General Agentic Memory Via Deep Research
AI Memory Revolution GAM: Replacing Static Compression with “Just-in-Time Research,” Achieving Over 90% Accuracy on Long-Text Tasks!

The memory of AI Agents is becoming a bottleneck to their intelligence.
ArXiv URL:http://arxiv.org/abs/2511.18423v1
Traditional memory methods are like cramming before an exam, trying to compress all knowledge into a single “cheat sheet.” This approach inevitably loses a great deal of detail, causing AI to “forget” when handling complex tasks.
What if AI could remember in a different way? Instead of rote memorization, it would act like a top-tier researcher, recording only key indexes in daily use and digging deeply into all materials only when needed.
Researchers from the Beijing Institute of Technology, The Hong Kong Polytechnic University, and Peking University have proposed a new framework called General Agentic Memory (GAM), which is built on this “just-in-time research” idea and fundamentally changes the way AI remembers.
Abandon “Ahead-of-Time” and Embrace “Just-in-Time”
Most current AI memory systems follow the Ahead-of-Time (AOT) principle.
They spend substantial compute in the offline stage to compress raw information into lightweight memory. The biggest problem with this approach is information loss—like making a summary of a book: no matter how detailed it is, it can never replace the original.
GAM, by contrast, borrows the Just-in-Time (JIT) idea from programming.
It does only the lightest work offline, and only at runtime—when a question needs to be answered—does it invest intensive computation to “deeply research” the current task and generate a customized, highly efficient context.
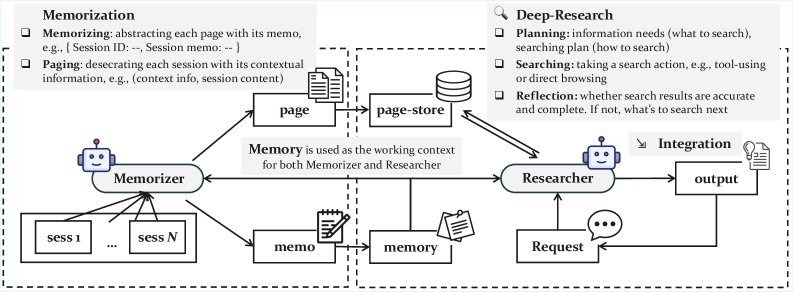
To achieve this, GAM designs an elegant two-part architecture: the Memorizer and the Researcher.
GAM’s Dual-Agent Collaboration Mechanism
At the core of GAM are two LLM-based agents that each handle their own responsibilities and collaborate efficiently.
1. Memorizer: The Offline Archive Manager
When the AI Agent’s historical information, such as conversations and action logs, flows in like a data stream, the “Memorizer” gets to work.
It does only two things:
-
Summarization: It generates a concise snapshot ($memo$) for the new information and incrementally updates it into a lightweight “memory index” ($memory$).
-
Lossless Archiving: It packages the original information together with the summary into a “page” ($page$) and stores it in a database called the “page-store” ($page-store$).
This process ensures that all historical information is preserved without loss, while also providing an index that can be retrieved quickly.
2. Researcher: The Online Deep Detective
When the user submits a request, the “Researcher” steps in. Unlike traditional methods that only look at summaries, it conducts a “deep research” process in the “page-store” based on the “memory index.”
This research process is iterative:
-
Planning: First, it analyzes the user request, thinks about what information is needed, and formulates a detailed search plan.
-
Retrieve & Integrate: It executes the search plan, retrieves relevant pages from the page-store, and integrates the information.
-
Reflection: It examines whether the collected information is sufficient to answer the question. If not, it generates new research directions ($r’$) and starts another round of planning, retrieval, and integration until the problem is perfectly solved.
This closed loop of “planning-retrieval-reflection” enables GAM to handle extremely complex problems that require multi-step reasoning.
Experimental Results: Comprehensive Outperformance of Existing Methods
So how does GAM perform in practice? The researchers validated it on several mainstream long-text and memory benchmarks, such as HotpotQA, RULER, and LoCoMo.
The results were impressive:
-
Leading performance across the board: GAM significantly outperformed all baseline methods in every test, including traditional RAG and long-context LLMs.
-
Tackling complex reasoning: On the RULER (MT) task, which requires multi-step information tracking, GAM achieved an accuracy of over 90%, while most baseline methods performed poorly on such tasks.
-
Resisting “context noise”: Experiments found that simply and crudely expanding an LLM’s context window (e.g., to 128K) does not guarantee better performance; too much irrelevant information can instead cause “context rot,” interfering with the model’s judgment. GAM effectively avoids this problem through its precise “research” process.
These results show that GAM’s “just-in-time research” paradigm is far more effective than static compression or endlessly expanding the context window.
A Deeper Look: The Key to GAM’s Success
A stronger “Researcher” is the key
The researchers found that GAM’s performance is closely tied to the capability of the “Researcher” agent. When the “Researcher” is equipped with a more powerful LLM (for example, upgrading from a 7B model to a 32B model), the system’s overall performance improves significantly.
Interestingly, the “Memorizer” is less sensitive to model size; even a small model can maintain decent performance. This suggests that the complex “research” process is where strong model capability is truly needed.
More “thinking time” leads to better results
One unique advantage of GAM is its test-time scalability. This means that when dealing with difficult problems, we can improve performance by increasing its “thinking time.”
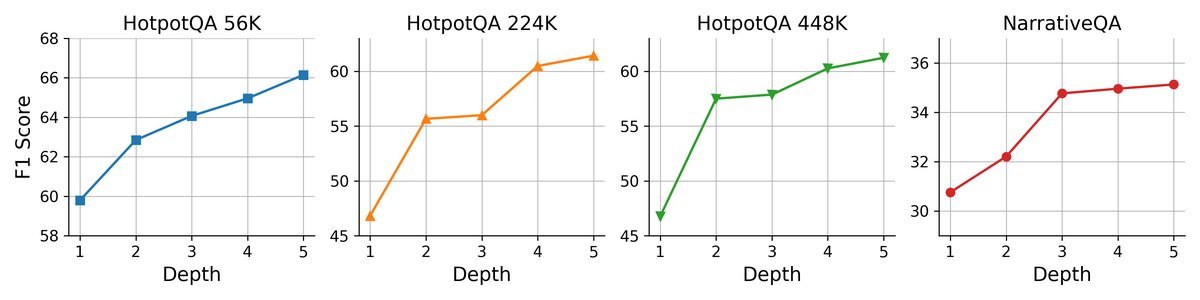
Left: Increasing reflection depth (allowing more rounds of research)
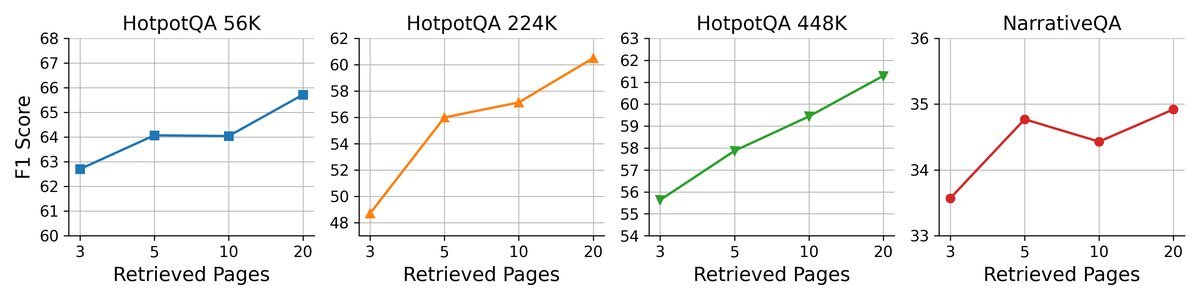
Right: Increasing the number of pages retrieved per round of research
Experiments show that whether you increase the “Researcher”’s reflection depth (number of iterations) or expand the number of pages retrieved in each round, performance gains are consistently achieved. This flexibility is something traditional fixed-pipeline methods do not have.
Balancing efficiency and effectiveness
Although it introduces a complex “deep research” process, GAM remains highly competitive in overall efficiency. Its online serving latency is comparable to that of existing mainstream memory systems, achieving an excellent balance between performance and cost.
Conclusion
The GAM framework offers a new and highly promising solution to the memory problem of AI Agents.
It abandons the inherent flaws of traditional memory systems caused by “information compression,” and by introducing the dual-agent collaboration mechanism of the “Memorizer” and the “Researcher,” transforms memory from static, lossy “ahead-of-time” processing into dynamic, lossless “just-in-time research.”
This not only allows AI Agents to use all of their historical knowledge more accurately and deeply, but also paves the way for building more powerful and more general AI agents in the future. Perhaps the secret to truly intelligent AI is not how much it can remember, but knowing where to look.