First Try Matters: Revisiting the Role of Reflection in Reasoning Models
-
ArXiv URL: http://arxiv.org/abs/2510.08308v1
-
Authors: Zhanfeng Mo; Yao Xiao; Yue Deng; Wee Sun Lee; Lidong Bing; Liwei Kang
-
Publishing Institutions: MiroMind AI; National University of Singapore; Singapore University of Technology and Design
TL;DR
This paper reveals through large-scale quantitative analysis that the “reflection” step in current reasoning models mainly serves a confirmatory role rather than a corrective one. Performance gains come from higher first-attempt accuracy, and based on this finding, the paper proposes an early-stopping strategy that can significantly improve reasoning efficiency.
Key Definitions
The core analysis in this paper is built on a redefinition and quantification of “reflection,” using the following key concepts:
- Reflection: In a reasoning process (rollout), all subsequent reasoning steps the model continues to perform after generating the first candidate answer. This definition clearly divides the reasoning process into “forward reasoning” (up to the first candidate answer) and “reflective reasoning” (after the first candidate answer).
- Confirmatory Reflection: When, during reflection, the subsequently generated candidate answers remain consistent with the previous answer or do not change in correctness (for example, from correct to correct T→T, or from the same wrong answer to the same wrong answer F→F (same)), this reflection is considered confirmatory.
- Corrective Reflection: When, during reflection, the model successfully corrects an incorrect candidate answer into a correct one (that is, an F→T transition), this reflection is considered corrective.
Related Work
Current state-of-the-art large language models (LLMs), especially reasoning models trained with reinforcement learning from verifiable rewards (RLVR), demonstrate strong reasoning capabilities. This is usually attributed to their ability to generate longer Chain-of-Thought (CoT) and perform so-called “reflective reasoning” — that is, after arriving at an initial answer, they continue to examine, evaluate, and revise their own reasoning path. The prevailing view in the field is that this reflection is the key mechanism by which models achieve self-correction and improve final answer accuracy.
However, existing research has not reached a consensus on the true role of reflection. Some studies argue that the reflection mechanism is complex and can prevent reasoning collapse, while others believe that reflection patterns are often superficial and do not improve outcomes. The key bottleneck in these studies is the lack of large-scale, systematic quantitative analysis of reflection behavior in reasoning models.
This paper aims to address this core question: Are the reflection steps in reasoning models actually performing effective self-correction, or are they merely confirming existing conclusions?
Method
This paper first designs an analytical framework to quantify reflection behavior, then investigates the role of reflection in training through controlled experiments, and finally proposes a method to improve reasoning efficiency based on the analysis results.
Quantitative Analysis of Reflection Behavior
To systematically study reflection, this paper designs an innovative analysis method.
- Core Method:
- Candidate Answer Extraction: The paper proposes an LLM-based candidate answer extractor. This extractor parses the model’s long CoT text and identifies all positions containing candidate answers.

- Reflection Type Classification: Based on the extracted candidate answer sequence ${a_1, a_2, …, a_n}$ and their correctness (True/False), the transition type between adjacent candidate answers is analyzed. For example, a transition from wrong to correct (F→T) is defined as “corrective reflection,” while a transition from correct to correct (T→T) or from the same wrong answer to the same wrong answer (F→F (same)) is defined as “confirmatory reflection.”
- Candidate Answer Extraction: The paper proposes an LLM-based candidate answer extractor. This extractor parses the model’s long CoT text and identifies all positions containing candidate answers.
- Innovations:
- Operational Definition and Quantification: For the first time, a clear and operational definition of “reflection” is provided (content after the first candidate answer), and automated tools are developed for large-scale quantitative analysis, turning the vague concept of “reflection” into measurable data.
- Decoupling Reasoning Stages: This method successfully decomposes the reasoning process into “forward reasoning” (generating the first answer) and “reflective reasoning,” allowing researchers to independently evaluate the contribution of each stage to final performance.
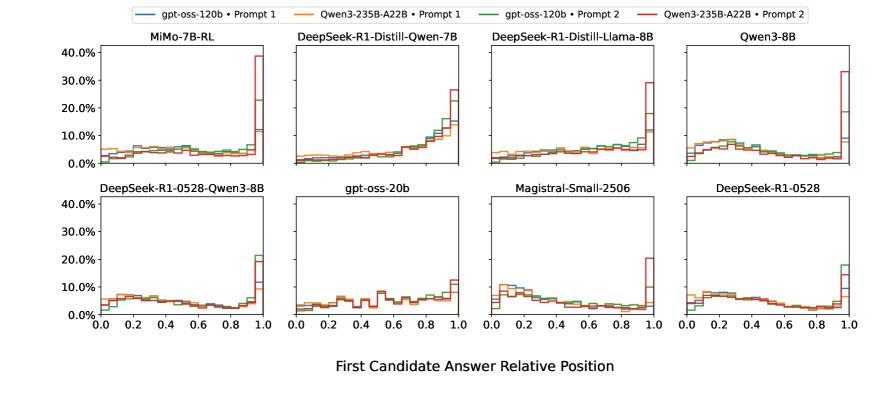
Investigating the Role of Reflection in Training
Based on the above analytical framework, this paper explores how the reflection characteristics in training data affect model performance through a series of supervised fine-tuning (SFT) experiments.
- Core Method:
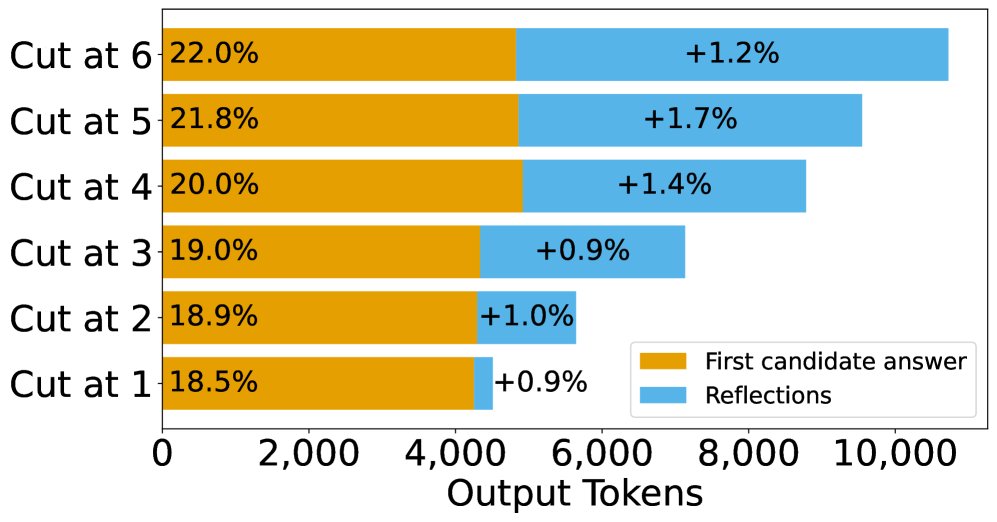
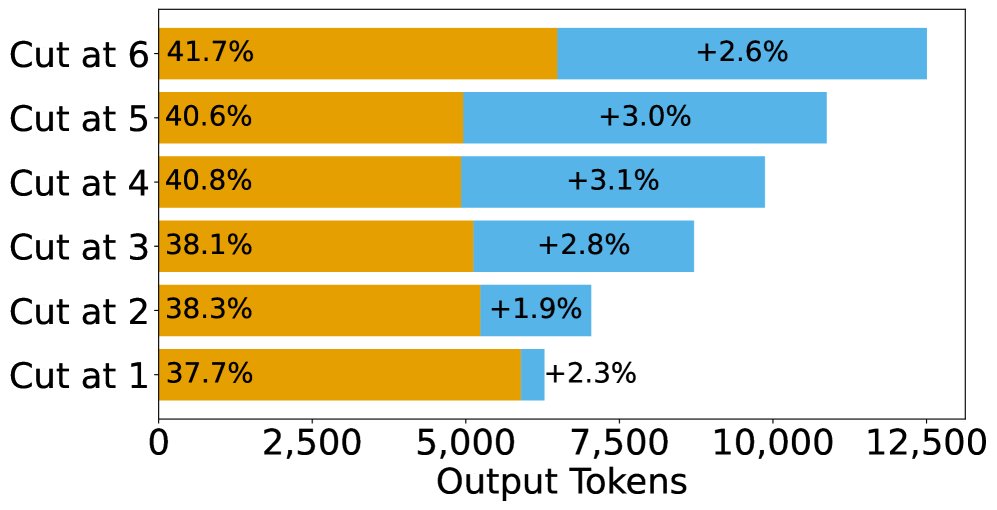
- Controlling the Number of Reflections: By truncating and continuing the original reasoning data, multiple training sets were carefully constructed. In these datasets, the number of “reflections” contained in each sample is controlled (for example, samples in the “cut-at-1” dataset are truncated after the first candidate answer, while “cut-at-6” is truncated after the sixth), while keeping the total number of training tokens roughly the same.
- Controlling the Reflection Type: Another series of training sets was constructed with different proportions of samples containing “corrective reflections” (F→T) and “confirmatory reflections” (T→T).
- Innovations:
- Controlled Experimental Design: Through a sophisticated dataset construction strategy, this paper is able to isolate and study in a controlled setting the impact of the “quantity” (how much) and “quality” (whether it corrects errors) of reflection on model learning, something previous studies had not achieved.
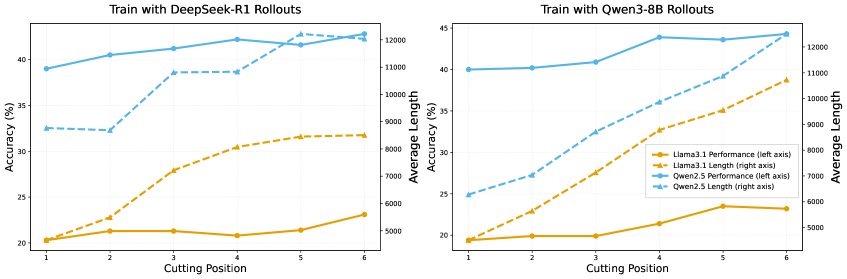
Early-Stopping Strategy for Efficient Reasoning
Based on the core finding that “reflection is mainly confirmatory,” this paper proposes a practical method to improve efficiency at inference time.
- Core Method: A Question-aware Adaptive Early-Stopping strategy is proposed.
- Candidate Answer Detector (CAD): Train a small model to monitor in real time during generation whether each sentence contains a candidate answer.
- Question-aware Reflection Controller (QRC): Train another small classifier that predicts, based only on the question itself, whether the question is likely to benefit from more reflection (that is, whether its original reasoning path contains an F→T corrective process).
- Reasoning Workflow: For a new question, QRC first judges its “reflection value.” If the value is low, the reasoning process is terminated immediately after CAD detects the first candidate answer; if the value is high, more rounds of reflection are allowed (for example, terminating after the third candidate answer), thereby dynamically balancing accuracy and token consumption.
- Innovations:
- Analysis-driven Optimization: This method is a prime example of directly translating the analytical findings above into practical application. Rather than blindly cutting all reflection, it uses QRC to adaptively preserve a reflection budget for difficult problems that may require correction.
- Advantages: This strategy significantly reduces unnecessary reasoning token consumption while, through adaptive control, minimizing the negative impact on model performance, achieving a flexible trade-off between cost and effectiveness.
Experimental Conclusions
Reflection Behavior Analysis
- Reflection is mainly confirmatory, with very little error correction: Analysis of 8 mainstream reasoning models across 5 math datasets shows that more than 90% of reflections are “confirmatory.” Reflections that truly correct errors (F→T) account for an extremely small share, usually less than 2%. This suggests that once a model produces an answer, later steps rarely overturn it.
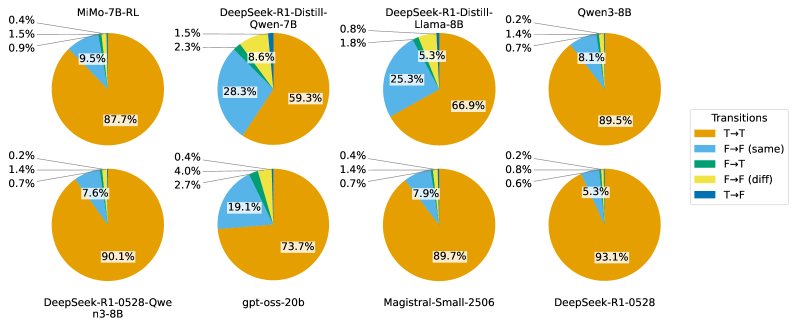
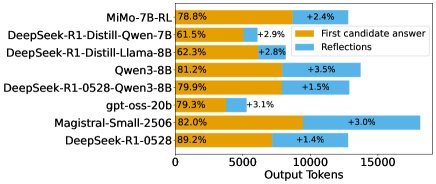
- Performance gains mainly come from the first attempt: Although the reflection part consumes a large number of tokens (16.8% to 47.8% of the total), the accuracy improvement it brings is very limited (only 1.4% to 3.5%). Final accuracy is highly correlated with the correctness of the first candidate answer, indicating that “getting it right on the first try” is the key driver of performance.
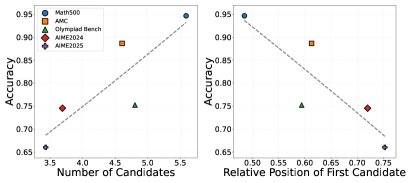
- Reflection behavior is mismatched with task difficulty: A counterintuitive finding is that on harder datasets (such as AIME), models tend to spend more tokens on forward reasoning, causing the first candidate answer to appear later (with less reflection); while on simpler datasets (such as Math500), models instead give answers earlier and perform more reflection. This suggests that current models’ reflection mechanisms are not effectively aligned with task difficulty.
Training experiment conclusions
- Training with more reflections can improve performance, but the mechanism is strengthening the first attempt: Experiments show that SFT training with data containing more reflection steps does indeed improve the model’s final accuracy. However, analyzing the source of the performance gain reveals that this improvement mainly comes from a significant increase in “first-attempt correctness” (an average gain of 3.75%), while the error-correction ability in the reflection stage changes almost not at all (only 0.3%).
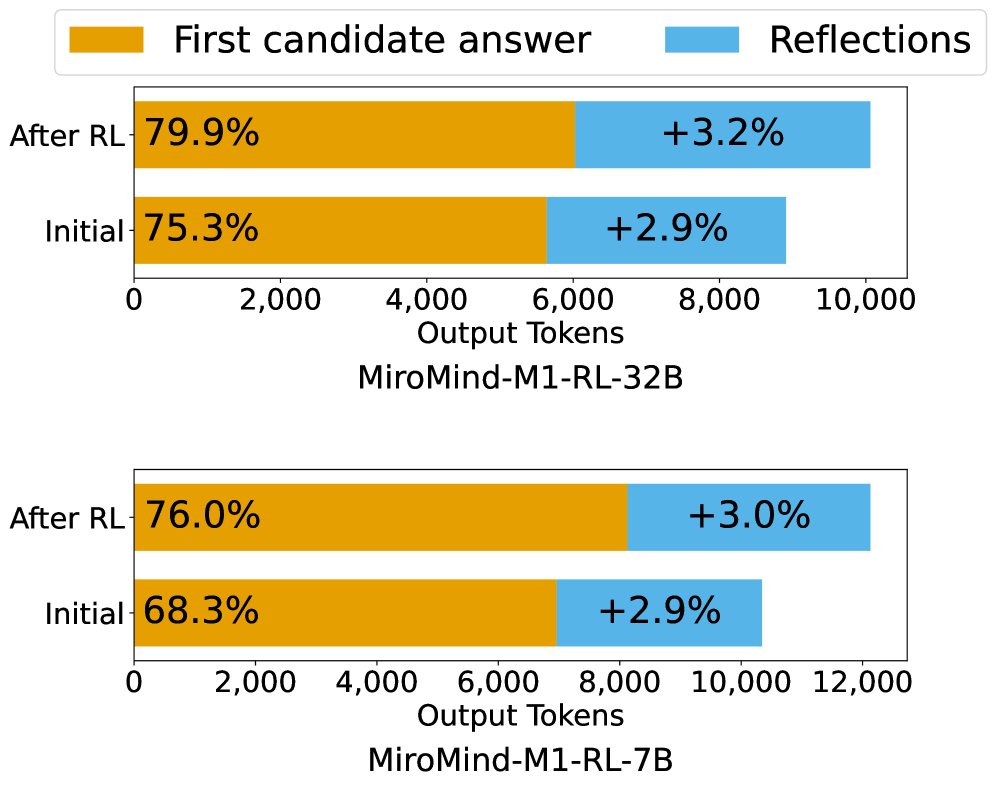
- RL training follows the same pattern: Comparing models before and after RL training shows that the performance gains also mainly come from improved first-attempt correctness, rather than stronger reflection-based error correction.
- Training on corrective reflection samples is ineffective: Adding more “corrective reflection” (F→T) samples to the training data does not significantly improve the model’s error-correction ability or overall performance. This further supports the idea that models seem unable to learn general self-correction ability from imitating correction trajectories.
| Model | F→T Ratio | Average Tokens | Accuracy (%) | P(F→T) (%) |
|---|---|---|---|---|
| Llama3.1-8B-Instruct | 0% | 7618 | 49.3 | 2.1 |
| 25% | 7512 | 48.7 | 2.2 | |
| 50% | 7612 | 49.2 | 2.0 | |
| 75% | 7500 | 48.2 | 1.8 | |
| 100% | 7417 | 47.6 | 1.8 | |
| Qwen2.5-7B-Instruct | 0% | 8391 | 54.4 | 1.9 |
| 25% | 8345 | 54.0 | 2.1 | |
| 50% | 8452 | 53.9 | 2.0 | |
| 75% | 8711 | 55.1 | 1.8 | |
| 100% | 8421 | 53.4 | 1.9 |
Final conclusion
This systematic analysis overturns the common view that “reflection equals error correction.” The study shows that in current reasoning models, the core value of long-form reasoning lies in enhancing the model’s ability to “get it right on the first try” through the presentation of diverse reasoning paths, rather than in effective self-correction after making mistakes. Based on this insight, the question-aware early termination strategy proposed in this paper demonstrates that it is entirely feasible to greatly improve reasoning efficiency with almost no sacrifice in core reasoning ability. This points to a new direction for the design and optimization of future reasoning models: rather than pinning hopes on complex reflective error correction, it is better to focus on improving the accuracy and robustness of the model’s first reasoning attempt.