Gemma 2: Improving Open Language Models at a Practical Size
-
ArXiv URL: http://arxiv.org/abs/2408.00118v3
-
Authors: Anton Tsitsulin; Joana Carrasqueira; Xiang Xu; N. Devanathan; Matthew Watson; H. Dhand; Josh Lipschultz; Tomás Kociský; Se-bastian Krause; Lucas Dixon; and 185 others
-
Publisher: Google DeepMind
TL;DR
This article introduces the Gemma 2 family of open language models (2B, 9B, 27B). By interleaving local-global attention in the Transformer architecture, adopting grouped-query attention, and applying knowledge distillation to train the 2B and 9B models, it achieves the best performance at the same parameter scale and can even rival models that are 2-3 times larger.
Key Definitions
This article mainly combines and improves on existing techniques. Below are several core techniques that are crucial for understanding the method in this paper:
- Knowledge Distillation: A training strategy in which a smaller “student” model (such as Gemma 2’s 2B and 9B models) does not directly learn to predict the next token, but instead learns to imitate the output probability distribution of a larger, stronger “teacher” model. This provides the student model with richer gradient signals than standard one-hot labels, enabling better performance with the same amount of training data and simulating the effect of training on more data.
- Interleaving Local-Global Attention: A hybrid attention mechanism. The Transformer layers in the model architecture alternate between two attention modes: one layer uses Sliding Window Attention, focusing only on the most recent 4096 token; the next layer uses Global Attention, which can attend to the entire 8192-token context. This design aims to balance computational efficiency with the ability to capture long-range dependencies.
- Grouped-Query Attention (GQA): An attention variant that divides query heads into groups, with each group sharing a set of Key and Value heads. In this paper, \(num_groups\) is set to 2, meaning the number of KV heads is half the number of Q heads. This technique reduces memory usage and computation during inference while preserving model performance.
- Logit soft-capping: A technique for stabilizing training by using a \(tanh\) function to constrain the logits of the attention layers and the final output layer within a preset \(soft_cap\) range (50 for attention layers, 30 for the final layer). Its formula is: \(logits\) $\leftarrow$ \(soft_cap\) $\times \tanh(\text{logits} / \text{soft_cap})$.
Related Work
At present, performance improvements in small language models mainly rely on substantially increasing the amount of training data, but the returns from this approach follow a logarithmically diminishing pattern, meaning the gains become increasingly limited. For example, the latest small models require as many as 15T token to achieve a modest 1-2% performance improvement, indicating that existing small models are still under-trained.
The core problem this paper aims to solve is: how to find more effective ways to improve the performance of small language models without relying solely on massive increases in training data. The researchers explore replacing the traditional “next token prediction” task with richer training objectives, such as knowledge distillation, to provide the model with higher-quality information at each training step.
Method
The Gemma 2 model family is built on the decoder-only Transformer architecture of Gemma 1, but introduces several key architectural and training improvements.
Model Architecture
While retaining Gemma 1 features such as RoPE positional encoding and the GeGLU activation function, Gemma 2 introduces significant updates aimed at improving performance and efficiency.
- Deeper neural network: Compared with Gemma 1, Gemma 2 adopts a deeper network structure, and ablation experiments show that deeper models perform slightly better than wider models at the same parameter count.
- Interleaving Local-Global Attention: The model alternates between local sliding window attention (window size 4096) and global attention (range 8192) across different layers to balance efficiency and long-context modeling capability.
- Grouped-Query Attention (GQA): All models use GQA, with the number of KV heads set to half the number of query heads, speeding up inference without sacrificing performance.
- Dual normalization (Pre-norm & Post-norm): To stabilize training, both the input and output of each Transformer sublayer (attention and feed-forward network) are normalized with RMSNorm.
- Logit soft-capping: Logits are soft-capped in the self-attention layers and the final output layer to improve training stability.
The table below summarizes the key architectural parameters of Gemma 2 models at different sizes:
| Parameter | 2B | 9B | 27B |
|---|---|---|---|
| d_model | 2304 | 3584 | 4608 |
| Number of layers | 26 | 42 | 46 |
| Pre-norm | Yes | Yes | Yes |
| Post-norm | Yes | Yes | Yes |
| Nonlinearity | GeGLU | GeGLU | GeGLU |
| Feed-forward dimension | 18432 | 28672 | 73728 |
| Attention head type | GQA | GQA | GQA |
| Number of query heads | 8 | 16 | 32 |
| Number of KV heads | 4 | 8 | 16 |
| Head size | 256 | 256 | 128 |
| Global attention range | 8192 | 8192 | 8192 |
| Sliding window size | 4096 | 4096 | 4096 |
| Vocabulary size | 256128 | 256128 | 256128 |
| Tied word embeddings | Yes | Yes | Yes |
Pretraining
Gemma 2’s pretraining differs from Gemma 1 in several key aspects.
- Training data: The 27B model was trained on 13T token, the 9B model on 8T, and the 2B model on 2T. The data sources were mainly English web documents, code, and scientific literature. Data processing reused Gemma 1’s filtering techniques to reduce unsafe content, personal information, and evaluation set contamination.
- Knowledge Distillation: This is the core innovation in training the 2B and 9B models. Instead of using the traditional next-token prediction loss, they are trained by minimizing the negative log-likelihood of the output probability distribution from a teacher model (a larger language model). The objective function is as follows:
where $P_{S}$ is the student model’s probability distribution, $P_{T}$ is the teacher model’s probability distribution, and $x_c$ is the context. This method was used to “simulate training beyond the available number of token.” The 27B model still uses the traditional from-scratch training approach.
Post-training
To obtain instruction-tuned models, the paper applies a series of post-training steps to the pretrained models.
- Supervised Fine-Tuning (SFT): Fine-tuning on a mix of synthetic and human-generated “prompt-response” pairs.
- Reinforcement Learning from Human Feedback (RLHF): RLHF is performed using a reward model that is an order of magnitude larger than the policy model; the new reward model places more emphasis on multi-turn dialogue capability.
- Model merging: Averaging models trained with different hyperparameters to improve overall performance.
- Formatting: The instruction-tuned models use a new dialogue format, where the model explicitly uses the \(<end_of_turn><eos>\) sequence at the end of generation, rather than only \(<eos>\). This helps better manage multi-turn conversation flow.
Experimental Conclusions
Through extensive ablation studies and benchmark evaluations, this paper validates the advantages of Gemma 2 in both architecture and training methods.
Core Experimental Findings
- Effectiveness of knowledge distillation: Ablation experiments show that the 2B model trained with knowledge distillation (trained on 500B tokens) far outperforms the model trained from scratch (average score 67.7 vs 60.3). This confirms that knowledge distillation can significantly improve model quality, even when using far more than the compute-optimal number of tokens.
- Rationality of the architecture choice: The experiments show that, at the same parameter scale, a deeper network architecture is slightly better than a wider one. GQA performs similarly to multi-head attention (MHA) but is faster at inference.
- Pretrained model performance: Gemma 2 27B outperforms Qwen1.5 32B of comparable size across benchmarks, and shows strong competitiveness with LLaMA-3 70B, which is 2.5 times larger and trained on 2/3 more data. Thanks to knowledge distillation, Gemma 2 9B and 2B achieve performance gains of up to 10% on multiple benchmarks compared with Gemma 1.
The table below shows the performance of the pretrained models on several core benchmarks:
| LLaMA-3 70B | Qwen1.5 32B | Gemma-2 27B | |
|---|---|---|---|
| MMLU | 79.2 | 74.3 | 75.2 |
| GSM8K | 76.9 | 61.1 | 74.0 |
| ARC-c | 68.8 | 63.6 | 71.4 |
| HellaSwag | 88.0 | 85.0 | 86.4 |
Post-training Model Performance
- LMSYS Chatbot Arena: Gemma 2’s instruction-tuned models perform exceptionally well in human blind evaluations. Gemma 2 27B (Elo 1218) ranks above Llama 3 70B (Elo 1206); Gemma 2 9B (Elo 1187) is on par with GPT-4-0314 (Elo 1186); Gemma 2 2.6B (Elo 1126) ranks above GPT-3.5-Turbo-0613 (Elo 1116). This marks a new SOTA level for Gemma 2 among open models of the same scale.
- Human preference and multi-turn dialogue evaluation: In separate internal evaluations, Gemma 2 models show significant improvements over Gemma 1.1 in safety and instruction following, and also achieve much higher user satisfaction and goal completion rates in multi-turn conversations than the previous generation.
- Memorization and privacy: Gemma 2 has an extremely low memorization rate; whether measured by exact match or approximate match, its memorization rate is far below that of previous models, including Gemma 1.
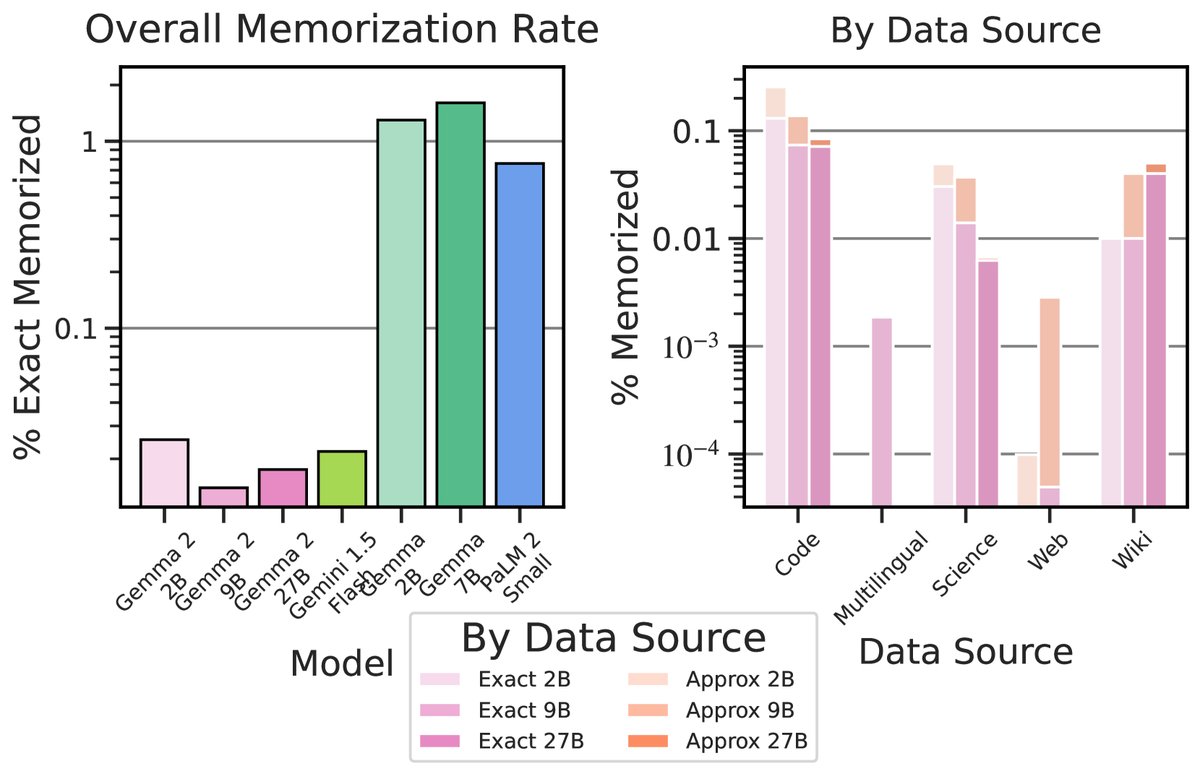
Final Conclusion
Through architectural improvements (such as interleaved attention) and innovative training methods (especially the large-scale use of knowledge distillation), Gemma 2 successfully delivers a substantial boost in overall model capability without significantly increasing model size. The experimental results show that Gemma 2 not only leads comparable open models on automated benchmarks, but also demonstrates strong competitiveness in human evaluations that reflect real-world applications, providing a powerful new tool for building practical, efficient, and responsible AI applications.