FLEX: Continuous Agent Evolution via Forward Learning from Experience
Let AI “learn from a setback” like humans: the FLEX framework boosts Agent performance by 23%
Current large-model Agents, while powerful, all share a kind of “amnesia”: once training is complete, they become static tools. Whether they succeed or fail on a task, they cannot learn from it, and when they encounter the same problem again, they still make the same mistakes. This is a far cry from the human way of learning, where people keep growing through experience.
Paper title: FLEX: Continuous Agent Evolution via Forward Learning from Experience
ArXiv URL:http://arxiv.org/abs/2511.06449v1
Now, researchers from ByteDance, Tsinghua University, and other institutions have proposed a brand-new learning paradigm — FLEX (Forward Learning with EXperience).
It completely overturns the traditional learning approach, enabling AI Agents to accumulate experience by reflecting on success and failure during interaction with the environment, and thus achieve continuous evolution.
Most importantly, this process requires no gradient backpropagation at all. It is extremely low-cost, yet it delivers performance gains of up to 23% on difficult problems across mathematics, chemistry, biology, and more!
The dilemma: why can’t today’s Agents “learn”?
We all know that AI models rely on Gradient Descent for learning, using backpropagation to fine-tune billions of parameters.
But for the continuous evolution of Agents, this process faces three major obstacles:
-
High cost: Backpropagation on large models requires enormous computing resources.
-
Catastrophic forgetting: When learning new knowledge, the model can easily forget old capabilities.
-
Closed models: Top-tier models like GPT-4 are closed-source, so we simply cannot access their parameters for fine-tuning.
Although some studies have tried to “evolve” models by modifying prompts or workflows, these methods are often task-specific, do not generalize across domains, and are hard to keep improving as experience accumulates.
FLEX: a new paradigm of forward learning
FLEX proposes a completely different idea: the focus of learning should not be on changing model parameters, but on building and using an evolvable “experience library.”
Traditional learning includes two processes: “forward propagation” and “backpropagation.”
FLEX simplifies learning into a purely forward process, divided into three stages:
-
Forward exploration: Boldly try to solve the problem and collect plenty of successful and failed experiences.
-
Experience evolution: A “updater” Agent reflects on the experiences, distills them, and updates the experience library.
-
Forward guidance: When solving new problems, retrieve relevant knowledge from the experience library to guide the reasoning process.
This paradigm brings three profound advantages:
-
Scalability: The experience library can keep growing, and AI performance improves as experience accumulates.
-
Inheritance: Experience is stored as structured text, so it can be easily “plugged and played” across different Agents without starting from scratch.
-
Cross-task transfer: High-level strategies learned from one task can be used to solve other tasks.
Core mechanism: a two-level MDP and an experience library
To realize this elegant idea, FLEX designs a sophisticated mechanism that can be understood as a clearly divided “strategic command center.” The study formalizes it as a hierarchical Markov decision process (Meta-MDP).
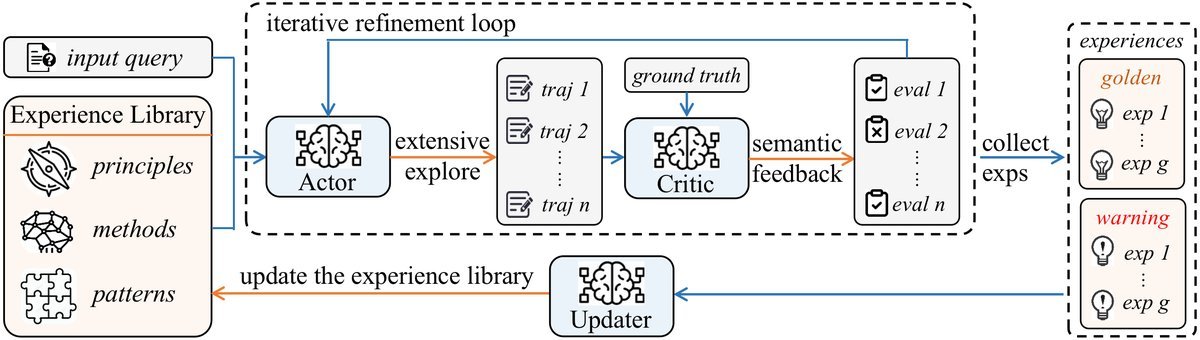
Lower-level MDP: frontline exploration and experience distillation
This can be seen as the “frontline combat unit.” It consists of an Actor and a Critic.
-
The Actor is responsible for generating concrete steps to solve the problem.
-
The Critic evaluates the Actor’s plan. If it fails, it analyzes the reason for failure and provides “semantic feedback” — improvement suggestions in natural language — to guide the Actor’s next attempt.
This “try-feedback-correct” loop is the process by which experience is generated. Both successful paths and lessons from failure are recorded.
Upper-level MDP: global scheduling and experience evolution
This is equivalent to the “headquarters.” It is responsible for maintaining a global, hierarchical experience library.
-
Hierarchical structure: The library is cleverly organized into three layers: high-level strategic principles, mid-level reasoning patterns, and low-level concrete cases.
-
Two-zone design: It is also divided into a “golden zone” for successful experience and a “warning zone” for failure lessons, enabling learning from both positive and negative outcomes.
When the lower-level exploration unit submits new experience, the “updater” Agent decides whether to add, merge, or discard it, ensuring the library remains efficient and free of redundancy.
When solving new problems, the Agent can retrieve contextually relevant information from this library just like consulting reference materials, thereby gaining powerful external knowledge support.
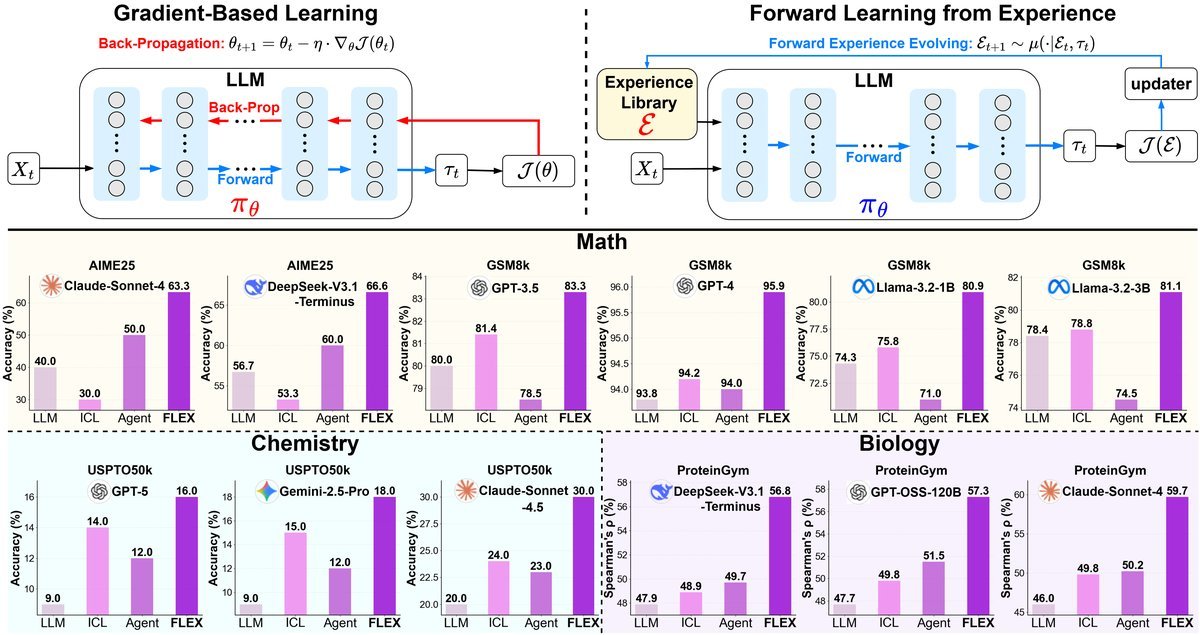
Practical results: significant gains across domains
No matter how good the theory is, the proof is in the results. FLEX achieved remarkable outcomes on challenging tasks in mathematics, chemistry, and biology.
| Model | Benchmark | Vanilla | ICL | Agent | FLEX (this paper) |
|---|---|---|---|---|---|
| Claude-Sonnet-4 | AIME25 | 40.0 | - | 42.0 | 63.3 (+23.3) |
| GPT-4 | GSM8k | 93.4 | 92.5 | 95.3 | 95.9 (+0.6) |
| Claude-Sonnet-4.5 | USPTO50k | 20.0 | 20.0 | 20.0 | 30.0 (+10.0) |
| GenAI-FLEX-128k | ProteinGym | 0.460 | - | 0.460 | 0.602 (+0.142) |
-
Mathematical reasoning: On the highly challenging AIME25 math competition dataset, FLEX learned from just 49 examples and boosted Claude-Sonnet-4’s accuracy from 40.0%** to 63.3%, achieving an astonishing **23.3% absolute performance gain.
-
Chemical synthesis: On the specialized USPTO50k retrosynthesis task, general-purpose large models perform poorly. By learning from 50 examples, FLEX raised Claude-Sonnet-4.5’s accuracy from 20% to 30%, effectively doubling the result.
-
Biological prediction: On the ProteinGym protein fitness prediction task, FLEX also performed strongly, improving the model’s prediction correlation from 0.46 to 0.602, a 14.2% gain.
In addition, the study found a clear Scaling Law of Experience between Agent performance and the size of the experience library, and showed that the experience library can be inherited across different models (Experience Inheritance), enabling rapid knowledge transfer.
Conclusion
The FLEX paradigm paints an exciting future: AI Agents are no longer static tools frozen at the factory, but dynamic partners that can keep learning, reflecting, and growing through practice, just like intelligent beings.
By shifting the core of learning from parameter adjustment to experience building, FLEX opens up an efficient, low-cost, and interpretable path for Agent evolution, marking a solid step toward scalable, inheritable, continuously evolving intelligent Agents.