ELPO: Ensemble Learning Based Prompt Optimization for Large Language Models
Say Goodbye to Mystical Prompting! ByteDance’s ELPO Framework Boosts F1 by Up to 7.6 Points

When working with large language models (LLM), we always run into a frustrating problem: model performance is extremely sensitive to the prompt.
ArXiv URL:http://arxiv.org/abs/2511.16122v1
Change a synonym or tweak the word order, and the result can be dramatically different. This gave rise to the craft of “prompt engineering,” but it also trapped countless developers in a cycle of repeated trial and error.
To escape this “alchemy-like” predicament, Automatic Prompt Optimization (APO) emerged. However, most existing methods rely on a single algorithm, like a repairman with only one hammer, often struggling when faced with complex problems.
Now, researchers from ByteDance and the University of Hong Kong have proposed a brand-new framework—ELPO—which cleverly introduces the idea of ensemble learning into prompt optimization, taking both performance and stability to a new level.
The Bottleneck of Single Methods
Have you ever wondered why no APO method can come out on top across all tasks?
Behind this lies the “no free lunch” theorem in optimization: no single strategy can perfectly solve every problem.
Existing methods, whether based on evolutionary algorithms or feedback-driven approaches, are like walking a tightrope. They may perform well on specific tasks, but once the scenario changes, they can quickly become ineffective, and they are also prone to getting stuck in local optima, failing to find the truly best prompt.
As shown below, traditional methods usually follow a single generation and search path, lacking flexibility.
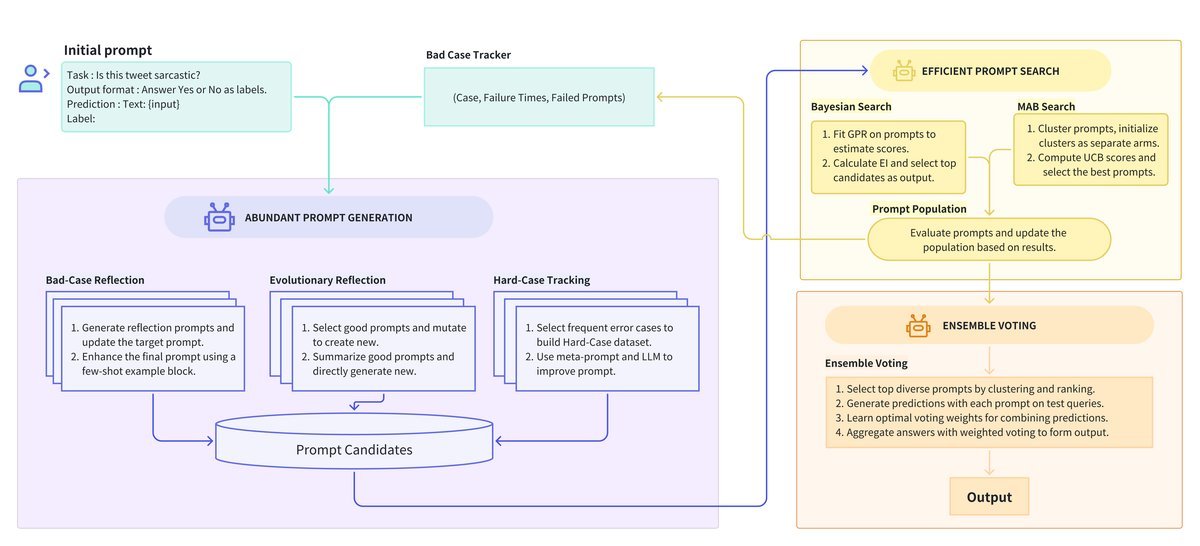
ELPO, by contrast, is like a “think tank.” It does not bet on any single strategy; instead, it pools ideas from multiple angles to perform optimization, resulting in a more comprehensive and robust solution.
One of ELPO’s Combos: Rich Prompt Generation
A high-quality pool of candidate prompts is the foundation of optimization.
ELPO does not use a single generation strategy. Instead, it designs a “three-horse carriage” generator ensemble to ensure that candidate prompts are not only numerous and high-quality, but also diverse.
These three strategies are:
-
Bad-Case Reflection: Analyze samples where predictions failed, reflect on the shortcomings of the current prompt, and generate improved versions.
-
Evolutionary Reflection: Simulate biological evolution by “crossbreeding” and “mutating” well-performing prompts to create new, strong offspring.
-
Hard-Case Tracking: This is one of ELPO’s major innovations! It continuously tracks those “stubborn” samples that repeatedly cause errors, combines them with the prompts that led to failure for in-depth analysis, and thereby generates instructions with stronger generalization ability.
In this way, ELPO builds an exceptionally rich candidate pool, laying a solid foundation for subsequent selection.
Another of ELPO’s Combos: Efficient Prompt Search
With a large number of candidate prompts in hand, the next question naturally arises: how can we efficiently identify the best ones?
If every prompt were evaluated on the full validation set, the computational cost would be astronomical.
To address this, ELPO creatively introduces an intelligent screening mechanism based on Bayesian Search and Multi-Armed Bandit (MAB).
-
Bayesian Search: It maps prompts into a high-dimensional space and predicts the potential of unevaluated prompts by assessing the performance of a small subset of prompts.
-
MAB: It acts like a shrewd gambler, balancing “exploration” (trying new prompts) and “exploitation” (evaluating known good prompts) to quickly lock onto the most promising candidates with minimal resources.

Figure caption: ELPO’s search strategy shows superior efficiency
This combination greatly reduces evaluation costs, making large-scale prompt optimization computationally feasible.
ELPO’s Third Combo: Robust Ensemble Voting
In complex real-world tasks, relying on a single “best” prompt is often not robust enough.
ELPO’s final step is Ensemble Voting. Rather than simply selecting the highest-scoring prompt, it chooses a set of high-performing and structurally diverse prompts to form an “expert committee.”
During final inference, this committee makes decisions through weighted voting:
\[\hat{y}(x)=\arg\max_{y\in\mathcal{Y}}\sum_{j=1}^{M}w_{j}\cdot\mathbb{I}\{f_{j}(x)=y\}\]Here, $w_j$ is the weight of the $j$-th prompt. This approach effectively reduces the bias that may exist in any single prompt, significantly improving the model’s generalization ability and the accuracy of the final result.
Experimental Results: A Comprehensive SOTA Overrun
How effective is ELPO’s “combo”? The experimental results give a resounding answer.
The researchers conducted extensive tests on 6 datasets covering yes-no questions, generation tasks, and multiple-choice questions, using Doubao-pro and GPT-4o as the models.

The results show that ELPO consistently outperforms all SOTA methods, including APE, OPRO, and Promptbreeder, across all tasks.
-
On the ArSarcasm dataset, ELPO improved the F1 score by 7.6 points.
-
On the BBH-navigate dataset, the F1 score improved by 9.2 points.
-
On the more challenging GSM8K mathematical reasoning task, accuracy also reached an astonishing 96.0.
Ablation studies further confirmed that every component of ELPO—diverse generators, an efficient search framework, and the ensemble voting strategy—made an indispensable contribution to the final outstanding performance.
Conclusion and Outlook
By incorporating the idea of ensemble learning, the ELPO framework successfully addresses the stability and efficiency bottlenecks in automatic prompt optimization. Through diverse generation strategies, an efficient search mechanism, and robust ensemble voting, it provides us with a more powerful and reliable methodology for LLM applications.
Of course, the study also points out some future directions, such as introducing more diverse generation strategies (e.g., human feedback) and further improving the robustness of the search algorithm.
In short, the emergence of ELPO brings us one step closer to a future where we can communicate with AI as smoothly as silk. It proves that we can move beyond “mystical tuning” and follow a clear path forward.