GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
GRPO Multi-Reward Training “Fails”? GDPO Decoupled Normalization: AIME Accuracy Improves by 6.3%
With the explosive rise of models like DeepSeek-R1, Group Relative Policy Optimization (GRPO) has almost become the standard for reinforcement learning (RL) fine-tuning. Everyone is using it to improve a model’s reasoning ability.
ArXiv URL:http://arxiv.org/abs/2601.05242v1
But when your requirements are no longer single-objective, and you want the model to be “accurate, concise, and format-compliant” at the same time, is it really okay to apply GRPO directly?
A research team from the Hong Kong University of Science and Technology and NVIDIA gave a negative answer. They found that in multi-reward scenarios, GRPO suffers from a serious “Reward Collapse” problem, which can lead to training failure. To address this, they proposed a new optimization method—GDPO. With a simple “decoupled normalization” strategy, it not only solves the collapse problem, but also delivers an accuracy gain of up to 6.3% on mathematical reasoning tasks (AIME).
Why Does GRPO “Collapse” in Multi-Reward Scenarios?
In real-world applications, we often want the model to satisfy multiple objectives at once. For example, in a “tool calling” task, we want the model to choose the right tool (accuracy reward) while also producing perfectly valid JSON (format reward).
The usual approach is to weight and sum these rewards, then hand the result to GRPO for optimization. However, the researchers found that this crude “sum first, normalize later” method loses a lot of information.
Let’s look at an intuitive example:
Suppose there are two rewards, $r_1$ and $r_2$.
-
Case A: The model performs very well, and both rewards are high.
-
Case B: The model performs very poorly, and both rewards are low.
-
Case C: The model is unbalanced, with one reward extremely high and the other extremely low.
Under GRPO’s mechanism, it first computes the total reward $r_{\text{sum}}$, then calculates the advantage within the group. The problem is that different reward combinations (such as “high + low” and “medium + medium”) can end up with the same total score.
Once the total score is the same, the normalized “advantage” in GRPO becomes identical as well. This means the model can no longer distinguish between “unbalanced” and “mediocre” cases, and the resolution of the training signal drops sharply. The paper calls this phenomenon Reward Collapse. It not only leads to suboptimal convergence, but in severe cases can even cause training to fail outright.
GDPO: Simplicity Is Beautiful, Decoupled Normalization
To solve this problem, the paper proposes GDPO (Group reward-Decoupled Normalization Policy Optimization).
GDPO’s core idea is very intuitive: keep each account separate first, then sum them up at the end.
Unlike GRPO, which normalizes the “total score” directly, GDPO decouples the normalization process:
-
Independent normalization: For each individual reward signal (such as accuracy, format, or length), normalize it separately within the group to compute its own advantage $A_1, A_2, \dots, A_n$.
-
Summation: Add these normalized advantage values together to obtain the total advantage $A_{\text{sum}}$.
-
Second normalization: To ensure numerical stability, perform one final batch-level normalization.
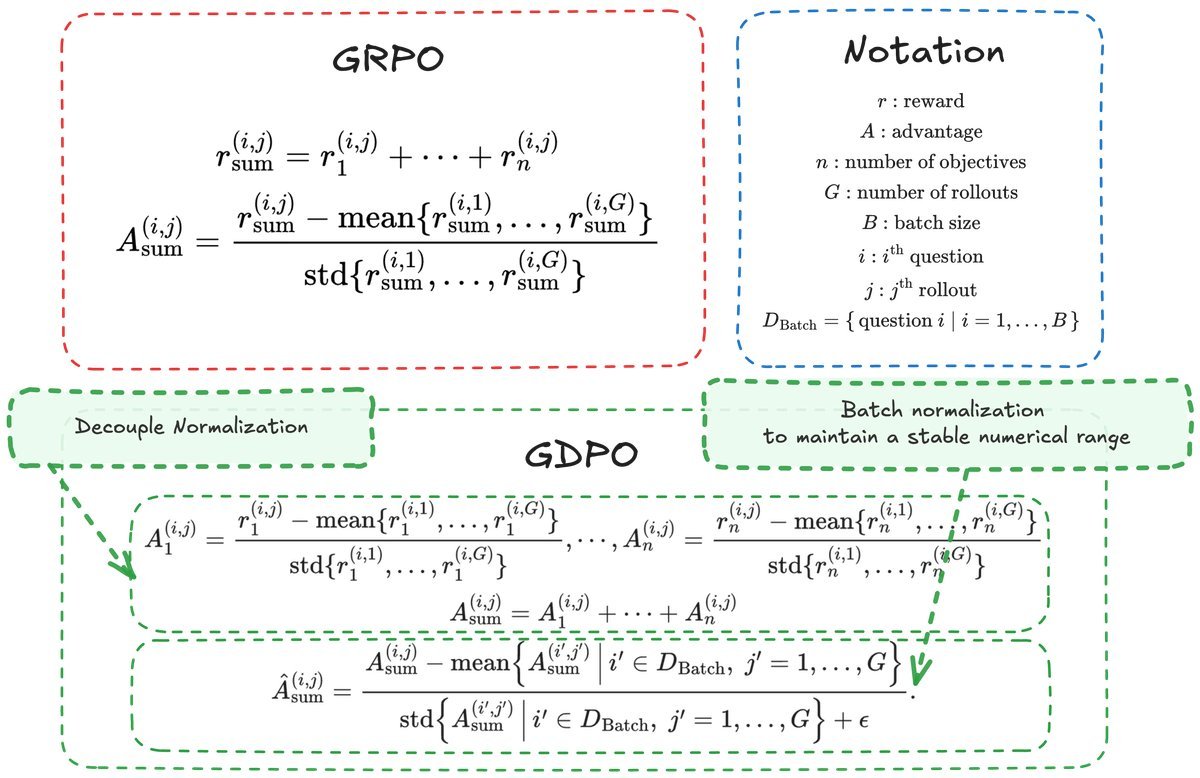
(a) GDPO overview: each reward is normalized independently within the group, preserving the relative differences among reward components.
In this way, GDPO can sensitively capture relative changes in different reward components. Even if two samples have the same total score, GDPO can still produce different gradient signals if their score compositions differ, thereby guiding the model toward a more fine-grained optimization direction.
Experimental Validation: GDPO Outperforms GRPO Across the Board
The research team compared GDPO and GRPO on three very different tasks: tool calling, mathematical reasoning, and code reasoning.
1. Tool Calling: Better Format and Accuracy
In the tool calling task, the model needs to optimize both “accuracy” and “format correctness.”
The experimental results show that when using the Qwen2.5-1.5B model, GDPO improved average accuracy by about 2.7% on the BFCL-v3 benchmark compared with GRPO, and improved format correctness by more than 4%.
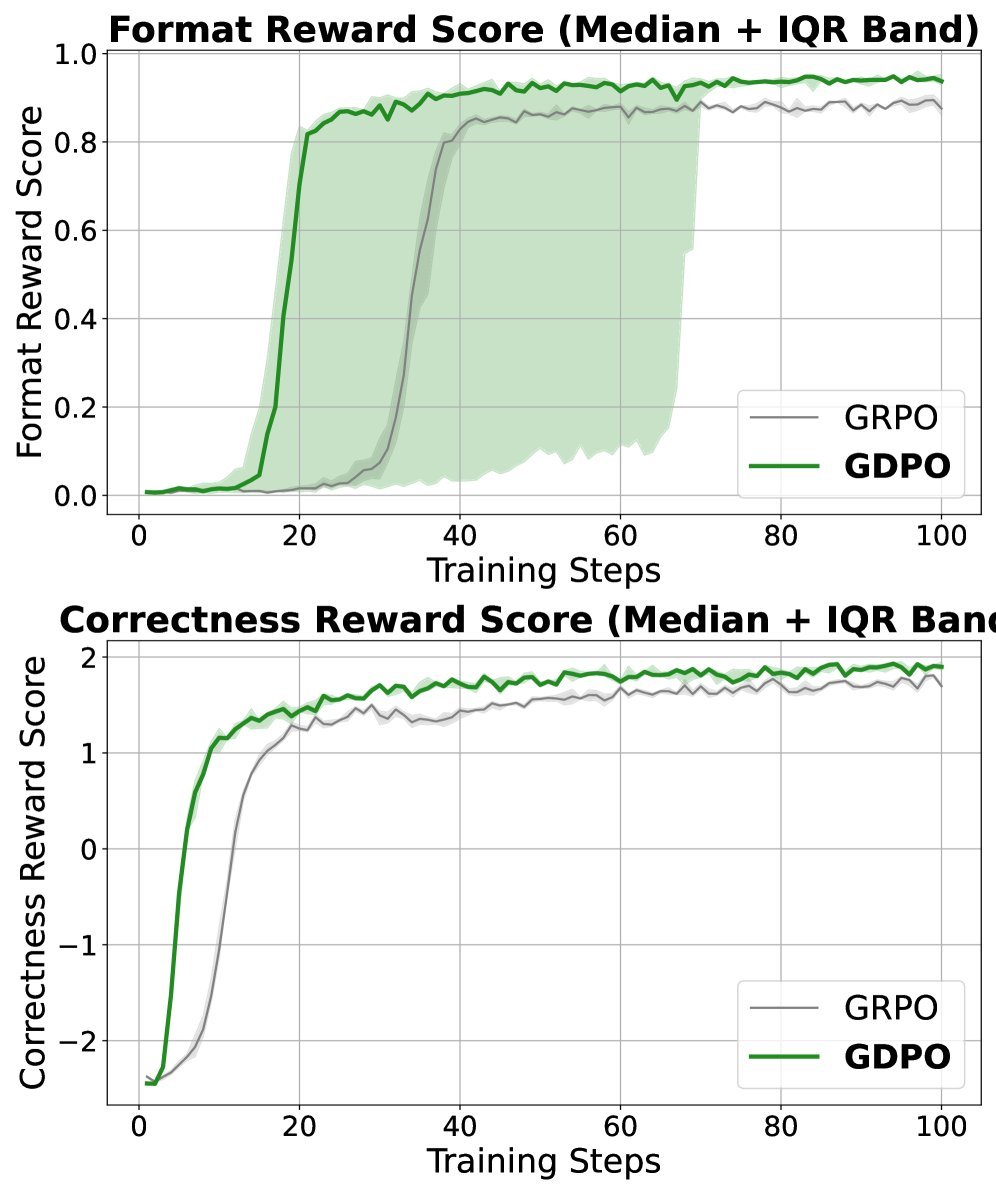
(b) Reward trend comparison: GDPO (blue) converges better and higher than GRPO (orange) on both correctness and format rewards.
2. Math Reasoning: Smart and Efficient
This is currently one of the most closely watched areas. The researchers trained DeepSeek-R1-1.5B/7B and Qwen3-4B on the DeepScaleR-Preview dataset. The goal was to improve problem-solving accuracy while limiting response length (the shorter, the better).
This is a classic “want both” conflict scenario. The results were impressive:
-
DeepSeek-R1-1.5B: On AIME competition problems, GDPO delivered an accuracy improvement of up to 6.7%.
-
DeepSeek-R1-7B: Accuracy on AIME improved by 2.9%, while the proportion of “overly long responses” dropped from 2.1% to 0.2%.
This shows that GDPO not only makes the model smarter, but also more obedient in following length constraints, achieving a perfect balance between accuracy and efficiency.
3. Coding: Three-Objective Optimization
In more complex code generation tasks, the researchers introduced three rewards: pass rate (Pass), length constraint (Length), and bug ratio (Bug Ratio).
Even with the complex trade-offs among three objectives, GDPO still came out on top, significantly reducing bug ratio and code length while maintaining a high pass rate.
Summary and Takeaways
This paper pours a dose of sober realism on today’s hot RL fine-tuning trend, while also offering a useful remedy. It reminds us: when introducing multiple reward signals in RL, do not blindly copy GRPO.
GDPO’s success shows that in multi-objective optimization, preserving the independent statistical properties of each objective is crucial. If you are trying to reproduce DeepSeek-R1’s results, or working on RLHF involving multi-dimensional preference alignment (such as safety + helpfulness), GDPO is definitely a more robust alternative worth trying.
Key Technical Points Recap:
-
Pain point: GRPO sums multiple rewards and then normalizes, causing different behaviors to produce the same advantage value (signal loss).
-
Solution: GDPO adopts a “normalize independently first, then sum” strategy.
-
Effect: It outperforms GRPO across tool calling, math, and coding tasks, with more stable training and higher metrics.