Generative Data Refinement: Just Ask for Better Data
-
ArXiv URL: http://arxiv.org/abs/2509.08653v2
-
Author: Edward Grefenstette; Will Ellsworth; Minqi Jiang; Sian Gooding
-
Publisher: Google DeepMind
TL;DR
This paper proposes a framework called “Generative Data Refinement” (GDR), which uses a pretrained generative model to rewrite raw datasets containing undesirable content, such as personal information or toxic content, into refined, high-quality datasets that are more suitable for model training, while preserving data diversity and utility.
Key Definitions
- Generative Data Refinement (GDR): A framework that uses a pretrained generative model to transform a dataset. For each sample in the dataset, it performs generative rewriting to remove unwanted content (such as personally identifiable information or toxic language) while retaining other useful information, thereby producing a “refined” dataset.
- Grounded Synthetic Data: Synthetic data generated based on, or conditioned on, real data samples. Unlike synthetic data generated entirely from scratch through prompting, the data produced by GDR is grounded synthetic data because it is created by modifying real data samples, which helps better preserve the diversity of real-world data.
Related Work
At present, the capabilities of large models are constrained by the quality and quantity of training data. As publicly indexed datasets are nearing exhaustion, researchers have begun to focus on the vast amount of unindexed user-generated content. However, directly using this data poses major risks, such as privacy leakage and the spread of toxic or copyrighted content.
To address this problem, existing methods mainly fall into two categories:
- Pure synthetic data generation: Using pretrained models to generate entirely new data. The main bottleneck of this approach is that the diversity of generated data is limited by the teacher model, making it prone to mode collapse, and the generated content may deviate from the distribution of real data.
- Differential Privacy (DP): Providing privacy protection by injecting noise into data or algorithms (such as DP-SGD). However, this comes at the cost of data utility, cannot solve the widespread data leakage problem in datasets, and significantly increases computational cost.
The core problem this paper aims to solve is: how to safely and efficiently use these risky but information-rich unindexed data, while avoiding the diversity loss of pure synthetic data generation and the utility loss of differential privacy.
Method
The core idea of the GDR framework is to redefine data cleaning as a “generative rewriting” problem. Instead of directly deleting or simply replacing undesirable content, it leverages the powerful understanding and generation capabilities of large language models (LLMs) to intelligently rewrite and refine each data sample.
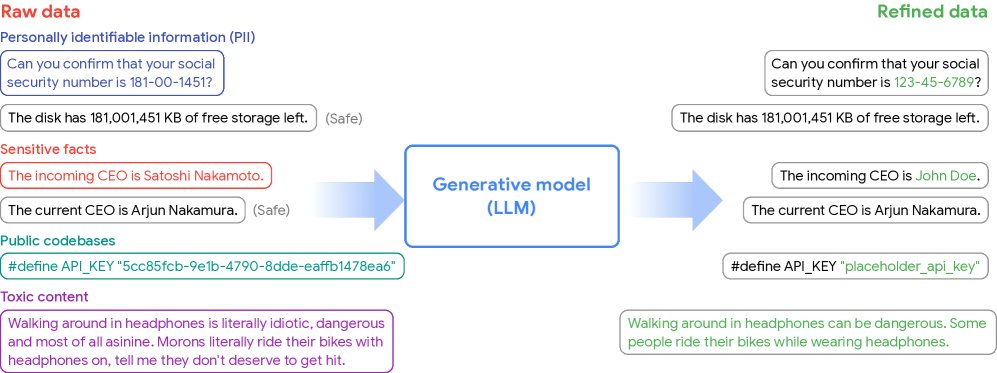 Figure 1: Overview of Generative Data Refinement (GDR). Raw data, which may contain personally identifiable information, toxic content, and so on, is fed into a pretrained generative model. Using its rich world knowledge, the model refines each sample, removing undesirable content while preserving other useful information, ultimately producing a refined dataset suitable for training.
Figure 1: Overview of Generative Data Refinement (GDR). Raw data, which may contain personally identifiable information, toxic content, and so on, is fed into a pretrained generative model. Using its rich world knowledge, the model refines each sample, removing undesirable content while preserving other useful information, ultimately producing a refined dataset suitable for training.
Essence of the Method
The formal definition of GDR is as follows: given a sample $x_i$ in a raw dataset $D$, the goal is to find a generative process $g$ (for example, a prompted LLM) such that the generated sample $y_i \sim g(\cdot \mid x_i)$ satisfies a specific criterion $h(y_i)=1$ (e.g., contains no harmful content) while minimizing the distance $\Delta(x_i, y_i)$ from the original sample.
This process essentially treats the LLM as an “intelligent noise operator.” Unlike the blind approach of adding Gaussian noise in differential privacy (DP), GDR uses the LLM’s contextual understanding to selectively and targetedly modify problematic parts of the data. For example, instead of simply replacing a name with \([REDACTED]\), it may replace it with a contextually relevant fictional name, thereby preserving the structure of the original sentence and the non-sensitive information as much as possible.
Innovations and Advantages
- Preserves data diversity: Because each GDR output is “grounded” in a real input sample, it can inherit the intrinsic diversity of real-world datasets. This effectively addresses the mode collapse problem common in traditional synthetic data methods, where generated content is highly repetitive and lacks diversity.
- Preserves data utility: By rewriting intelligently rather than deleting, GDR can retain most of the useful information in the original data. Experiments show that models trained on GDR-processed datasets can learn the public knowledge in the original data while effectively avoiding leakage of private or toxic content.
- General-purpose and easy to use: The GDR framework is highly general. By designing different prompts, the same powerful LLM can be used to perform a variety of data refinement tasks, such as data anonymization and content detoxification, and it can be applied to multiple data modalities, including text and code.
- Controllable cost: Although the initial inference cost for large-scale datasets may be high, this cost can be amortized because the refined dataset can be reused. More importantly, experiments show that by supervised fine-tuning (SFT) a small model or using few-shot prompting, it is possible to match or even exceed the performance of large models on specific tasks, thereby significantly reducing computational cost in practice.
Experimental Results
This paper validates the effectiveness of the GDR framework through experiments on two key tasks: data anonymization and content detoxification.
Data Anonymization (PII Removal)
- Performance surpasses industry standards: On a benchmark covering 108 PII categories, GDR (using zero-shot prompting with Gemini Pro 1.5) achieved an F-score of 0.88, far exceeding the 0.52 of a commercial detection and removal service (DIRS). GDR’s recall reached 0.99, while DIRS achieved only 0.53.
| Recall | Precision | F-score | |
|---|---|---|---|
| DIRS | 0.53 | 0.52 | 0.52 |
| GDR | 0.99 | 0.80 | 0.88 |
Table 1: Average precision, recall, and F-score for PII removal on more than 20,000 sentences across 108 PII categories.
-
Small models can do the job: Although large models perform better in zero-shot settings, after supervised fine-tuning a small 8B model (Flash 8B), its PII removal performance surpassed that of the unfine-tuned large model (Gemini Pro 1.5). This demonstrates that GDR is cost-feasible in practice.
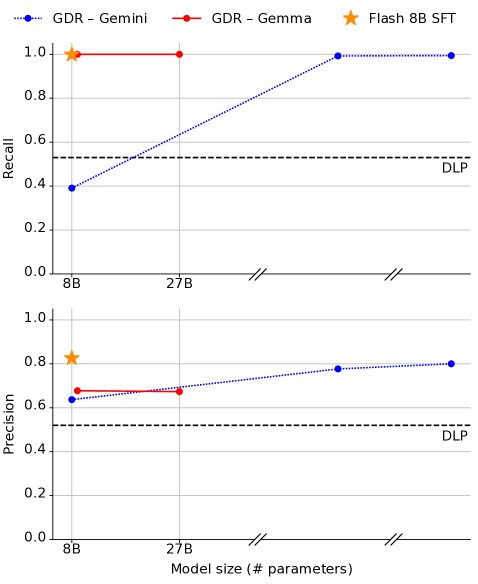 Figure 2: The impact of model size on GDR precision and recall on the PII benchmark. The fine-tuned Flash 8B (SFT) outperforms the larger Gemini Pro 1.5.
Figure 2: The impact of model size on GDR precision and recall on the PII benchmark. The fine-tuned Flash 8B (SFT) outperforms the larger Gemini Pro 1.5. -
Data utility is preserved: In a question-answering task involving synthetic company information, the model $M^{\prime}$ trained on GDR-refined data can accurately answer questions about public information (accuracy 0.25) while being completely unable to answer questions about private information (accuracy 0.00). In contrast, the model $M_{\text{DIRS}}$ trained on DIRS-processed data could not answer either type of question (accuracy 0.00 for both), demonstrating that GDR preserves data utility while removing privacy.
| $M$ (original) | $M_{\text{DIRS}}$ | $M^{\prime}$ (GDR) | |
|---|---|---|---|
| Public information accuracy $\uparrow$ | 0.32 | 0.00 | 0.25 |
| Private information accuracy $\downarrow$ | 0.26 | 0.00 | 0.00 |
Table 2: Answer accuracy of models fine-tuned on different datasets for public and private facts.
Large-Scale Code Anonymization
On a large code dataset containing 1.2 million lines of code, GDR shows much higher agreement with human expert annotations than DIRS. In particular, at the line level, DIRS’s low accuracy makes it unreliable, whereas GDR can precisely identify and rewrite PII, thereby completing anonymization without deleting large amounts of useful code.
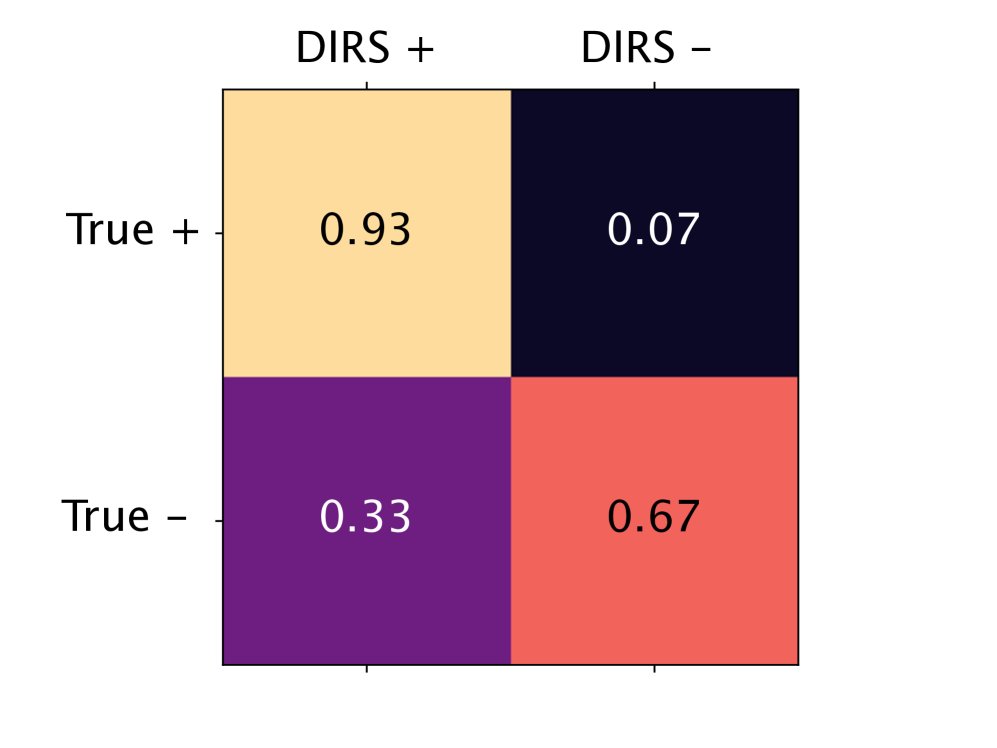
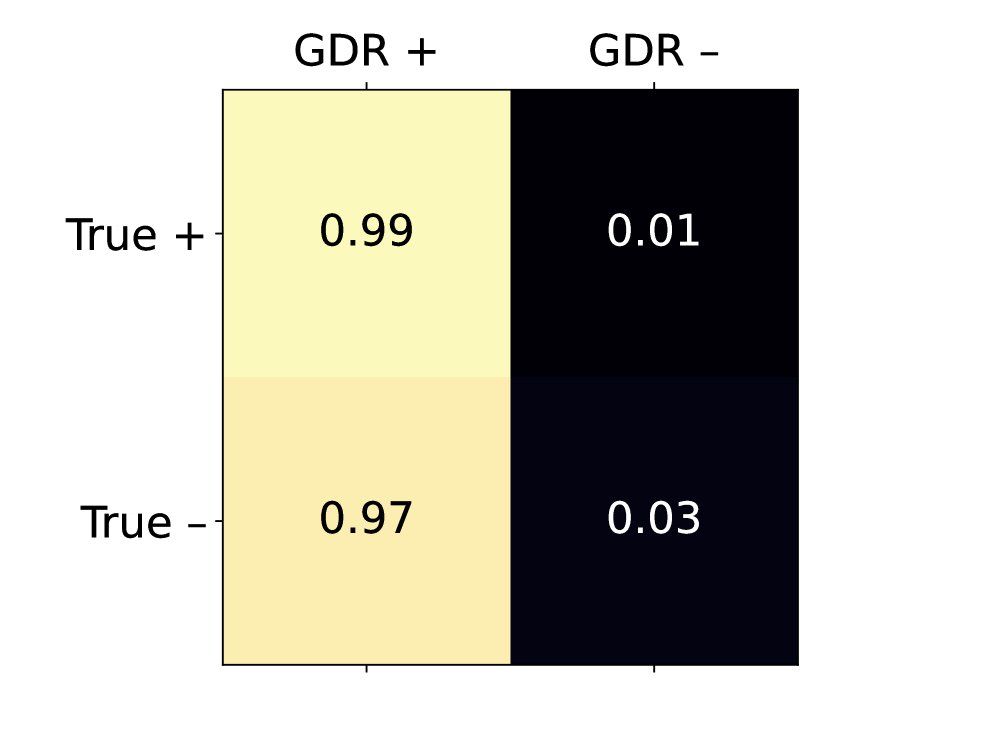 (a) Agreement with expert labels at the repository level
(a) Agreement with expert labels at the repository level
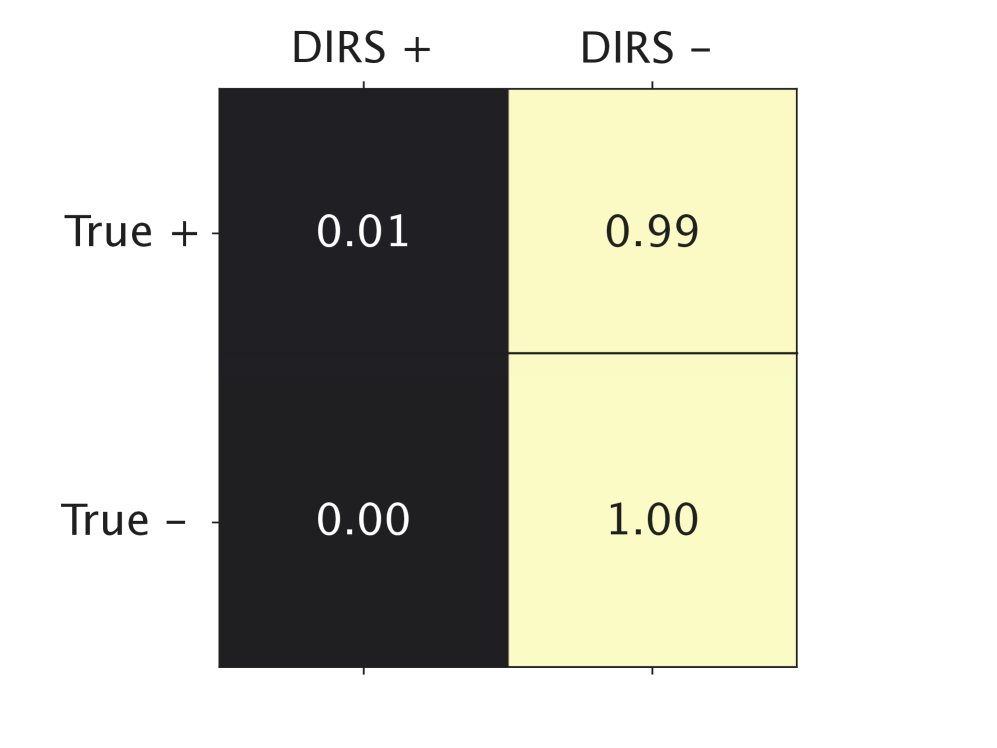
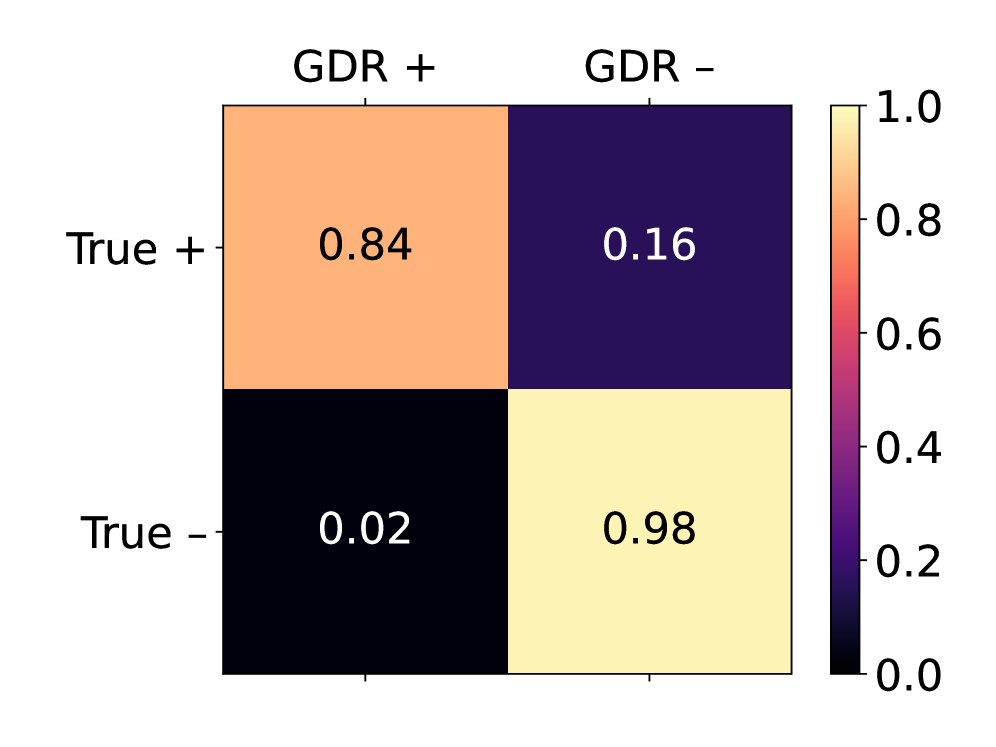 (b) Agreement with expert labels at the line level
(b) Agreement with expert labels at the line level
Figure 4: Confusion matrices of PII labels versus expert labels for DIRS and GDR across 479 code repositories. GDR performs significantly better than DIRS in true positives (TP) and true negatives (TN) at the line level (b).
Content Detoxification
-
Effectively reducing toxicity: GDR successfully reduced the average toxicity score of the highly toxic dataset from 4chan /pol/ (pol100k) from 0.19 to 0.13, even lower than the synthetic conversations generated by the baseline model itself (0.14).
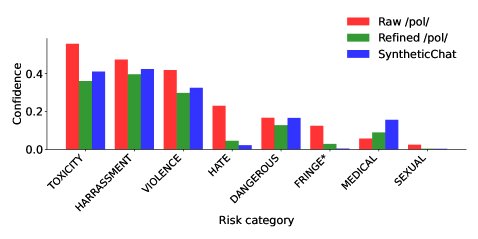 Figure 5: Distribution of toxicity scores for the original pol100k dataset, the GDR-detoxified dataset, and the baseline synthetic conversations.
Figure 5: Distribution of toxicity scores for the original pol100k dataset, the GDR-detoxified dataset, and the baseline synthetic conversations. -
Learning from toxic data: Models fine-tuned on the detoxified \(pol100k\) dataset improved accuracy from 0.88 to 0.92 on a question-answering task (pol5k-quiz) built from facts extracted from the original data. This shows that the model successfully learned useful world knowledge from toxic data.
Data Diversity
Compared with directly generated synthetic conversation data (SyntheticChat), the GDR-refined dataset (Refined pol100k) is comparable to the original real dataset (Raw pol100k) on diversity metrics (L2 distance and ROUGE-2 scores), and significantly outperforms the former. UMAP visualizations clearly show that the synthetic data suffers from obvious mode collapse, while the GDR-refined data covers a broad space similar to the real data.
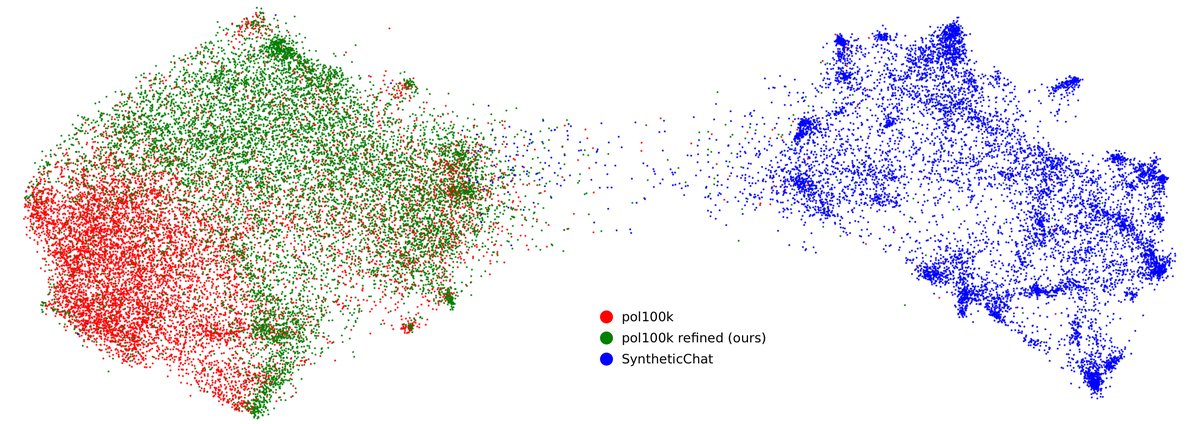 Figure 6: UMAP visualization of Gecko embeddings for 10,000 samples each from three types of data (synthetic conversations, original pol100k, and GDR-refined pol100k). The synthetic data (Synthetic) forms a dense cluster, indicating low diversity.
Figure 6: UMAP visualization of Gecko embeddings for 10,000 samples each from three types of data (synthetic conversations, original pol100k, and GDR-refined pol100k). The synthetic data (Synthetic) forms a dense cluster, indicating low diversity.
Summary
The GDR framework is a simple yet powerful tool that can effectively leverage existing large language models to clean and refine datasets containing undesirable content. By intelligently rewriting rather than simply deleting, GDR preserves the diversity and utility of the original data to the greatest extent while ensuring data safety, offering a highly promising path for scaling up the total amount of training data for frontier models.