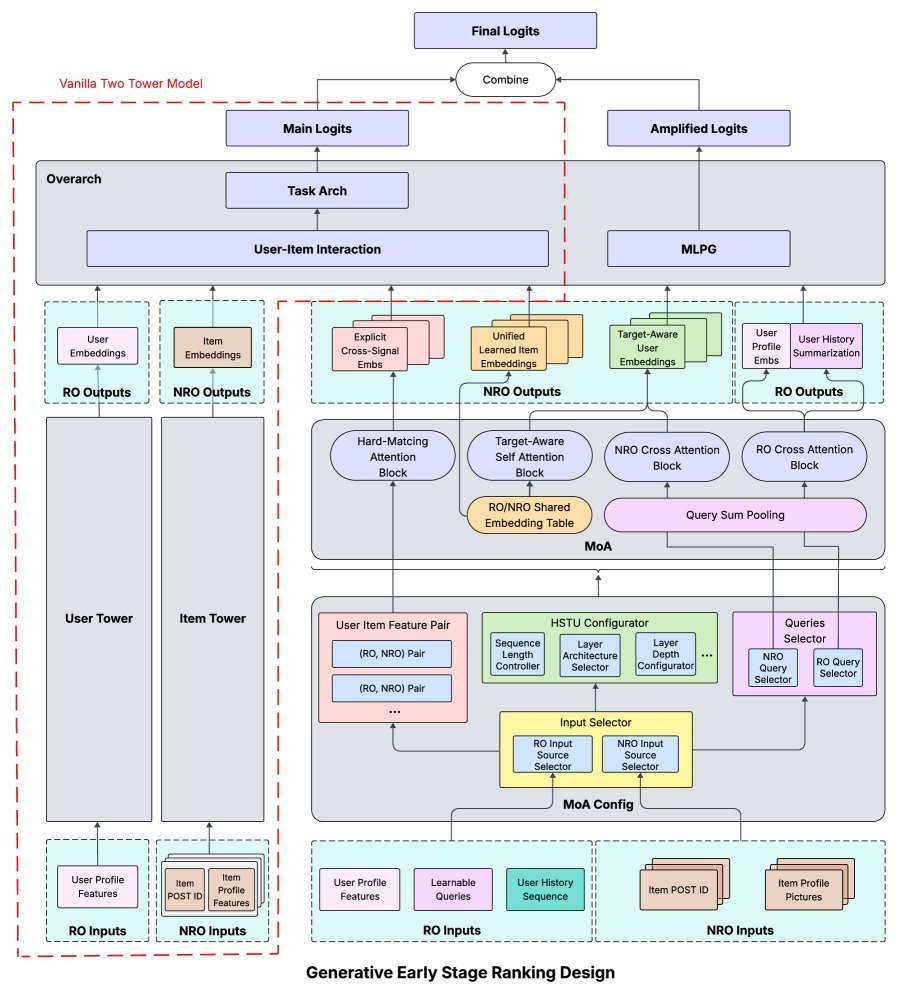
The MoA module acts like a “feature fusion master,” containing several carefully designed attention mechanisms:
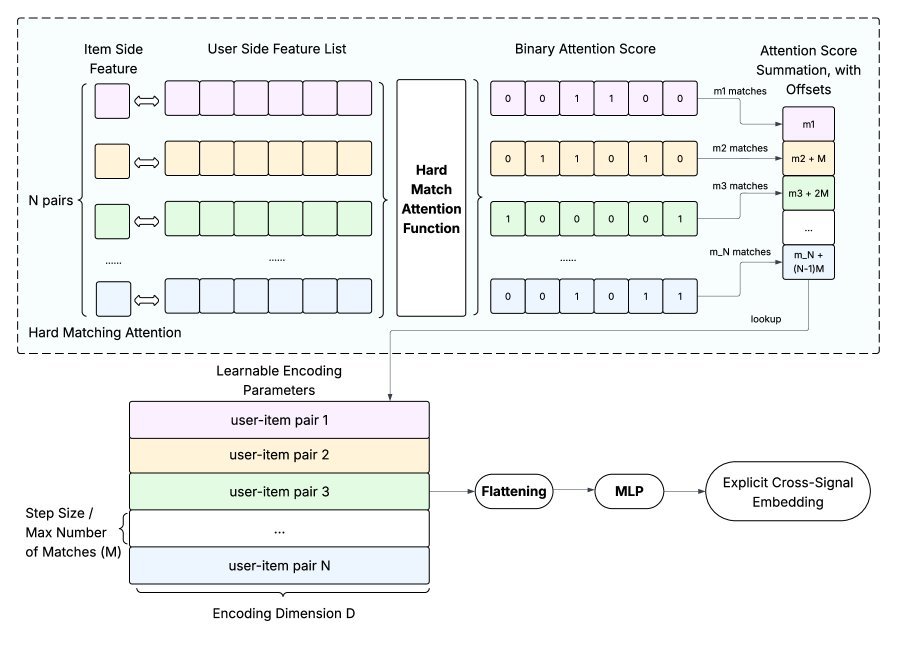
1. Hard-core matching: Hard Matching Attention (HMA)
The idea behind HMA is simple, direct, and effective: it directly computes the number of “matching items” between user historical behavior features and candidate item features.
For example, if 3 of the 10 videos a user watched were by the same creator as the candidate video, HMA will capture that signal of “3.”
This approach directly encodes explicit cross signals, is lightweight, and is highly interpretable.
2. Deep understanding: Target-Aware Self Attention
To capture deeper semantic associations, GESR introduces Target-Aware Self Attention.
It incorporates the candidate item’s information into the understanding of the user’s historical behavior sequence.
That means when analyzing your historical interests, the model looks at them “with a question in mind”: would the user be interested in this specific candidate item?
This makes the user representation more personalized and context-aware.
3. Efficiency supplement: Cross Attention
Self-attention is powerful, but its computational complexity is quadratic in sequence length, which is a challenge for long histories.
So GESR also introduces a Cross Attention module.
Its computational complexity grows linearly with sequence length, enabling symmetric interaction between user and item information at a lower cost and providing the model with richer fusion signals.
The finishing touch: Multi-Logit Parameterized Gating (MLPG)
With the rich cross features produced by the MoA module, how can they be used most effectively?
GESR designs a Multi-Logit Parameterized Gating (MLPG) mechanism.
Instead of simply concatenating all features and computing a single final score (Logit), it computes multiple independent $Logit_k$ in parallel.
More importantly, it introduces a gating mechanism that dynamically and selectively amplifies or suppresses the importance of different feature dimensions, achieving feature-level attention.
This ensures that the valuable signals painstakingly learned by MoA can deliver maximum value in the final scoring stage.
Performance guarantee: from FP8 to compiler optimization
Introducing such a complex attention model into early stage ranking poses one major challenge above all: latency.
Meta’s engineers responded with a combined strategy:
-
FP8 quantization: without retraining, quantize the parameters of large linear layers to 8-bit floating point, significantly reducing memory and compute overhead.
-
Torch Inductor optimization: use compiler techniques to deeply optimize the computation graph, enabling operator fusion and memory reuse to generate efficient low-level kernels.
-
Efficient serving architecture: retrieve item features efficiently during serving through an optimized caching mechanism, minimizing online computation as much as possible.
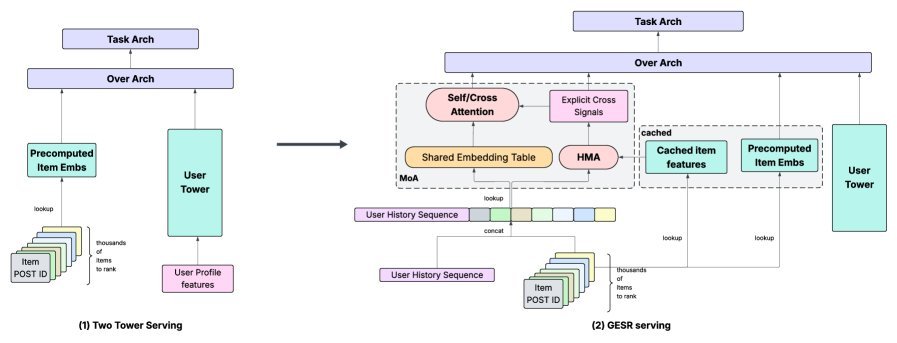
The final result is impressive: while model quality improved substantially, the QPS (queries per second) of GESR (advanced version) dropped by less than 10%, fully meeting the stringent requirements of online serving.
Experimental results: success both online and offline
Whether in offline evaluation (lower NE means higher prediction accuracy) or online A/B testing, GESR achieved remarkable success.
It not only improved the recommender system’s core top-line metrics, but also delivered clear gains in user engagement and consumption tasks.
As a result, this study became the first successful case of deploying full target-aware attention sequence modeling at such a large-scale early stage ranking setting.
Conclusion
The success of GESR shows that introducing richer user-item cross interactions at the early stage of recommender systems is key to breaking the current efficiency-effectiveness dilemma.
It does not completely overturn the mature two-tower paradigm; instead, through a clever “parallel” upgrade, it greatly unleashes the model’s expressive power while preserving efficiency.
This work not only offers new ideas for the design of large-scale recommender systems, but also suggests that in the future, the feeds on our phones will become even more “understanding” of us.